 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Twitter Sentiment Classification: The Role of Human Annotators
May 05, 2016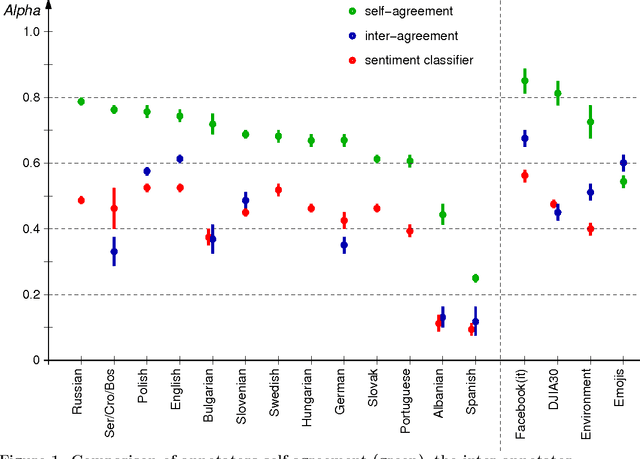
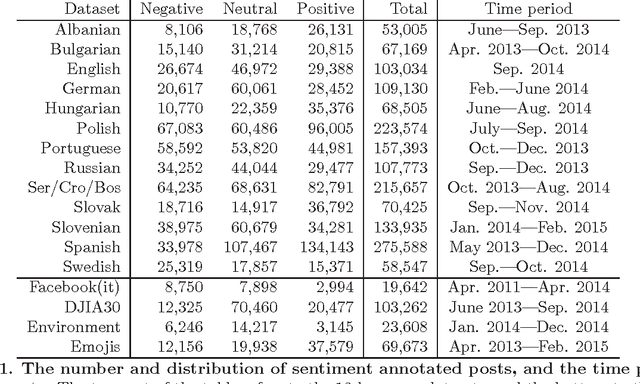
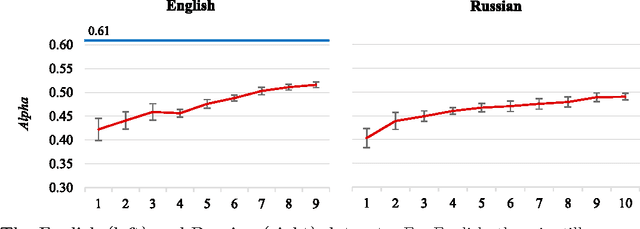
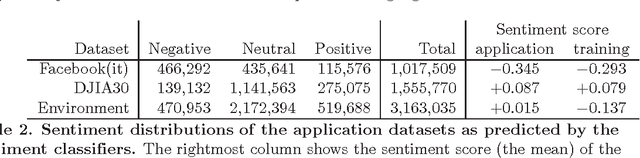
What are the limits of automated Twitter sentiment classification? We analyze a large set of manually labeled tweets in different languages, use them as training data, and construct automated classification models. It turns out that the quality of classification models depends much more on the quality and size of training data than on the type of the model trained. Experimental results indicate that there is no statistically significant difference between the performance of the top classification models. We quantify the quality of training data by applying various annotator agreement measures, and identify the weakest points of different datasets. We show that the model performance approaches the inter-annotator agreement when the size of the training set is sufficiently large. However, it is crucial to regularly monitor the self- and inter-annotator agreements since this improves the training datasets and consequently the model performance. Finally, we show that there is strong evidence that humans perceive the sentiment classes (negative, neutral, and positive) as ordered.