 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBOB Instance Analysis: Landscape Properties and Algorithm Performance across Problem Instances
Paper and Code
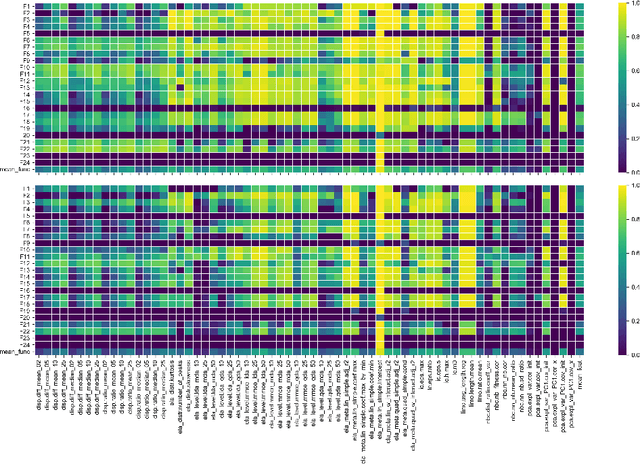
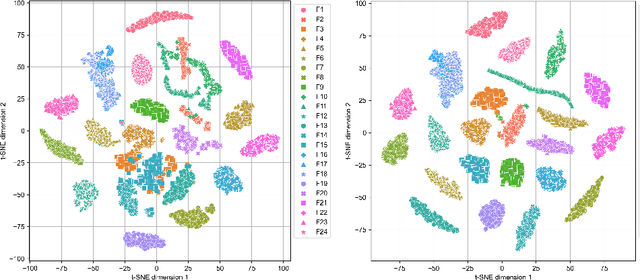
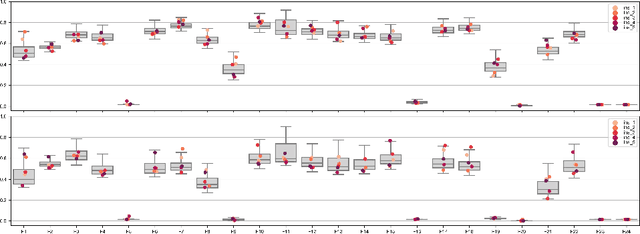
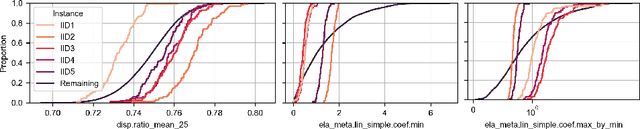
Benchmarking is a key aspect of research into optimization algorithms, and as such the way in which the most popular benchmark suites are designed implicitly guides some parts of algorithm design. One of these suites is the black-box optimization benchmarking (BBOB) suite of 24 single-objective noiseless functions, which has been a standard for over a decade. Within this problem suite, different instances of a single problem can be created, which is beneficial for testing the stability and invariance of algorithms under transformations. In this paper, we investigate the BBOB instance creation protocol by considering a set of 500 instances for each BBOB problem. Using exploratory landscape analysis, we show that the distribution of landscape features across BBOB instances is highly diverse for a large set of problems. In addition, we run a set of eight algorithms across these 500 instances, and investigate for which cases statistically significant differences in performance occur. We argue that, while the transformations applied in BBOB instances do indeed seem to preserve the high-level properties of the functions, their difference in practice should not be overlooked, particularly when treating the problems as box-constrained instead of unconstrained.