 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Imputation for Biomedical Data using Monte Carlo Dropout Autoencoders
May 13, 2020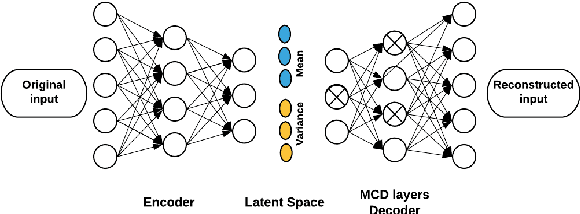
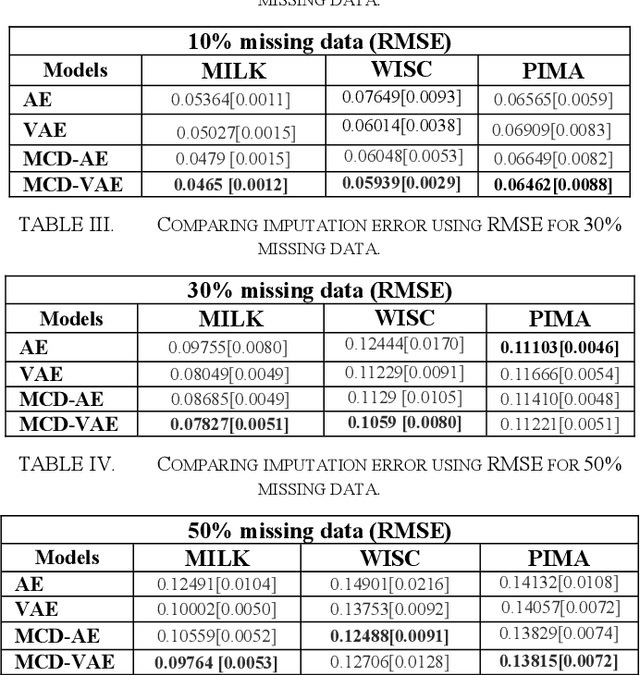
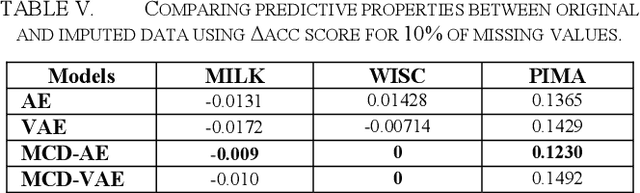
Due to complex experimental settings, missing values are common in biomedical data. To handle this issue, many methods have been proposed, from ignoring incomplete instances to various data imputation approaches. With the recent rise of deep neural networks, the field of missing data imputation has oriented towards modelling of the data distribution. This paper presents an approach based on Monte Carlo dropout within (Variational) Autoencoders which offers not only very good adaptation to the distribution of the data but also allows generation of new data, adapted to each specific instance. The evaluation shows that the imputation error and predictive similarity can be improved with the proposed approach.
Generating Data using Monte Carlo Dropout
Sep 16, 2019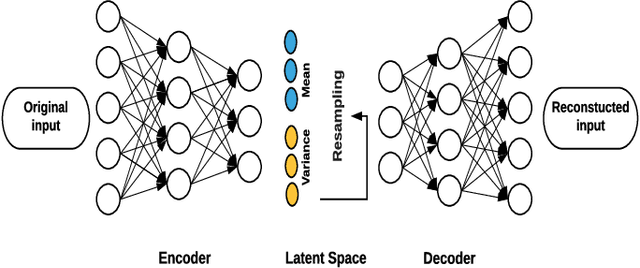
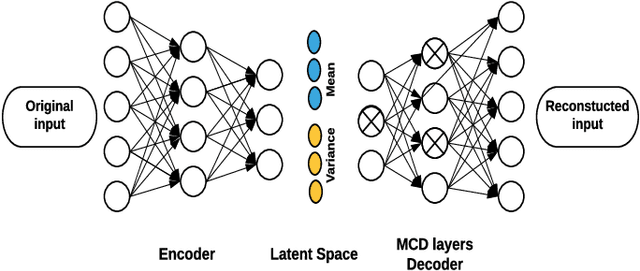
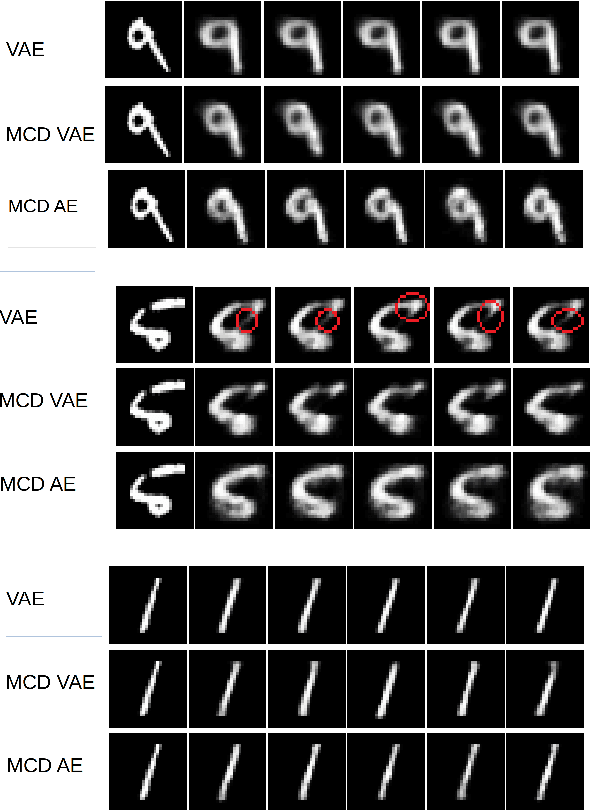

For many analytical problems the challenge is to handle huge amounts of available data. However, there are data science application areas where collecting information is difficult and costly, e.g., in the study of geological phenomena, rare diseases, faults in complex systems, insurance frauds, etc. In many such cases, generators of synthetic data with the same statistical and predictive properties as the actual data allow efficient simulations and development of tools and applications. In this work, we propose the incorporation of Monte Carlo Dropout method within Autoencoder (MCD-AE) and Variational Autoencoder (MCD-VAE) as efficient generators of synthetic data sets. As the Variational Autoencoder (VAE) is one of the most popular generator techniques, we explore its similarities and differences to the proposed methods. We compare the generated data sets with the original data based on statistical properties, structural similarity, and predictive similarity. The results obtained show a strong similarity between the results of VAE, MCD-VAE and MCD-AE; however, the proposed methods are faster and can generate values similar to specific selected initial instances.
Prediction Uncertainty Estimation for Hate Speech Classification
Sep 16, 2019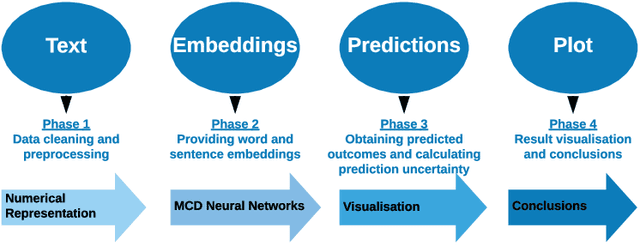
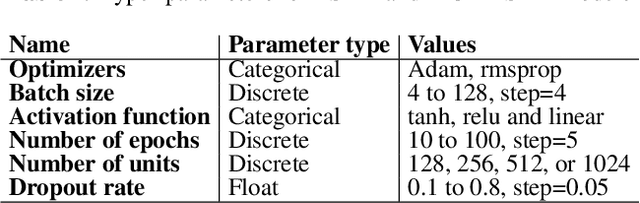
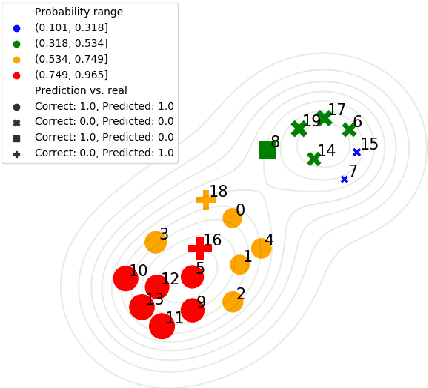
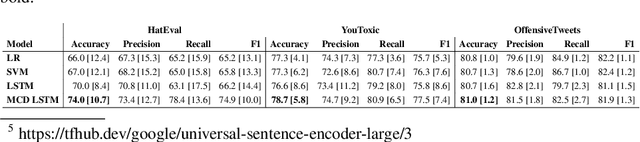
As a result of social network popularity, in recent years, hate speech phenomenon has significantly increased. Due to its harmful effect on minority groups as well as on large communities, there is a pressing need for hate speech detection and filtering. However, automatic approaches shall not jeopardize free speech, so they shall accompany their decisions with explanations and assessment of uncertainty. Thus, there is a need for predictive machine learning models that not only detect hate speech but also help users understand when texts cross the line and become unacceptable. The reliability of predictions is usually not addressed in text classification. We fill this gap by proposing the adaptation of deep neural networks that can efficiently estimate prediction uncertainty. To reliably detect hate speech, we use Monte Carlo dropout regularization, which mimics Bayesian inference within neural networks. We evaluate our approach using different text embedding methods. We visualize the reliability of results with a novel technique that aids in understanding the classification reliability and errors.