 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Temporal Frames Projection for Dynamic Processes Fusion in Fluorescence Microscopy
Jan 15, 2026Fluorescence microscopy is widely employed for the analysis of living biological samples; however, the utility of the resulting recordings is frequently constrained by noise, temporal variability, and inconsistent visualisation of signals that oscillate over time. We present a unique computational framework that integrates information from multiple time-resolved frames into a single high-quality image, while preserving the underlying biological content of the original video. We evaluate the proposed method through an extensive number of configurations (n = 111) and on a challenging dataset comprising dynamic, heterogeneous, and morphologically complex 2D monolayers of cardiac cells. Results show that our framework, which consists of a combination of explainable techniques from different computer vision application fields, is capable of generating composite images that preserve and enhance the quality and information of individual microscopy frames, yielding 44% average increase in cell count compared to previous methods. The proposed pipeline is applicable to other imaging domains that require the fusion of multi-temporal image stacks into high-quality 2D images, thereby facilitating annotation and downstream segmentation.
An investigation on the use of Large Language Models for hyperparameter tuning in Evolutionary Algorithms
Aug 05, 2024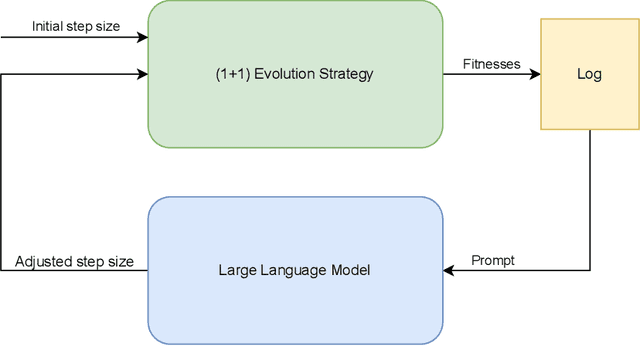

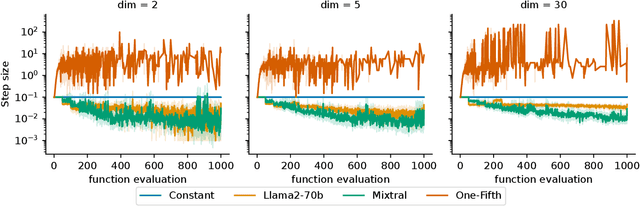

Hyperparameter optimization is a crucial problem in Evolutionary Computation. In fact, the values of the hyperparameters directly impact the trajectory taken by the optimization process, and their choice requires extensive reasoning by human operators. Although a variety of self-adaptive Evolutionary Algorithms have been proposed in the literature, no definitive solution has been found. In this work, we perform a preliminary investigation to automate the reasoning process that leads to the choice of hyperparameter values. We employ two open-source Large Language Models (LLMs), namely Llama2-70b and Mixtral, to analyze the optimization logs online and provide novel real-time hyperparameter recommendations. We study our approach in the context of step-size adaptation for (1+1)-ES. The results suggest that LLMs can be an effective method for optimizing hyperparameters in Evolution Strategies, encouraging further research in this direction.
Assessing Climate Transition Risks in the Colombian Processed Food Sector: A Fuzzy Logic and Multicriteria Decision-Making Approach
Apr 13, 2024



Climate risk assessment is becoming increasingly important. For organisations, identifying and assessing climate-related risks is challenging, as they can come from multiple sources. This study identifies and assesses the main climate transition risks in the colombian processed food sector. As transition risks are vague, our approach uses Fuzzy Logic and compares it to various multi-criteria decision-making methods to classify the different climate transition risks an organisation may be exposed to. This approach allows us to use linguistic expressions for risk analysis and to better describe risks and their consequences. The results show that the risks ranked as the most critical for this organisation in their order were price volatility and raw materials availability, the change to less carbon-intensive production or consumption patterns, the increase in carbon taxes and technological change, and the associated development or implementation costs. These risks show a critical risk level, which implies that they are the most significant risks for the organisation in the case study. These results highlight the importance of investments needed to meet regulatory requirements, which are the main drivers for organisations at the financial level.
Context-Aware Quantitative Risk Assessment Machine Learning Model for Drivers Distraction
Feb 20, 2024
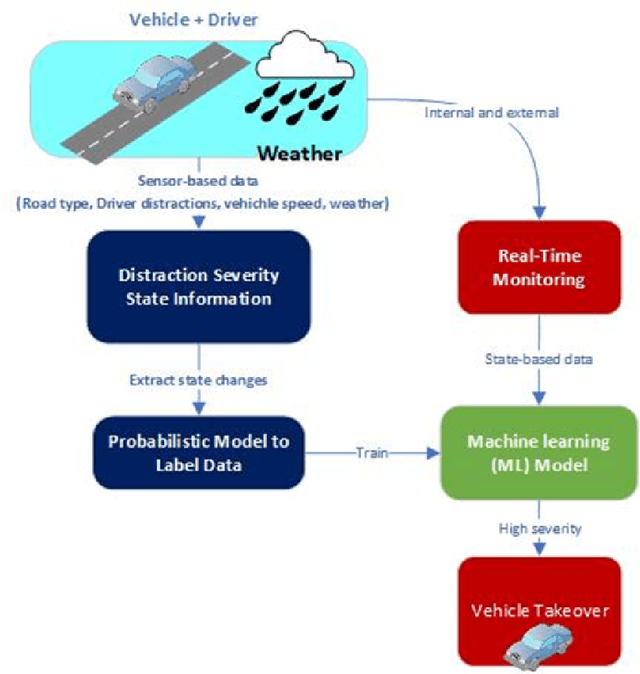

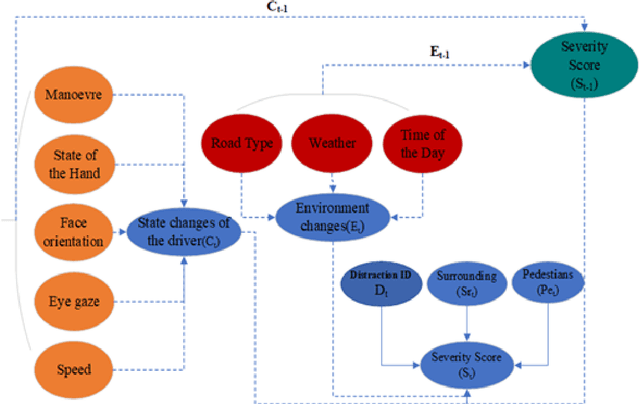
Risk mitigation techniques are critical to avoiding accidents associated with driving behaviour. We provide a novel Multi-Class Driver Distraction Risk Assessment (MDDRA) model that considers the vehicle, driver, and environmental data during a journey. MDDRA categorises the driver on a risk matrix as safe, careless, or dangerous. It offers flexibility in adjusting the parameters and weights to consider each event on a specific severity level. We collect real-world data using the Field Operation Test (TeleFOT), covering drivers using the same routes in the East Midlands, United Kingdom (UK). The results show that reducing road accidents caused by driver distraction is possible. We also study the correlation between distraction (driver, vehicle, and environment) and the classification severity based on a continuous distraction severity score. Furthermore, we apply machine learning techniques to classify and predict driver distraction according to severity levels to aid the transition of control from the driver to the vehicle (vehicle takeover) when a situation is deemed risky. The Ensemble Bagged Trees algorithm performed best, with an accuracy of 96.2%.
Patterns of Convergence and Bound Constraint Violation in Differential Evolution on SBOX-COST Benchmarking Suite
May 20, 2023This study investigates the influence of several bound constraint handling methods (BCHMs) on the search process specific to Differential Evolution (DE), with a focus on identifying similarities between BCHMs and grouping patterns with respect to the number of cases when a BCHM is activated. The empirical analysis is conducted on the SBOX-COST benchmarking test suite, where bound constraints are enforced on the problem domain. This analysis provides some insights that might be useful in designing adaptive strategies for handling such constraints.
Modular Differential Evolution
Apr 19, 2023



New contributions in the field of iterative optimisation heuristics are often made in an iterative manner. Novel algorithmic ideas are not proposed in isolation, but usually as an extension of a preexisting algorithm. Although these contributions are often compared to the base algorithm, it is challenging to make fair comparisons between larger sets of algorithm variants. This happens because even small changes in the experimental setup, parameter settings, or implementation details can cause results to become incomparable. Modular algorithms offer a way to overcome these challenges. By implementing the algorithmic modifications into a common framework, many algorithm variants can be compared, while ensuring that implementation details match in all versions. In this work, we propose a version of a modular framework for the popular Differential Evolution (DE) algorithm. We show that this modular approach not only aids in comparison, but also allows for a much more detailed exploration of the space of possible DE variants. This is illustrated by showing that tuning the settings of modular DE vastly outperforms a set of commonly used DE versions which have been recreated in our framework. We then investigate these tuned algorithms in detail, highlighting the relation between modules and performance on particular problems.
Deep-BIAS: Detecting Structural Bias using Explainable AI
Apr 04, 2023Evaluating the performance of heuristic optimisation algorithms is essential to determine how well they perform under various conditions. Recently, the BIAS toolbox was introduced as a behaviour benchmark to detect structural bias (SB) in search algorithms. The toolbox can be used to identify biases in existing algorithms, as well as to test for bias in newly developed algorithms. In this article, we introduce a novel and explainable deep-learning expansion of the BIAS toolbox, called Deep-BIAS. Where the original toolbox uses 39 statistical tests and a Random Forest model to predict the existence and type of SB, the Deep-BIAS method uses a trained deep-learning model to immediately detect the strength and type of SB based on the raw performance distributions. Through a series of experiments with a variety of structurally biased scenarios, we demonstrate the effectiveness of Deep-BIAS. We also present the results of using the toolbox on 336 state-of-the-art optimisation algorithms, which showed the presence of various types of structural bias, particularly towards the centre of the objective space or exhibiting discretisation behaviour. The Deep-BIAS method outperforms the BIAS toolbox both in detecting bias and for classifying the type of SB. Furthermore, explanations can be derived using XAI techniques.
Direct deduction of chemical class from NMR spectra
Nov 06, 2022

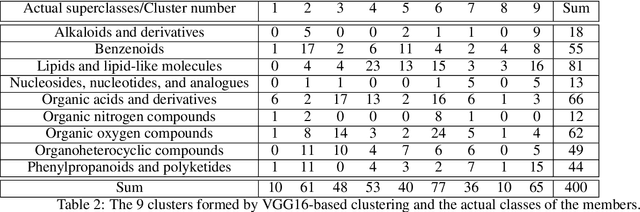

This paper presents a proof-of-concept method for classifying chemical compounds directly from NMR data without doing structure elucidation. This can help to reduce time in finding good structure candidates, as in most cases matching must be done by a human engineer, or at the very least a process for matching must be meaningfully interpreted by one. Therefore, for a long time automation in the area of NMR has been actively sought. The method identified as suitable for the classification is a convolutional neural network (CNN). Other methods, including clustering and image registration, have not been found suitable for the task in a comparative analysis. The result shows that deep learning can offer solutions to automation problems in cheminformatics.
The importance of being constrained: dealing with infeasible solutions in Differential Evolution and beyond
Mar 07, 2022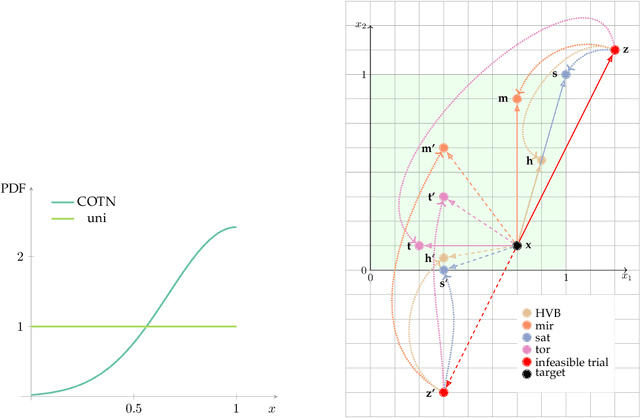

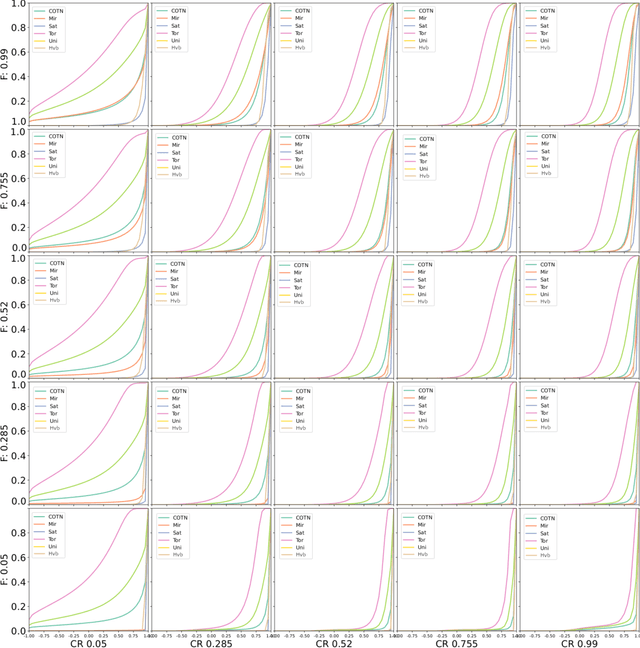
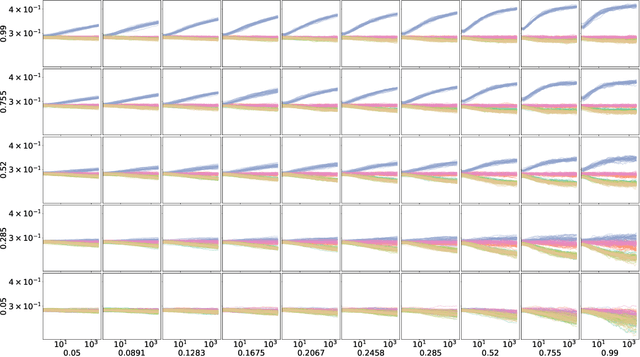
We argue that results produced by a heuristic optimisation algorithm cannot be considered reproducible unless the algorithm fully specifies what should be done with solutions generated outside the domain, even in the case of simple box constraints. Currently, in the field of heuristic optimisation, such specification is rarely mentioned or investigated due to the assumed triviality or insignificance of this question. Here, we demonstrate that, at least in algorithms based on Differential Evolution, this choice induces notably different behaviours - in terms of performance, disruptiveness and population diversity. This is shown theoretically (where possible) for standard Differential Evolution in the absence of selection pressure and experimentally for the standard and state-of-the-art Differential Evolution variants on special test function $f_0$ and BBOB benchmarking suite, respectively. Moreover, we demonstrate that the importance of this choice quickly grows with problem's dimensionality. Different Evolution is not at all special in this regard - there is no reason to presume that other heuristic optimisers are not equally affected by the aforementioned algorithmic choice. Thus, we urge the field of heuristic optimisation to formalise and adopt the idea of a new algorithmic component in heuristic optimisers, which we call here a strategy of dealing with infeasible solutions. This component needs to be consistently (a) specified in algorithmic descriptions to guarantee reproducibility of results, (b) studied to better understand its impact on algorithm's performance in a wider sense and (c) included in the (automatic) algorithmic design. All of these should be done even for problems with box constraints.
Emergence of Structural Bias in Differential Evolution
May 10, 2021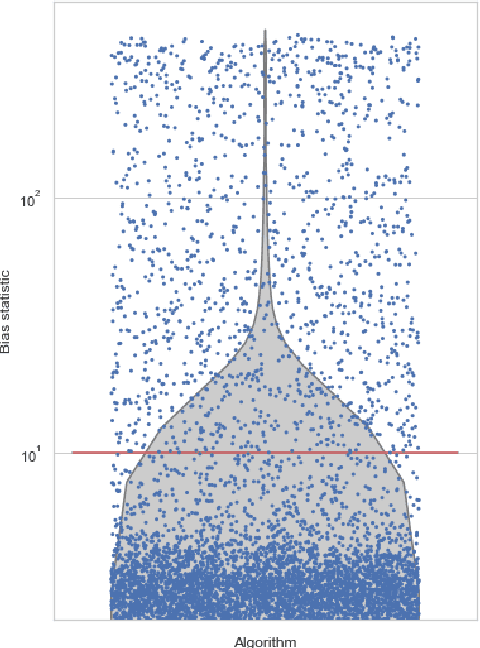
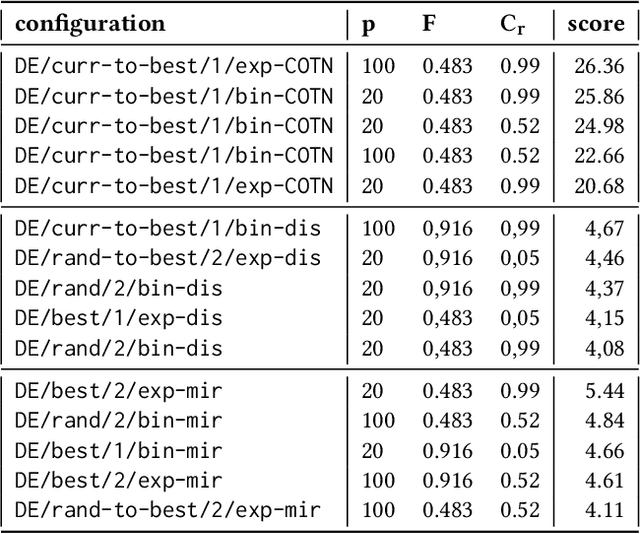
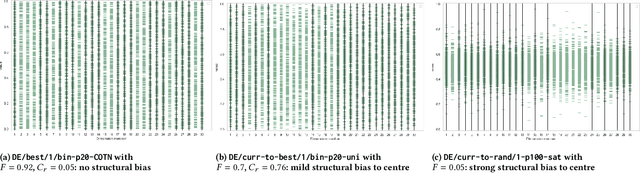
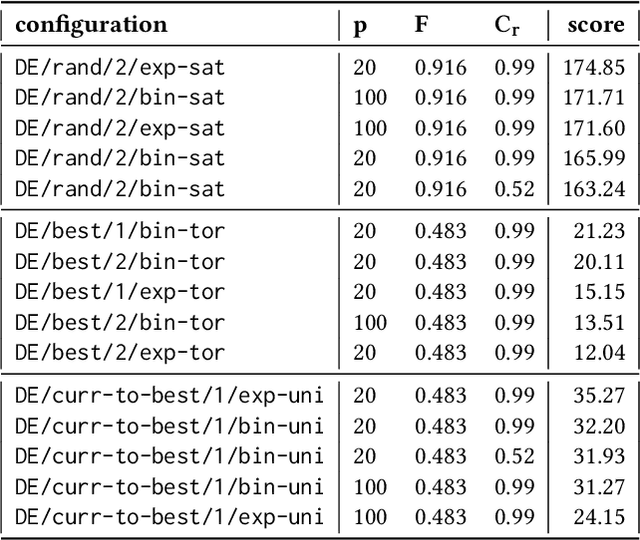
Heuristic optimisation algorithms are in high demand due to the overwhelming amount of complex optimisation problems that need to be solved. The complexity of these problems is well beyond the boundaries of applicability of exact optimisation algorithms and therefore require modern heuristics to find feasible solutions quickly. These heuristics and their effects are almost always evaluated and explained by particular problem instances. In previous works, it has been shown that many such algorithms show structural bias, by either being attracted to a certain region of the search space or by consistently avoiding regions of the search space, on a special test function designed to ensure uniform 'exploration' of the domain. In this paper, we analyse the emergence of such structural bias for Differential Evolution (DE) configurations and, specifically, the effect of different mutation, crossover and correction strategies. We also analyse the emergence of the structural bias during the run-time of each algorithm. We conclude with recommendations of which configurations should be avoided in order to run DE unbiased.