 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetweet communities reveal the main sources of hate speech
May 31, 2021

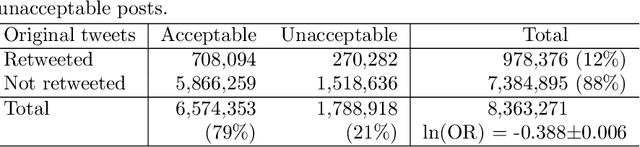
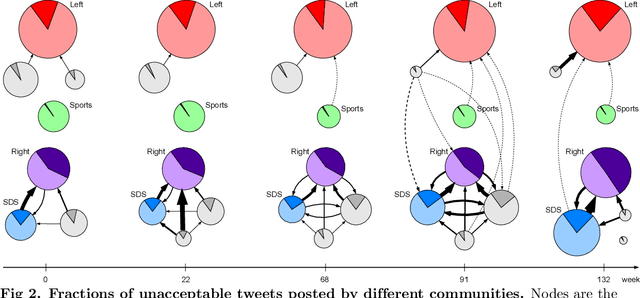
We address a challenging problem of identifying main sources of hate speech on Twitter. On one hand, we carefully annotate a large set of tweets for hate speech, and deploy advanced deep learning to produce high quality hate speech classification models. On the other hand, we create retweet networks, detect communities and monitor their evolution through time. This combined approach is applied to three years of Slovenian Twitter data. We report a number of interesting results. Hate speech is dominated by offensive tweets, related to political and ideological issues. The share of unacceptable tweets is moderately increasing with time, from the initial 20% to 30% by the end of 2020. Unacceptable tweets are retweeted significantly more often than acceptable tweets. About 60% of unacceptable tweets are produced by a single right-wing community of only moderate size. Institutional Twitter accounts and media accounts post significantly less unacceptable tweets than individual accounts. However, the main sources of unacceptable tweets are anonymous accounts, and accounts that were suspended or closed during the last three years.
Cross-lingual Transfer of Twitter Sentiment Models Using a Common Vector Space
May 18, 2020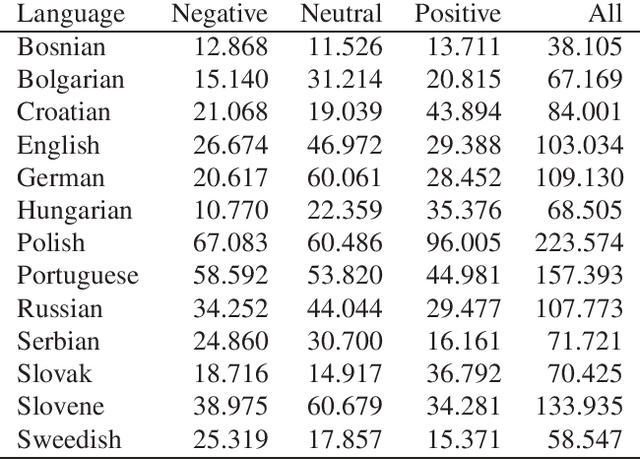
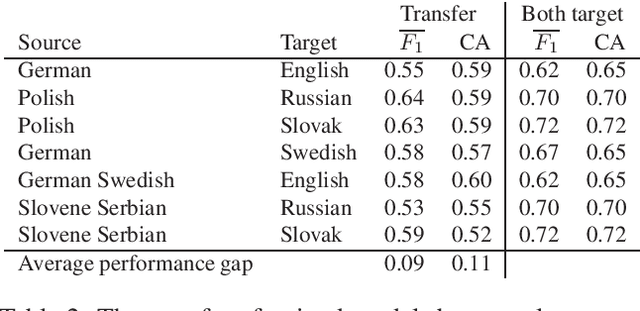
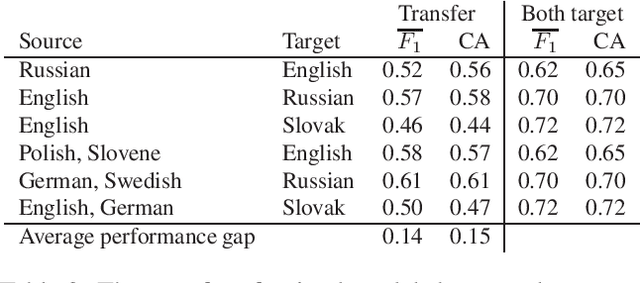
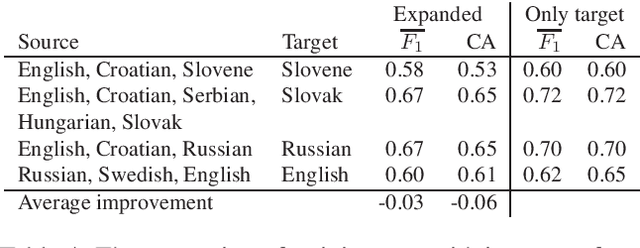
Word embeddings represent words in a numeric space in such a way that semantic relations between words are encoded as distances and directions in the vector space. Cross-lingual word embeddings map words from one language to the vector space of another language, or words from multiple languages to the same vector space where similar words are aligned. Cross-lingual embeddings can be used to transfer machine learning models between languages and thereby compensate for insufficient data in less-resourced languages. We use cross-lingual word embeddings to transfer machine learning prediction models for Twitter sentiment between 13 languages. We focus on two transfer mechanisms using the joint numerical space for many languages as implemented in the LASER library: the transfer of trained models, and expansion of training sets with instances from other languages. Our experiments show that the transfer of models between similar languages is sensible, while dataset expansion did not increase the predictive performance.
Evaluating time series forecasting models: An empirical study on performance estimation methods
May 28, 2019

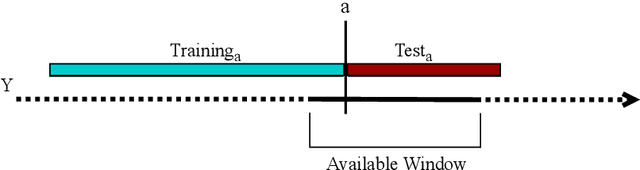
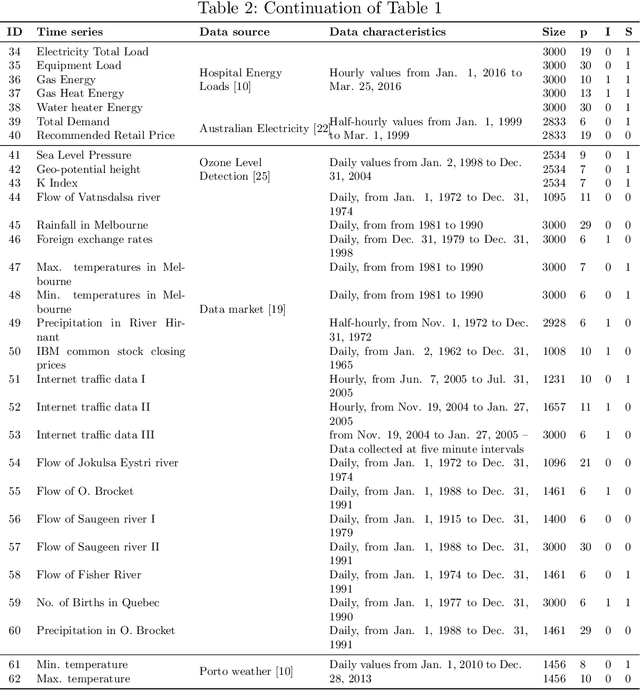
Performance estimation aims at estimating the loss that a predictive model will incur on unseen data. These procedures are part of the pipeline in every machine learning project and are used for assessing the overall generalisation ability of predictive models. In this paper we address the application of these methods to time series forecasting tasks. For independent and identically distributed data the most common approach is cross-validation. However, the dependency among observations in time series raises some caveats about the most appropriate way to estimate performance in this type of data and currently there is no settled way to do so. We compare different variants of cross-validation and of out-of-sample approaches using two case studies: One with 62 real-world time series and another with three synthetic time series. Results show noticeable differences in the performance estimation methods in the two scenarios. In particular, empirical experiments suggest that cross-validation approaches can be applied to stationary time series. However, in real-world scenarios, when different sources of non-stationary variation are at play, the most accurate estimates are produced by out-of-sample methods that preserve the temporal order of observations.
Cohesion and Coalition Formation in the European Parliament: Roll-Call Votes and Twitter Activities
Oct 14, 2016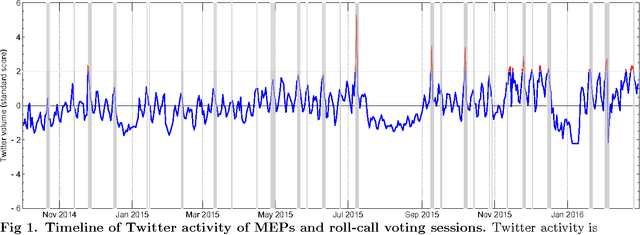
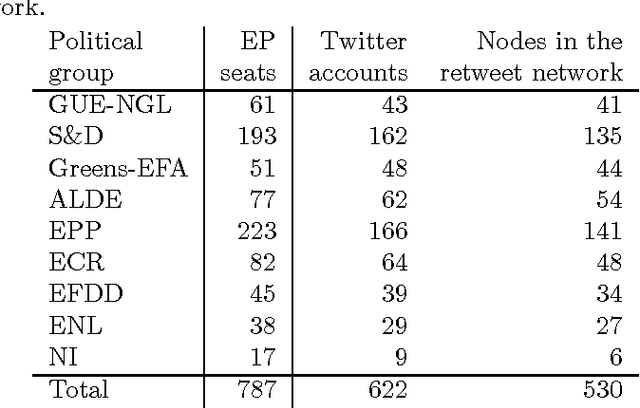
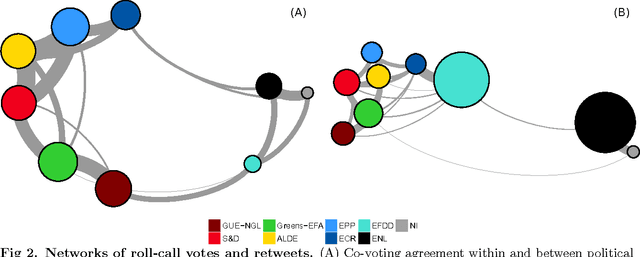

We study the cohesion within and the coalitions between political groups in the Eighth European Parliament (2014--2019) by analyzing two entirely different aspects of the behavior of the Members of the European Parliament (MEPs) in the policy-making processes. On one hand, we analyze their co-voting patterns and, on the other, their retweeting behavior. We make use of two diverse datasets in the analysis. The first one is the roll-call vote dataset, where cohesion is regarded as the tendency to co-vote within a group, and a coalition is formed when the members of several groups exhibit a high degree of co-voting agreement on a subject. The second dataset comes from Twitter; it captures the retweeting (i.e., endorsing) behavior of the MEPs and implies cohesion (retweets within the same group) and coalitions (retweets between groups) from a completely different perspective. We employ two different methodologies to analyze the cohesion and coalitions. The first one is based on Krippendorff's Alpha reliability, used to measure the agreement between raters in data-analysis scenarios, and the second one is based on Exponential Random Graph Models, often used in social-network analysis. We give general insights into the cohesion of political groups in the European Parliament, explore whether coalitions are formed in the same way for different policy areas, and examine to what degree the retweeting behavior of MEPs corresponds to their co-voting patterns. A novel and interesting aspect of our work is the relationship between the co-voting and retweeting patterns.
Multilingual Twitter Sentiment Classification: The Role of Human Annotators
May 05, 2016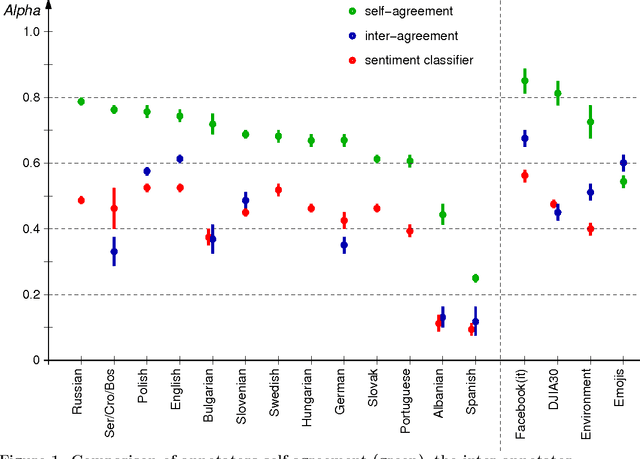
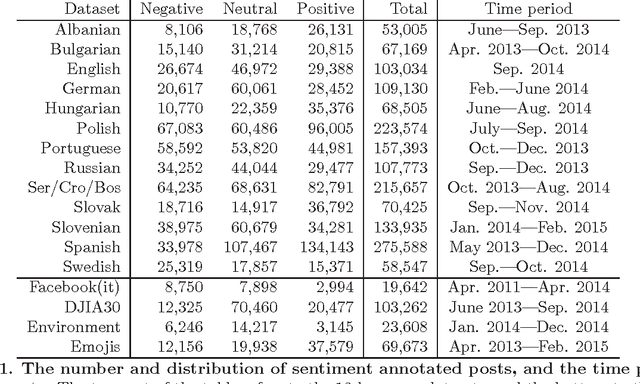
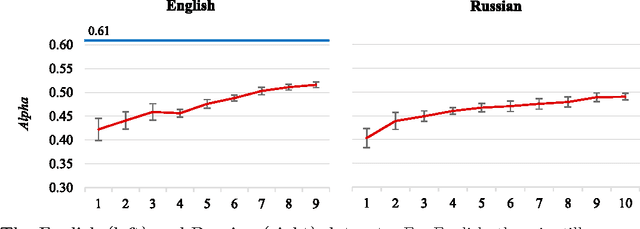
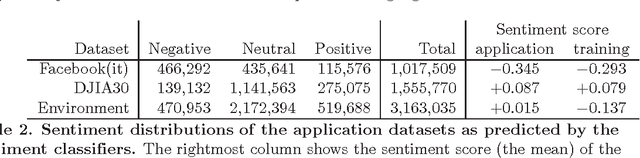
What are the limits of automated Twitter sentiment classification? We analyze a large set of manually labeled tweets in different languages, use them as training data, and construct automated classification models. It turns out that the quality of classification models depends much more on the quality and size of training data than on the type of the model trained. Experimental results indicate that there is no statistically significant difference between the performance of the top classification models. We quantify the quality of training data by applying various annotator agreement measures, and identify the weakest points of different datasets. We show that the model performance approaches the inter-annotator agreement when the size of the training set is sufficiently large. However, it is crucial to regularly monitor the self- and inter-annotator agreements since this improves the training datasets and consequently the model performance. Finally, we show that there is strong evidence that humans perceive the sentiment classes (negative, neutral, and positive) as ordered.