 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-BIAS: Detecting Structural Bias using Explainable AI
Apr 04, 2023Evaluating the performance of heuristic optimisation algorithms is essential to determine how well they perform under various conditions. Recently, the BIAS toolbox was introduced as a behaviour benchmark to detect structural bias (SB) in search algorithms. The toolbox can be used to identify biases in existing algorithms, as well as to test for bias in newly developed algorithms. In this article, we introduce a novel and explainable deep-learning expansion of the BIAS toolbox, called Deep-BIAS. Where the original toolbox uses 39 statistical tests and a Random Forest model to predict the existence and type of SB, the Deep-BIAS method uses a trained deep-learning model to immediately detect the strength and type of SB based on the raw performance distributions. Through a series of experiments with a variety of structurally biased scenarios, we demonstrate the effectiveness of Deep-BIAS. We also present the results of using the toolbox on 336 state-of-the-art optimisation algorithms, which showed the presence of various types of structural bias, particularly towards the centre of the objective space or exhibiting discretisation behaviour. The Deep-BIAS method outperforms the BIAS toolbox both in detecting bias and for classifying the type of SB. Furthermore, explanations can be derived using XAI techniques.
DoE2Vec: Deep-learning Based Features for Exploratory Landscape Analysis
Mar 31, 2023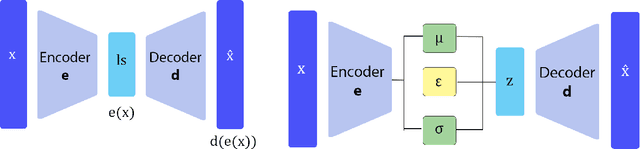
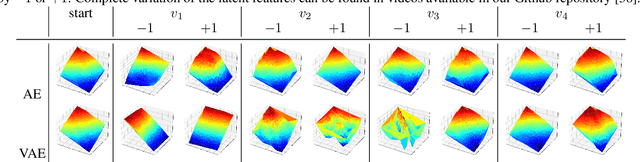
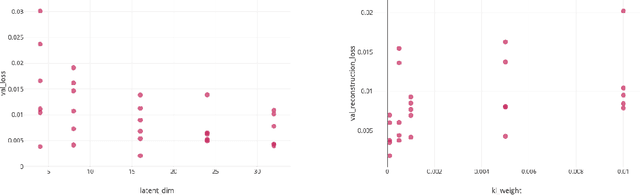
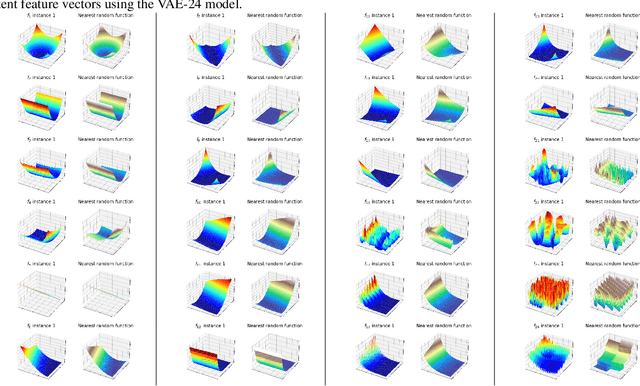
We propose DoE2Vec, a variational autoencoder (VAE)-based methodology to learn optimization landscape characteristics for downstream meta-learning tasks, e.g., automated selection of optimization algorithms. Principally, using large training data sets generated with a random function generator, DoE2Vec self-learns an informative latent representation for any design of experiments (DoE). Unlike the classical exploratory landscape analysis (ELA) method, our approach does not require any feature engineering and is easily applicable for high dimensional search spaces. For validation, we inspect the quality of latent reconstructions and analyze the latent representations using different experiments. The latent representations not only show promising potentials in identifying similar (cheap-to-evaluate) surrogate functions, but also can significantly boost performances when being used complementary to the classical ELA features in classification tasks.
Multi-surrogate Assisted Efficient Global Optimization for Discrete Problems
Dec 13, 2022Decades of progress in simulation-based surrogate-assisted optimization and unprecedented growth in computational power have enabled researchers and practitioners to optimize previously intractable complex engineering problems. This paper investigates the possible benefit of a concurrent utilization of multiple simulation-based surrogate models to solve complex discrete optimization problems. To fulfill this, the so-called Self-Adaptive Multi-surrogate Assisted Efficient Global Optimization algorithm (SAMA-DiEGO), which features a two-stage online model management strategy, is proposed and further benchmarked on fifteen binary-encoded combinatorial and fifteen ordinal problems against several state-of-the-art non-surrogate or single surrogate assisted optimization algorithms. Our findings indicate that SAMA-DiEGO can rapidly converge to better solutions on a majority of the test problems, which shows the feasibility and advantage of using multiple surrogate models in optimizing discrete problems.
BBOB Instance Analysis: Landscape Properties and Algorithm Performance across Problem Instances
Nov 29, 2022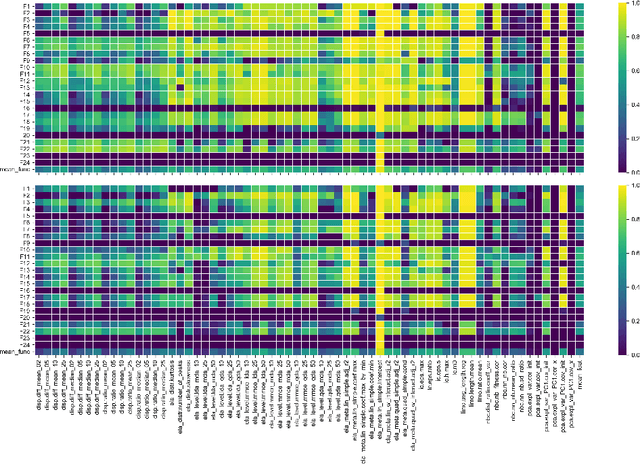
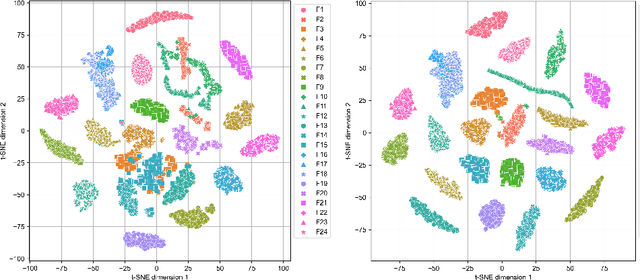
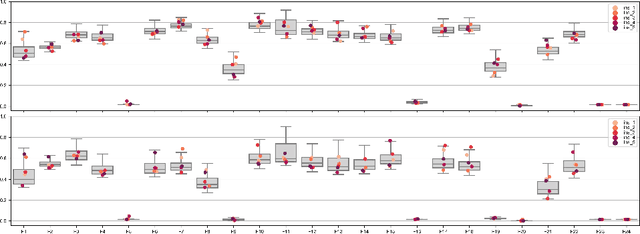
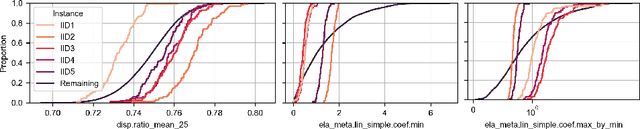
Benchmarking is a key aspect of research into optimization algorithms, and as such the way in which the most popular benchmark suites are designed implicitly guides some parts of algorithm design. One of these suites is the black-box optimization benchmarking (BBOB) suite of 24 single-objective noiseless functions, which has been a standard for over a decade. Within this problem suite, different instances of a single problem can be created, which is beneficial for testing the stability and invariance of algorithms under transformations. In this paper, we investigate the BBOB instance creation protocol by considering a set of 500 instances for each BBOB problem. Using exploratory landscape analysis, we show that the distribution of landscape features across BBOB instances is highly diverse for a large set of problems. In addition, we run a set of eight algorithms across these 500 instances, and investigate for which cases statistically significant differences in performance occur. We argue that, while the transformations applied in BBOB instances do indeed seem to preserve the high-level properties of the functions, their difference in practice should not be overlooked, particularly when treating the problems as box-constrained instead of unconstrained.
Deep Learning based pipeline for anomaly detection and quality enhancement in industrial binder jetting processes
Sep 23, 2022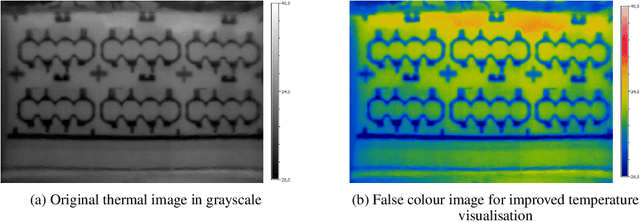


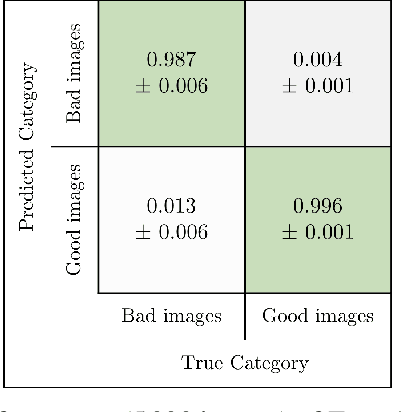
Anomaly detection describes methods of finding abnormal states, instances or data points that differ from a normal value space. Industrial processes are a domain where predicitve models are needed for finding anomalous data instances for quality enhancement. A main challenge, however, is absence of labels in this environment. This paper contributes to a data-centric way of approaching artificial intelligence in industrial production. With a use case from additive manufacturing for automotive components we present a deep-learning-based image processing pipeline. Additionally, we integrate the concept of domain randomisation and synthetic data in the loop that shows promising results for bridging advances in deep learning and its application to real-world, industrial production processes.
Explainable Artificial Intelligence for Exhaust Gas Temperature of Turbofan Engines
Mar 25, 2022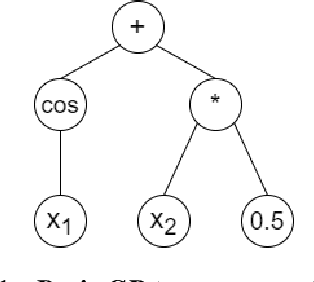
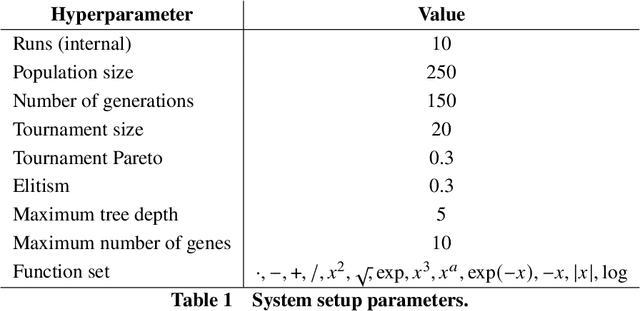
Data-driven modeling is an imperative tool in various industrial applications, including many applications in the sectors of aeronautics and commercial aviation. These models are in charge of providing key insights, such as which parameters are important on a specific measured outcome or which parameter values we should expect to observe given a set of input parameters. At the same time, however, these models rely heavily on assumptions (e.g., stationarity) or are "black box" (e.g., deep neural networks), meaning that they lack interpretability of their internal working and can be viewed only in terms of their inputs and outputs. An interpretable alternative to the "black box" models and with considerably less assumptions is symbolic regression (SR). SR searches for the optimal model structure while simultaneously optimizing the model's parameters without relying on an a-priori model structure. In this work, we apply SR on real-life exhaust gas temperature (EGT) data, collected at high frequencies through the entire flight, in order to uncover meaningful algebraic relationships between the EGT and other measurable engine parameters. The experimental results exhibit promising model accuracy, as well as explainability returning an absolute difference of 3{\deg}C compared to the ground truth and demonstrating consistency from an engineering perspective.
Using Machine Learning to Detect Rotational Symmetries from Reflectional Symmetries in 2D Images
Jan 17, 2022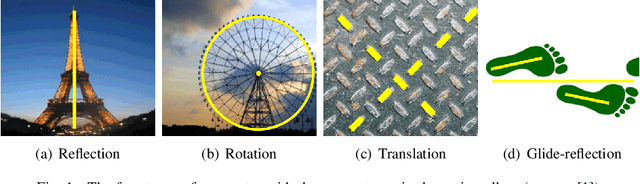


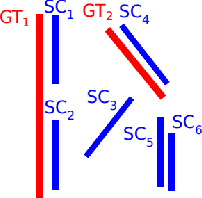
Automated symmetry detection is still a difficult task in 2021. However, it has applications in computer vision, and it also plays an important part in understanding art. This paper focuses on aiding the latter by comparing different state-of-the-art automated symmetry detection algorithms. For one of such algorithms aimed at reflectional symmetries, we propose post-processing improvements to find localised symmetries in images, improve the selection of detected symmetries and identify another symmetry type (rotational). In order to detect rotational symmetries, we contribute a machine learning model which detects rotational symmetries based on provided reflection symmetry axis pairs. We demonstrate and analyze the performance of the extended algorithm to detect localised symmetries and the machine learning model to classify rotational symmetries.
Emergence of Structural Bias in Differential Evolution
May 10, 2021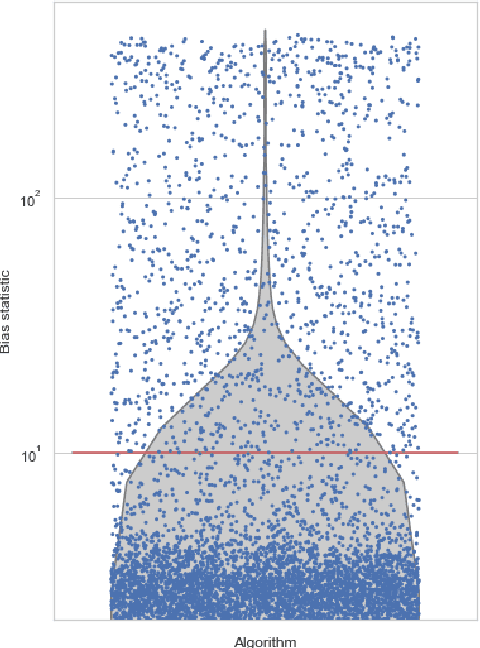
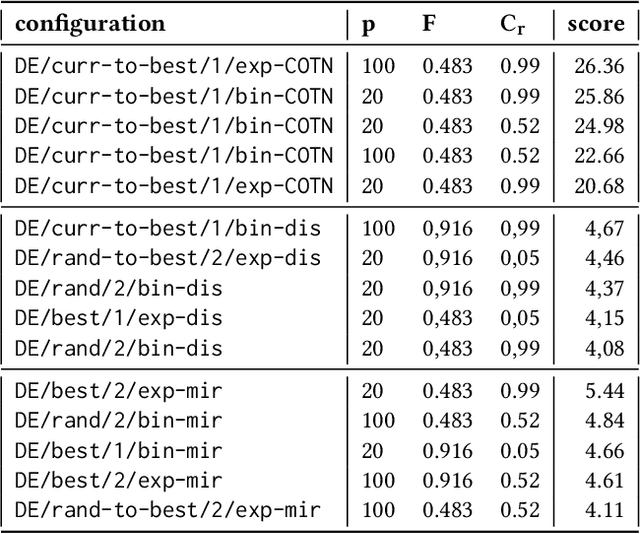
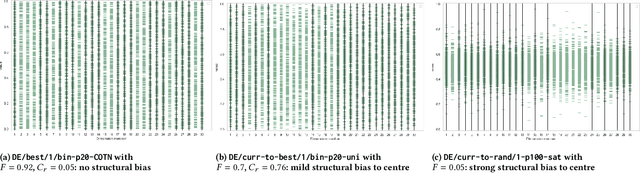
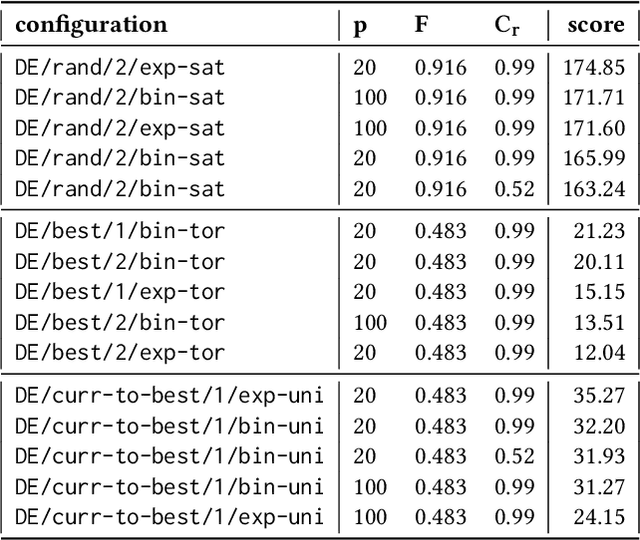
Heuristic optimisation algorithms are in high demand due to the overwhelming amount of complex optimisation problems that need to be solved. The complexity of these problems is well beyond the boundaries of applicability of exact optimisation algorithms and therefore require modern heuristics to find feasible solutions quickly. These heuristics and their effects are almost always evaluated and explained by particular problem instances. In previous works, it has been shown that many such algorithms show structural bias, by either being attracted to a certain region of the search space or by consistently avoiding regions of the search space, on a special test function designed to ensure uniform 'exploration' of the domain. In this paper, we analyse the emergence of such structural bias for Differential Evolution (DE) configurations and, specifically, the effect of different mutation, crossover and correction strategies. We also analyse the emergence of the structural bias during the run-time of each algorithm. We conclude with recommendations of which configurations should be avoided in order to run DE unbiased.
Neural Network Design: Learning from Neural Architecture Search
Nov 01, 2020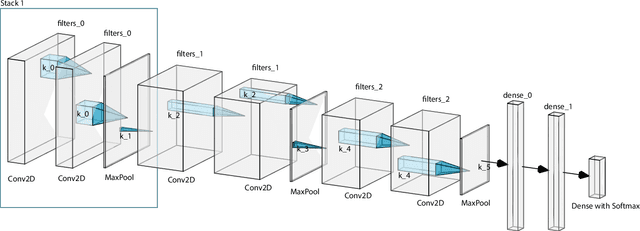
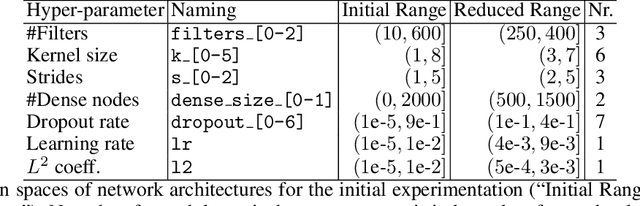
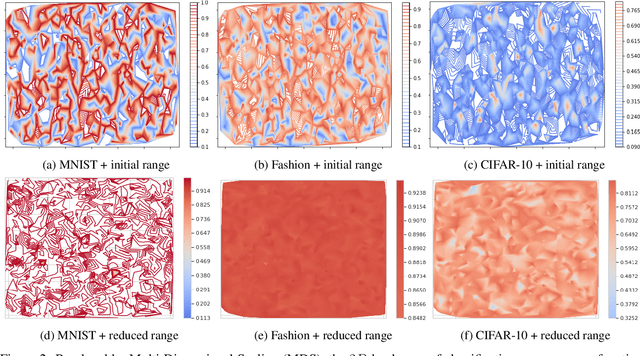
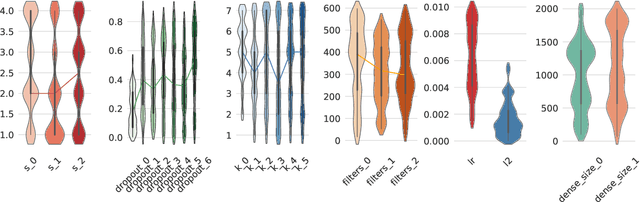
Neural Architecture Search (NAS) aims to optimize deep neural networks' architecture for better accuracy or smaller computational cost and has recently gained more research interests. Despite various successful approaches proposed to solve the NAS task, the landscape of it, along with its properties, are rarely investigated. In this paper, we argue for the necessity of studying the landscape property thereof and propose to use the so-called Exploratory Landscape Analysis (ELA) techniques for this goal. Taking a broad set of designs of the deep convolutional network, we conduct extensive experimentation to obtain their performance. Based on our analysis of the experimental results, we observed high similarities between well-performing architecture designs, which is then used to significantly narrow the search space to improve the efficiency of any NAS algorithm. Moreover, we extract the ELA features over the NAS landscapes on three common image classification data sets, MNIST, Fashion, and CIFAR-10, which shows that the NAS landscape can be distinguished for those three data sets. Also, when comparing to the ELA features of the well-known Black-Box Optimization Benchmarking (BBOB) problem set, we found out that the NAS landscapes surprisingly form a new problem class on its own, which can be separated from all $24$ BBOB problems. Given this interesting observation, we, therefore, state the importance of further investigation on selecting an efficient optimizer for the NAS landscape as well as the necessity of augmenting the current benchmark problem set.
A Tailored NSGA-III Instantiation for Flexible Job Shop Scheduling
Apr 14, 2020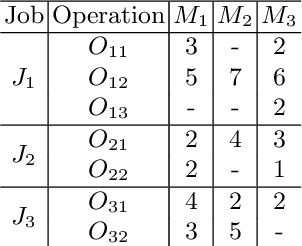
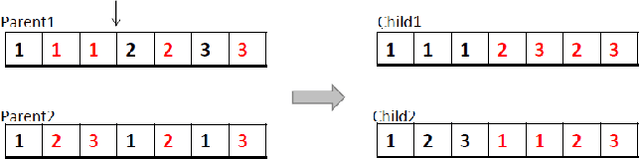
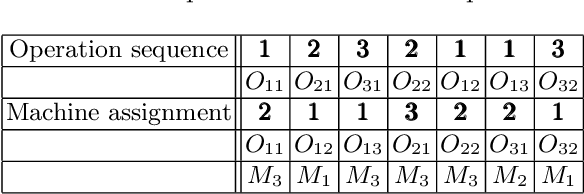
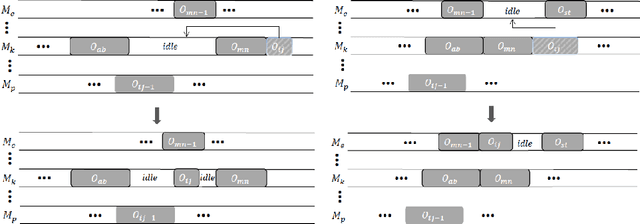
A customized multi-objective evolutionary algorithm (MOEA) is proposed for the multi-objective flexible job shop scheduling problem (FJSP). It uses smart initialization approaches to enrich the first generated population, and proposes various crossover operators to create a better diversity of offspring. Especially, the MIP-EGO configurator, which can tune algorithm parameters, is adopted to automatically tune operator probabilities. Furthermore, different local search strategies are employed to explore the neighborhood for better solutions. In general, the algorithm enhancement strategy can be integrated with any standard EMO algorithm. In this paper, it has been combined with NSGA-III to solve benchmark multi-objective FJSPs, whereas an off-the-shelf implementation of NSGA-III is not capable of solving the FJSP. The experimental results show excellent performance with less computing budget.