 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Explaining Pretrained Clinical Text Classifiers
May 27, 2026Explaining the predictions of neural models in clinical NLP remains a significant challenge, especially for complex tasks involving long, unstructured medical texts. While post-hoc methods like LIME and SHAP are widely used, they often fall short when applied to clinical narratives. In this paper, we identify core limitations of token-level and perturbation-based explanation techniques through targeted demonstra- tions on a hospital length-of-stay prediction task. Our findings reveal issues such as overemphasis on non-informative tokens, instability in at- tributions, and high-confidence predictions for incoherent input variants. These results underscore the need for explanation strategies that are clin- ically meaningful, semantically grounded, and robust to linguistic noise.
* 9 pages, 7 figures. Accepted at the First Workshop on Responsible Healthcare using Machine Learning (RHCML 2025), co-located with ECML PKDD 2025
Multi-aspect Multilingual and Cross-lingual Parliamentary Speech Analysis
Jul 03, 2022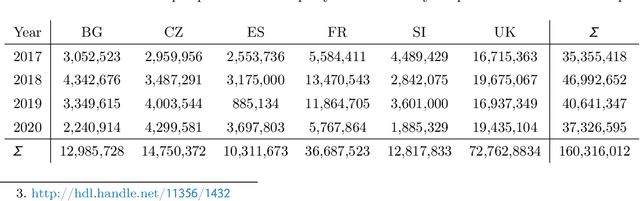
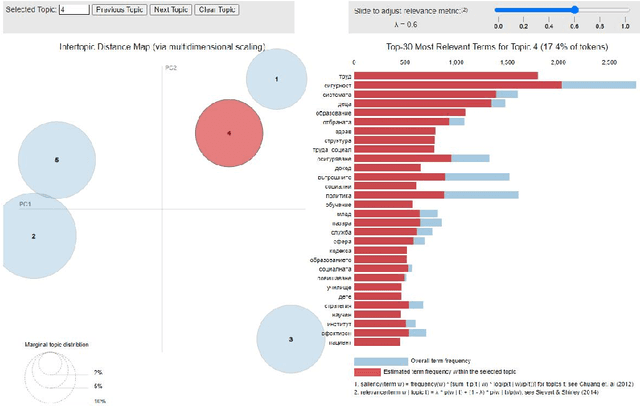
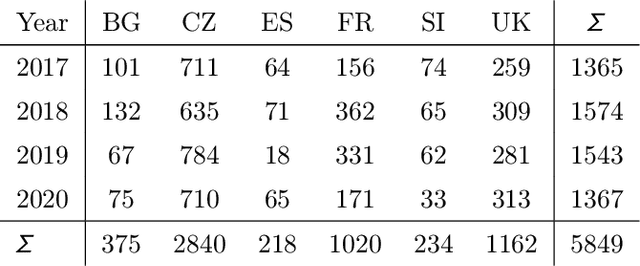
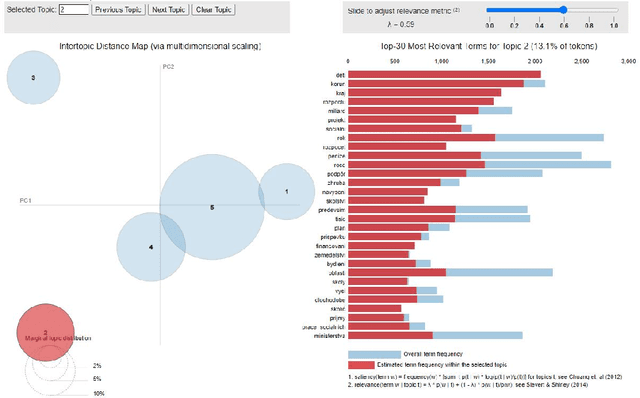
Parliamentary and legislative debate transcripts provide an exciting insight into elected politicians' opinions, positions, and policy preferences. They are interesting for political and social sciences as well as linguistics and natural language processing (NLP). Exiting research covers discussions within individual parliaments. In contrast, we apply advanced NLP methods to a joint and comparative analysis of six national parliaments (Bulgarian, Czech, French, Slovene, Spanish, and United Kingdom) between 2017 and 2020, whose transcripts are a part of the ParlaMint dataset collection. Using a uniform methodology, we analyze topics discussed, emotions, and sentiment. We assess if the age, gender, and political orientation of speakers can be detected from speeches. The results show some commonalities and many surprising differences among the analyzed countries.
Bayesian Methods for Semi-supervised Text Annotation
Oct 28, 2020
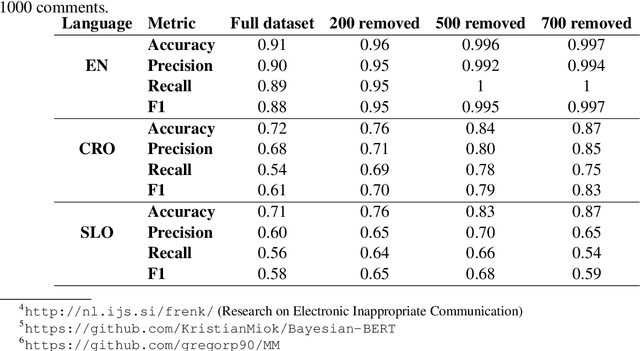

Human annotations are an important source of information in the development of natural language understanding approaches. As under the pressure of productivity annotators can assign different labels to a given text, the quality of produced annotations frequently varies. This is especially the case if decisions are difficult, with high cognitive load, requires awareness of broader context, or careful consideration of background knowledge. To alleviate the problem, we propose two semi-supervised methods to guide the annotation process: a Bayesian deep learning model and a Bayesian ensemble method. Using a Bayesian deep learning method, we can discover annotations that cannot be trusted and might require reannotation. A recently proposed Bayesian ensemble method helps us to combine the annotators' labels with predictions of trained models. According to the results obtained from three hate speech detection experiments, the proposed Bayesian methods can improve the annotations and prediction performance of BERT models.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 16, 2020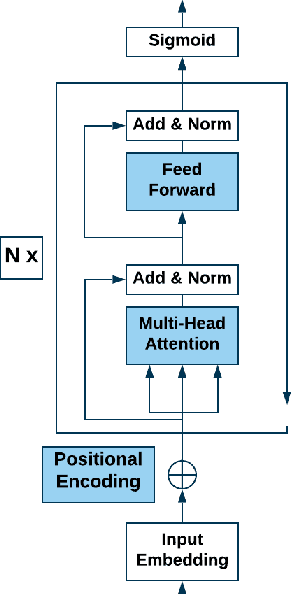

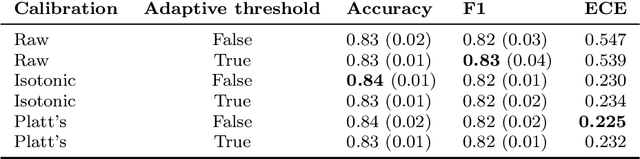
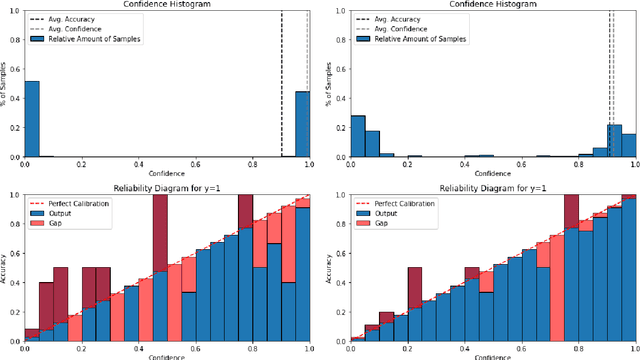
Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
Multiple Imputation for Biomedical Data using Monte Carlo Dropout Autoencoders
May 13, 2020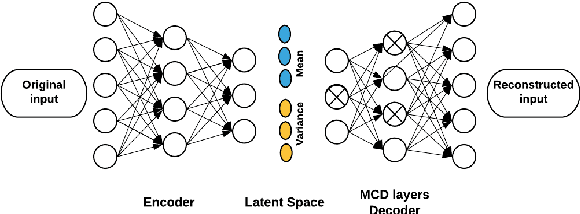
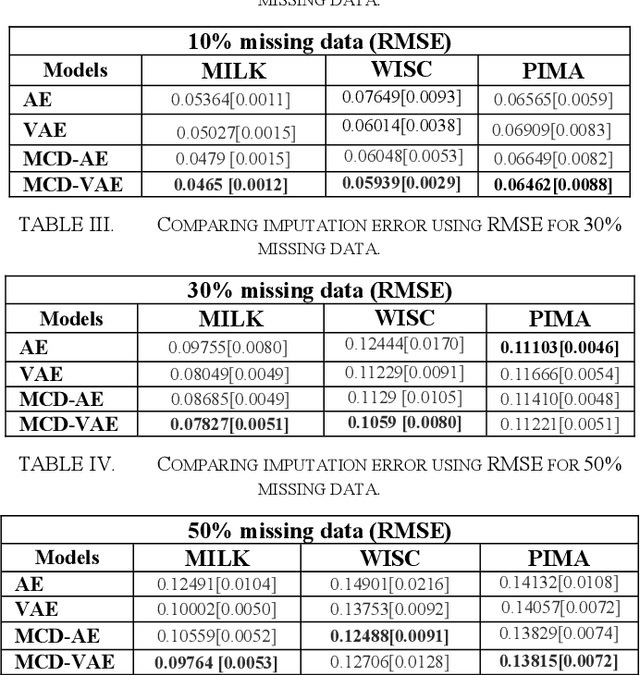
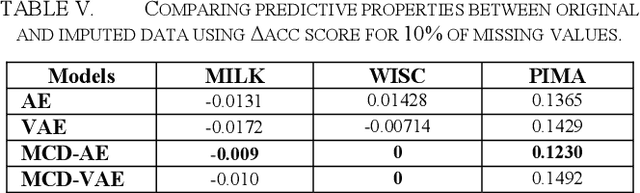
Due to complex experimental settings, missing values are common in biomedical data. To handle this issue, many methods have been proposed, from ignoring incomplete instances to various data imputation approaches. With the recent rise of deep neural networks, the field of missing data imputation has oriented towards modelling of the data distribution. This paper presents an approach based on Monte Carlo dropout within (Variational) Autoencoders which offers not only very good adaptation to the distribution of the data but also allows generation of new data, adapted to each specific instance. The evaluation shows that the imputation error and predictive similarity can be improved with the proposed approach.
Generating Data using Monte Carlo Dropout
Sep 16, 2019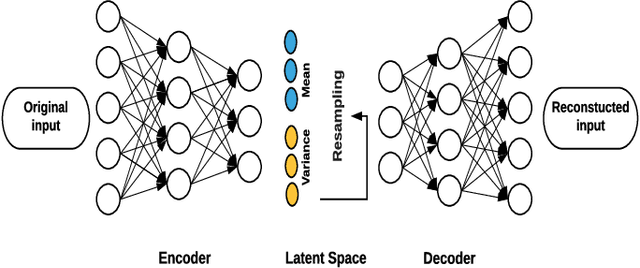
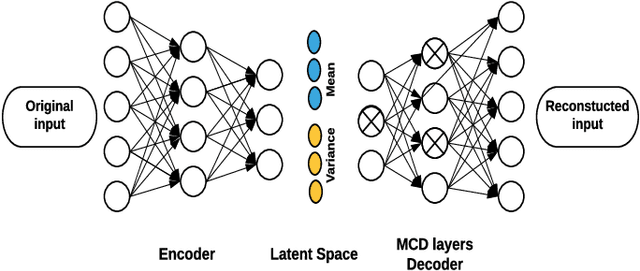
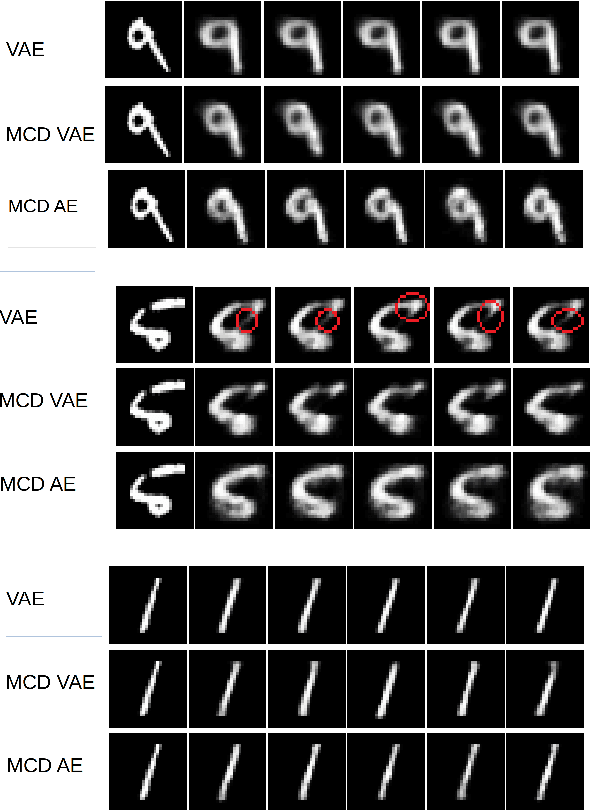

For many analytical problems the challenge is to handle huge amounts of available data. However, there are data science application areas where collecting information is difficult and costly, e.g., in the study of geological phenomena, rare diseases, faults in complex systems, insurance frauds, etc. In many such cases, generators of synthetic data with the same statistical and predictive properties as the actual data allow efficient simulations and development of tools and applications. In this work, we propose the incorporation of Monte Carlo Dropout method within Autoencoder (MCD-AE) and Variational Autoencoder (MCD-VAE) as efficient generators of synthetic data sets. As the Variational Autoencoder (VAE) is one of the most popular generator techniques, we explore its similarities and differences to the proposed methods. We compare the generated data sets with the original data based on statistical properties, structural similarity, and predictive similarity. The results obtained show a strong similarity between the results of VAE, MCD-VAE and MCD-AE; however, the proposed methods are faster and can generate values similar to specific selected initial instances.
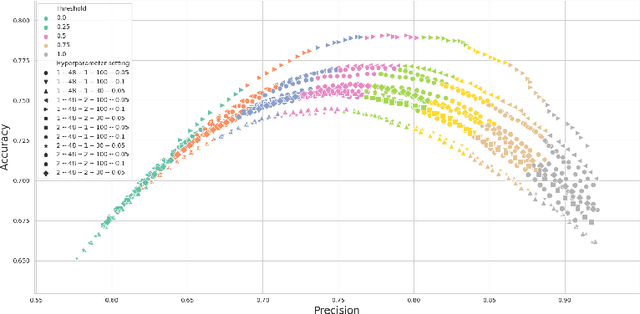
Prediction Uncertainty Estimation for Hate Speech Classification
Sep 16, 2019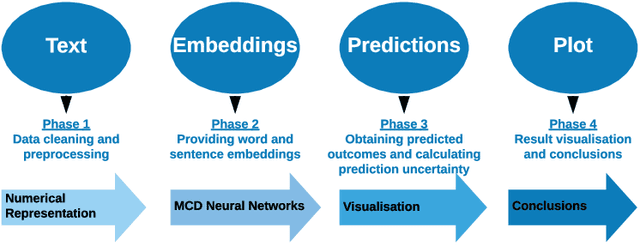
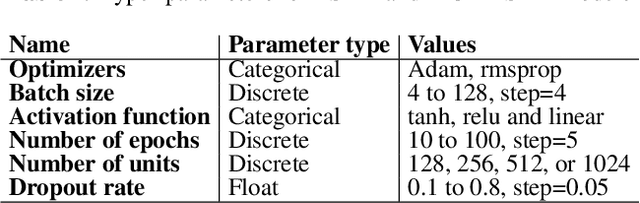
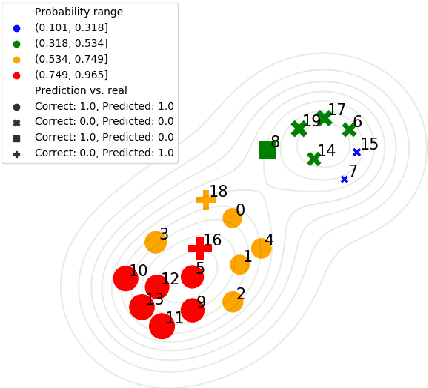
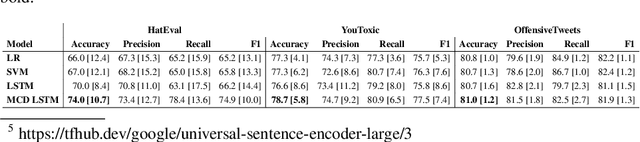
As a result of social network popularity, in recent years, hate speech phenomenon has significantly increased. Due to its harmful effect on minority groups as well as on large communities, there is a pressing need for hate speech detection and filtering. However, automatic approaches shall not jeopardize free speech, so they shall accompany their decisions with explanations and assessment of uncertainty. Thus, there is a need for predictive machine learning models that not only detect hate speech but also help users understand when texts cross the line and become unacceptable. The reliability of predictions is usually not addressed in text classification. We fill this gap by proposing the adaptation of deep neural networks that can efficiently estimate prediction uncertainty. To reliably detect hate speech, we use Monte Carlo dropout regularization, which mimics Bayesian inference within neural networks. We evaluate our approach using different text embedding methods. We visualize the reliability of results with a novel technique that aids in understanding the classification reliability and errors.