 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-aspect Multilingual and Cross-lingual Parliamentary Speech Analysis
Jul 03, 2022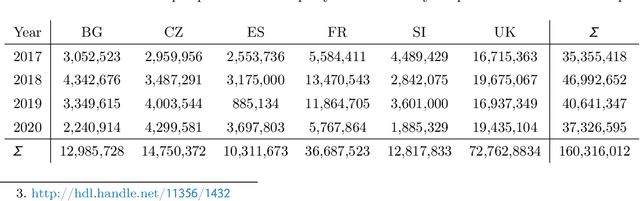
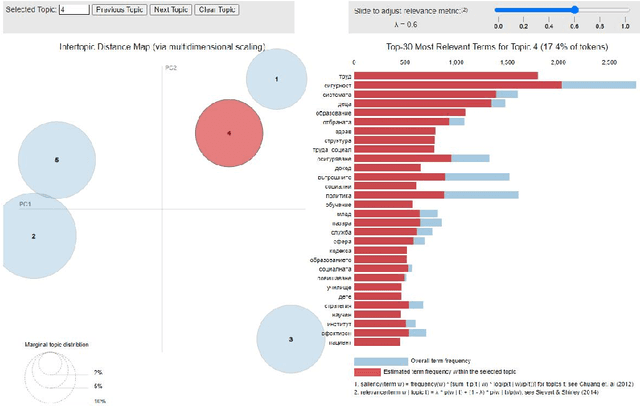
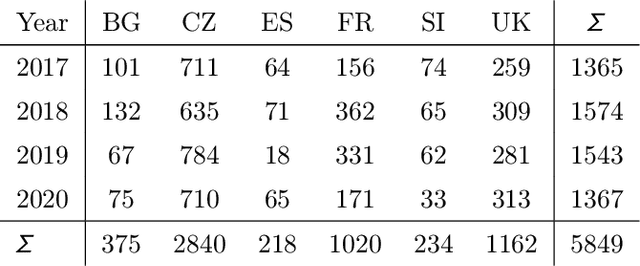
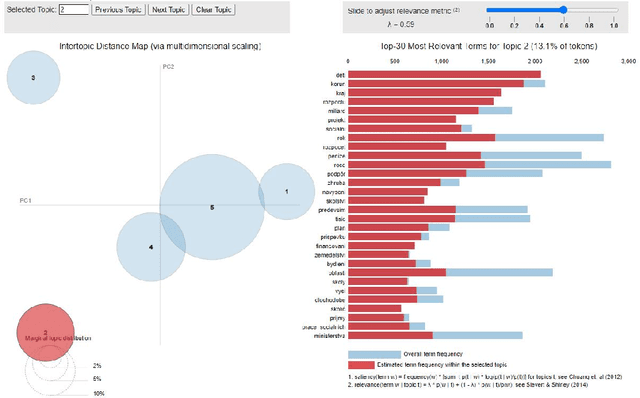
Parliamentary and legislative debate transcripts provide an exciting insight into elected politicians' opinions, positions, and policy preferences. They are interesting for political and social sciences as well as linguistics and natural language processing (NLP). Exiting research covers discussions within individual parliaments. In contrast, we apply advanced NLP methods to a joint and comparative analysis of six national parliaments (Bulgarian, Czech, French, Slovene, Spanish, and United Kingdom) between 2017 and 2020, whose transcripts are a part of the ParlaMint dataset collection. Using a uniform methodology, we analyze topics discussed, emotions, and sentiment. We assess if the age, gender, and political orientation of speakers can be detected from speeches. The results show some commonalities and many surprising differences among the analyzed countries.
Bayesian Methods for Semi-supervised Text Annotation
Oct 28, 2020
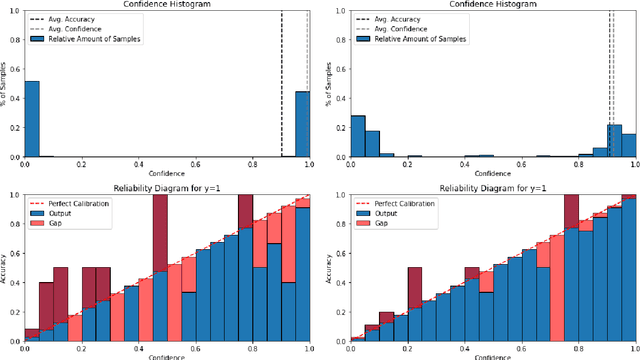
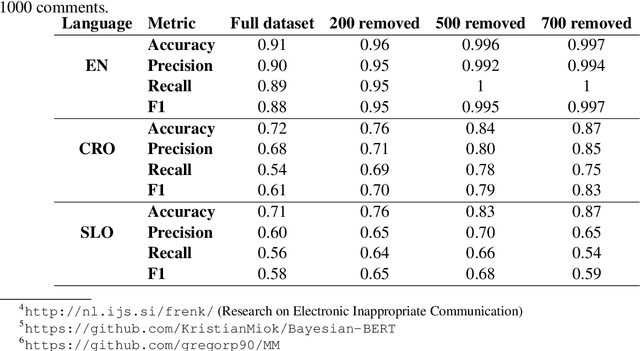

Human annotations are an important source of information in the development of natural language understanding approaches. As under the pressure of productivity annotators can assign different labels to a given text, the quality of produced annotations frequently varies. This is especially the case if decisions are difficult, with high cognitive load, requires awareness of broader context, or careful consideration of background knowledge. To alleviate the problem, we propose two semi-supervised methods to guide the annotation process: a Bayesian deep learning model and a Bayesian ensemble method. Using a Bayesian deep learning method, we can discover annotations that cannot be trusted and might require reannotation. A recently proposed Bayesian ensemble method helps us to combine the annotators' labels with predictions of trained models. According to the results obtained from three hate speech detection experiments, the proposed Bayesian methods can improve the annotations and prediction performance of BERT models.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 16, 2020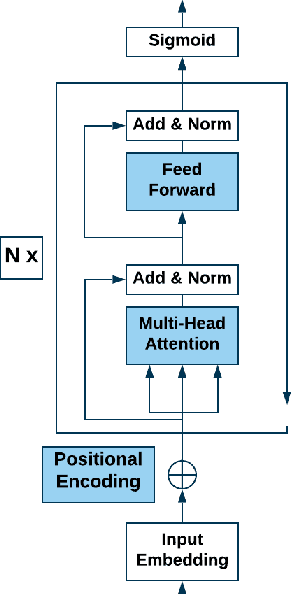

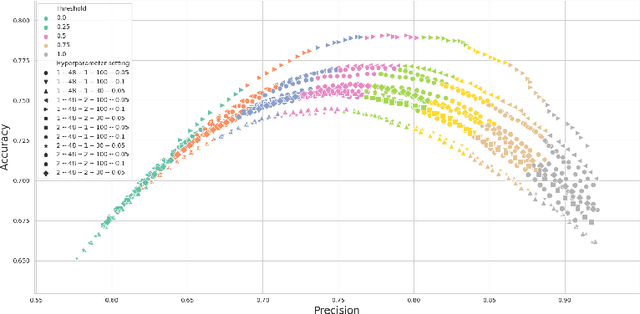
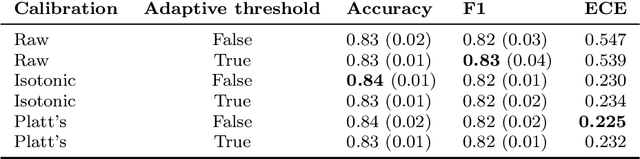
Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
Cross-lingual Transfer of Twitter Sentiment Models Using a Common Vector Space
May 18, 2020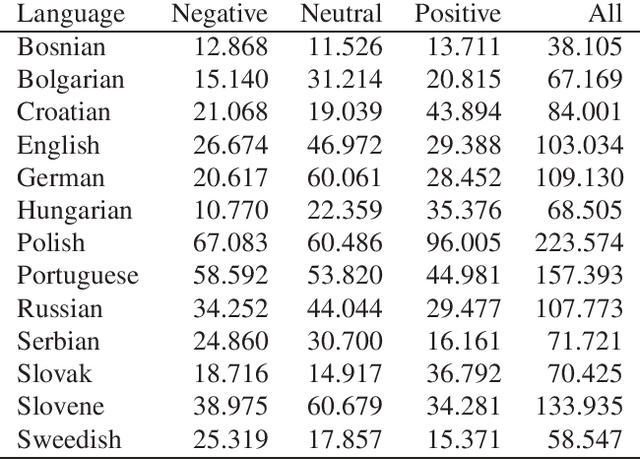
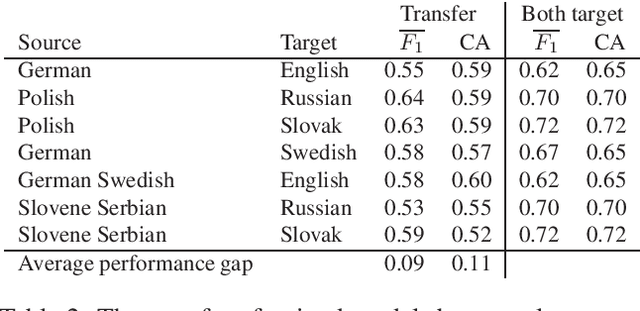
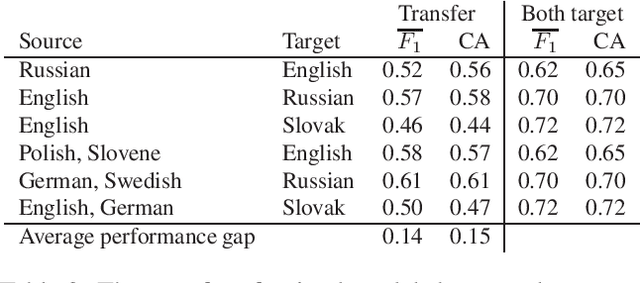
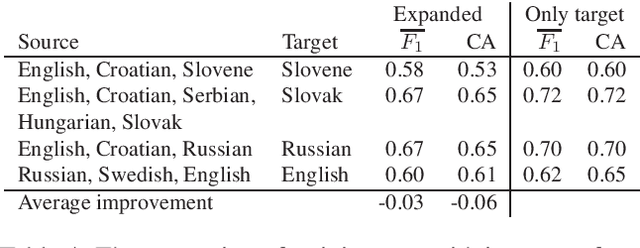
Word embeddings represent words in a numeric space in such a way that semantic relations between words are encoded as distances and directions in the vector space. Cross-lingual word embeddings map words from one language to the vector space of another language, or words from multiple languages to the same vector space where similar words are aligned. Cross-lingual embeddings can be used to transfer machine learning models between languages and thereby compensate for insufficient data in less-resourced languages. We use cross-lingual word embeddings to transfer machine learning prediction models for Twitter sentiment between 13 languages. We focus on two transfer mechanisms using the joint numerical space for many languages as implemented in the LASER library: the transfer of trained models, and expansion of training sets with instances from other languages. Our experiments show that the transfer of models between similar languages is sensible, while dataset expansion did not increase the predictive performance.