 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoresActivation: A New Activation Function for Model Agnostic Global Explainability by Design
Nov 17, 2025Understanding the decision of large deep learning models is a critical challenge for building transparent and trustworthy systems. Although the current post hoc explanation methods offer valuable insights into feature importance, they are inherently disconnected from the model training process, limiting their faithfulness and utility. In this work, we introduce a novel differentiable approach to global explainability by design, integrating feature importance estimation directly into model training. Central to our method is the ScoresActivation function, a feature-ranking mechanism embedded within the learning pipeline. This integration enables models to prioritize features according to their contribution to predictive performance in a differentiable and end-to-end trainable manner. Evaluations across benchmark datasets show that our approach yields globally faithful, stable feature rankings aligned with SHAP values and ground-truth feature importance, while maintaining high predictive performance. Moreover, feature scoring is 150 times faster than the classical SHAP method, requiring only 2 seconds during training compared to SHAP's 300 seconds for feature ranking in the same configuration. Our method also improves classification accuracy by 11.24% with 10 features (5 relevant) and 29.33% with 16 features (5 relevant, 11 irrelevant), demonstrating robustness to irrelevant inputs. This work bridges the gap between model accuracy and interpretability, offering a scalable framework for inherently explainable machine learning.
Benchmarking that Matters: Rethinking Benchmarking for Practical Impact
Nov 15, 2025Benchmarking has driven scientific progress in Evolutionary Computation, yet current practices fall short of real-world needs. Widely used synthetic suites such as BBOB and CEC isolate algorithmic phenomena but poorly reflect the structure, constraints, and information limitations of continuous and mixed-integer optimization problems in practice. This disconnect leads to the misuse of benchmarking suites for competitions, automated algorithm selection, and industrial decision-making, despite these suites being designed for different purposes. We identify key gaps in current benchmarking practices and tooling, including limited availability of real-world-inspired problems, missing high-level features, and challenges in multi-objective and noisy settings. We propose a vision centered on curated real-world-inspired benchmarks, practitioner-accessible feature spaces and community-maintained performance databases. Real progress requires coordinated effort: A living benchmarking ecosystem that evolves with real-world insights and supports both scientific understanding and industrial use.
Patterns of Convergence and Bound Constraint Violation in Differential Evolution on SBOX-COST Benchmarking Suite
May 20, 2023This study investigates the influence of several bound constraint handling methods (BCHMs) on the search process specific to Differential Evolution (DE), with a focus on identifying similarities between BCHMs and grouping patterns with respect to the number of cases when a BCHM is activated. The empirical analysis is conducted on the SBOX-COST benchmarking test suite, where bound constraints are enforced on the problem domain. This analysis provides some insights that might be useful in designing adaptive strategies for handling such constraints.
The importance of being constrained: dealing with infeasible solutions in Differential Evolution and beyond
Mar 07, 2022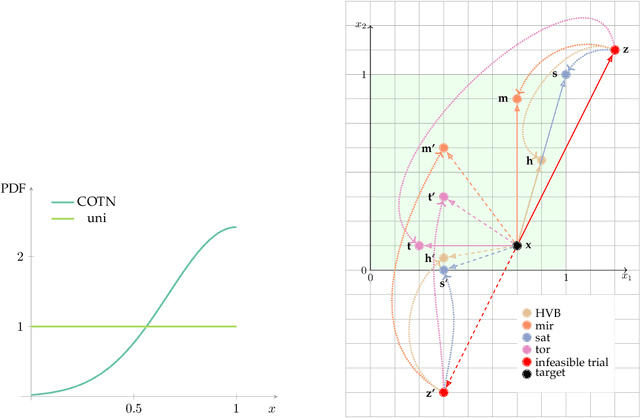

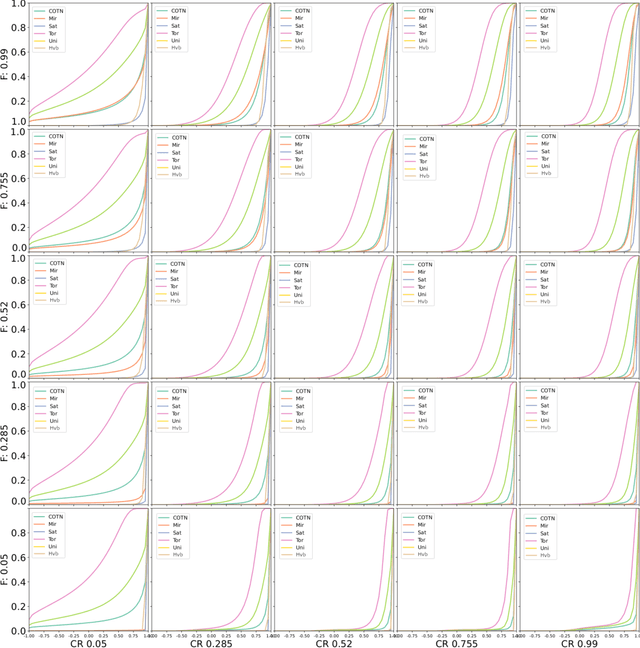
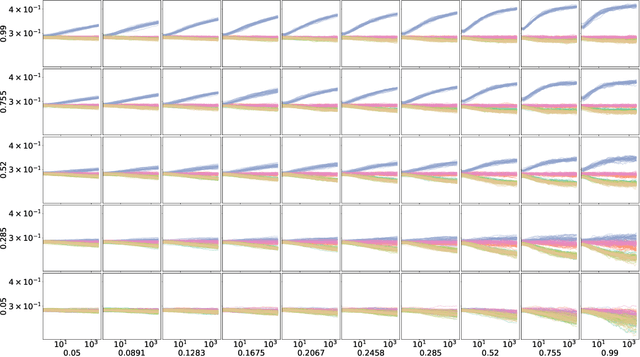
We argue that results produced by a heuristic optimisation algorithm cannot be considered reproducible unless the algorithm fully specifies what should be done with solutions generated outside the domain, even in the case of simple box constraints. Currently, in the field of heuristic optimisation, such specification is rarely mentioned or investigated due to the assumed triviality or insignificance of this question. Here, we demonstrate that, at least in algorithms based on Differential Evolution, this choice induces notably different behaviours - in terms of performance, disruptiveness and population diversity. This is shown theoretically (where possible) for standard Differential Evolution in the absence of selection pressure and experimentally for the standard and state-of-the-art Differential Evolution variants on special test function $f_0$ and BBOB benchmarking suite, respectively. Moreover, we demonstrate that the importance of this choice quickly grows with problem's dimensionality. Different Evolution is not at all special in this regard - there is no reason to presume that other heuristic optimisers are not equally affected by the aforementioned algorithmic choice. Thus, we urge the field of heuristic optimisation to formalise and adopt the idea of a new algorithmic component in heuristic optimisers, which we call here a strategy of dealing with infeasible solutions. This component needs to be consistently (a) specified in algorithmic descriptions to guarantee reproducibility of results, (b) studied to better understand its impact on algorithm's performance in a wider sense and (c) included in the (automatic) algorithmic design. All of these should be done even for problems with box constraints.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 16, 2020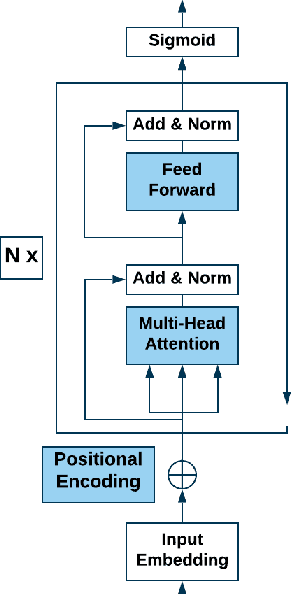

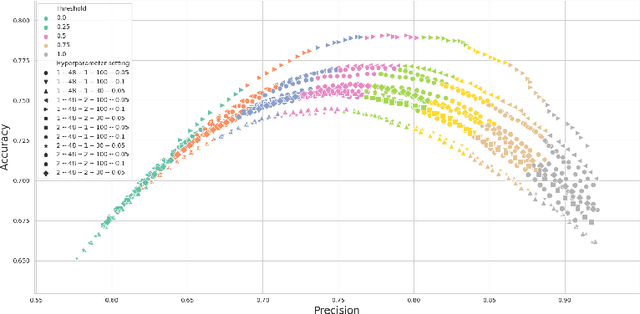
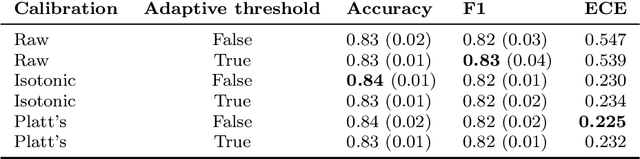
Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
Multiple Imputation for Biomedical Data using Monte Carlo Dropout Autoencoders
May 13, 2020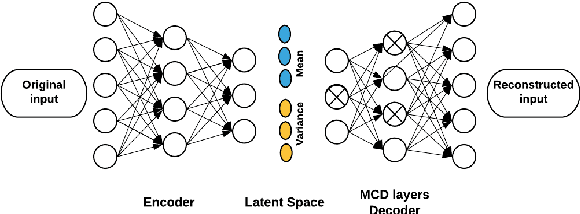
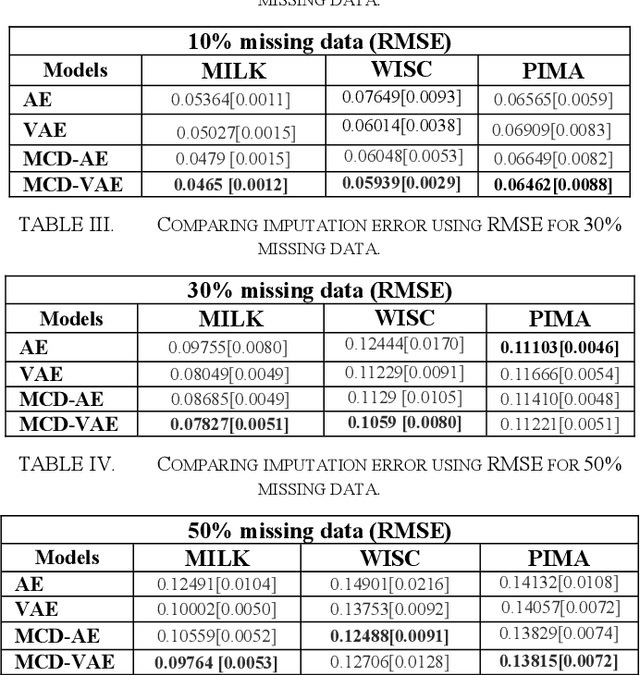
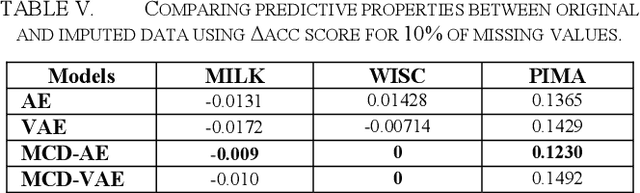
Due to complex experimental settings, missing values are common in biomedical data. To handle this issue, many methods have been proposed, from ignoring incomplete instances to various data imputation approaches. With the recent rise of deep neural networks, the field of missing data imputation has oriented towards modelling of the data distribution. This paper presents an approach based on Monte Carlo dropout within (Variational) Autoencoders which offers not only very good adaptation to the distribution of the data but also allows generation of new data, adapted to each specific instance. The evaluation shows that the imputation error and predictive similarity can be improved with the proposed approach.
Generating Data using Monte Carlo Dropout
Sep 16, 2019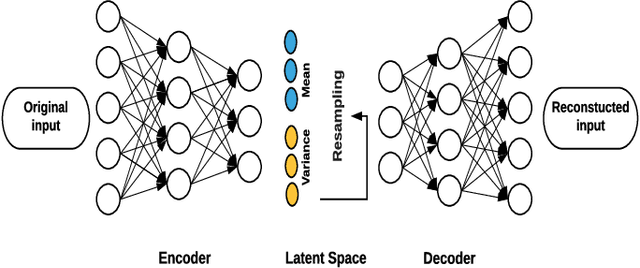
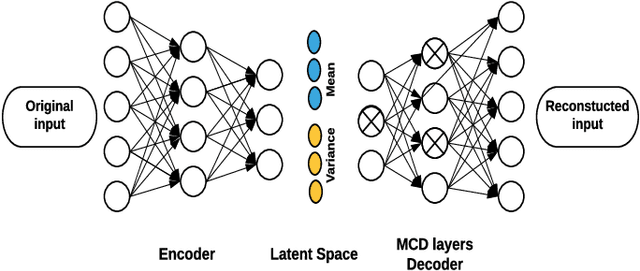
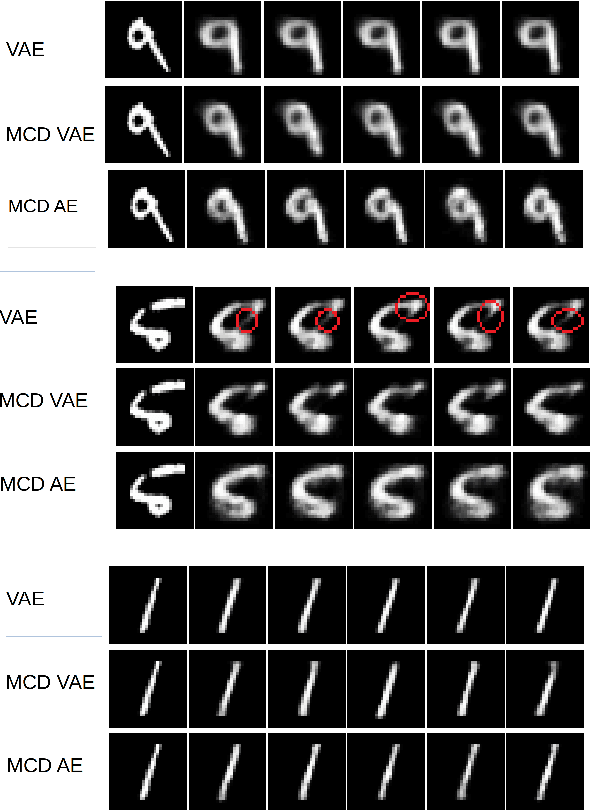

For many analytical problems the challenge is to handle huge amounts of available data. However, there are data science application areas where collecting information is difficult and costly, e.g., in the study of geological phenomena, rare diseases, faults in complex systems, insurance frauds, etc. In many such cases, generators of synthetic data with the same statistical and predictive properties as the actual data allow efficient simulations and development of tools and applications. In this work, we propose the incorporation of Monte Carlo Dropout method within Autoencoder (MCD-AE) and Variational Autoencoder (MCD-VAE) as efficient generators of synthetic data sets. As the Variational Autoencoder (VAE) is one of the most popular generator techniques, we explore its similarities and differences to the proposed methods. We compare the generated data sets with the original data based on statistical properties, structural similarity, and predictive similarity. The results obtained show a strong similarity between the results of VAE, MCD-VAE and MCD-AE; however, the proposed methods are faster and can generate values similar to specific selected initial instances.
Prediction Uncertainty Estimation for Hate Speech Classification
Sep 16, 2019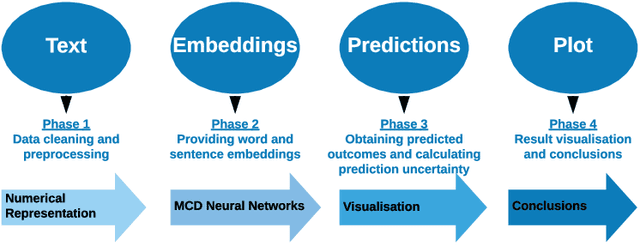
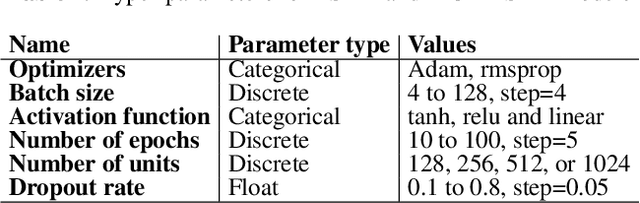
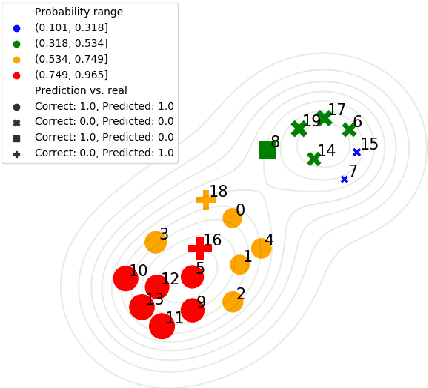
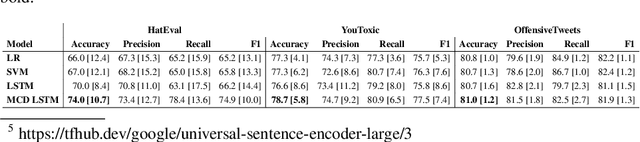
As a result of social network popularity, in recent years, hate speech phenomenon has significantly increased. Due to its harmful effect on minority groups as well as on large communities, there is a pressing need for hate speech detection and filtering. However, automatic approaches shall not jeopardize free speech, so they shall accompany their decisions with explanations and assessment of uncertainty. Thus, there is a need for predictive machine learning models that not only detect hate speech but also help users understand when texts cross the line and become unacceptable. The reliability of predictions is usually not addressed in text classification. We fill this gap by proposing the adaptation of deep neural networks that can efficiently estimate prediction uncertainty. To reliably detect hate speech, we use Monte Carlo dropout regularization, which mimics Bayesian inference within neural networks. We evaluate our approach using different text embedding methods. We visualize the reliability of results with a novel technique that aids in understanding the classification reliability and errors.