 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohesion and Coalition Formation in the European Parliament: Roll-Call Votes and Twitter Activities
Oct 14, 2016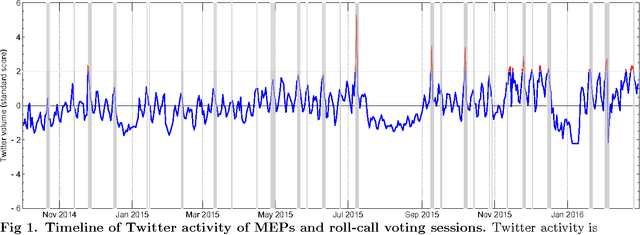
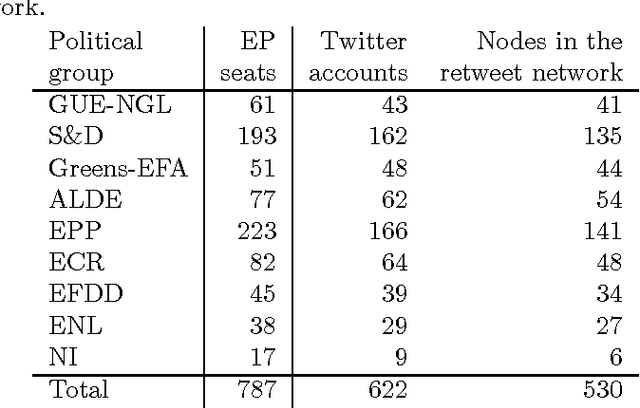
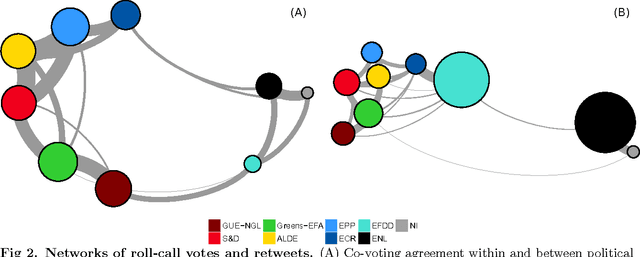

We study the cohesion within and the coalitions between political groups in the Eighth European Parliament (2014--2019) by analyzing two entirely different aspects of the behavior of the Members of the European Parliament (MEPs) in the policy-making processes. On one hand, we analyze their co-voting patterns and, on the other, their retweeting behavior. We make use of two diverse datasets in the analysis. The first one is the roll-call vote dataset, where cohesion is regarded as the tendency to co-vote within a group, and a coalition is formed when the members of several groups exhibit a high degree of co-voting agreement on a subject. The second dataset comes from Twitter; it captures the retweeting (i.e., endorsing) behavior of the MEPs and implies cohesion (retweets within the same group) and coalitions (retweets between groups) from a completely different perspective. We employ two different methodologies to analyze the cohesion and coalitions. The first one is based on Krippendorff's Alpha reliability, used to measure the agreement between raters in data-analysis scenarios, and the second one is based on Exponential Random Graph Models, often used in social-network analysis. We give general insights into the cohesion of political groups in the European Parliament, explore whether coalitions are formed in the same way for different policy areas, and examine to what degree the retweeting behavior of MEPs corresponds to their co-voting patterns. A novel and interesting aspect of our work is the relationship between the co-voting and retweeting patterns.
Multilingual Twitter Sentiment Classification: The Role of Human Annotators
May 05, 2016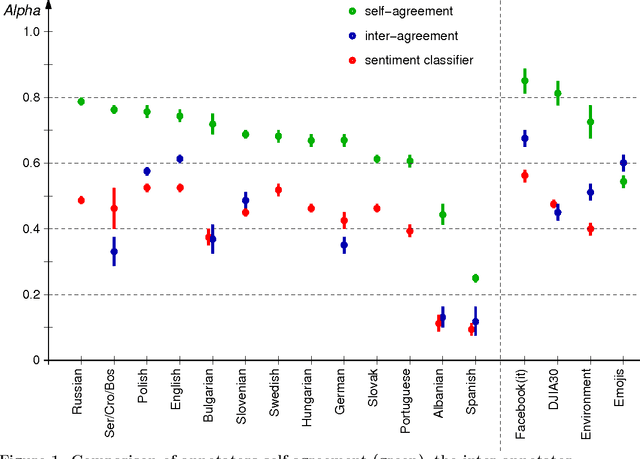
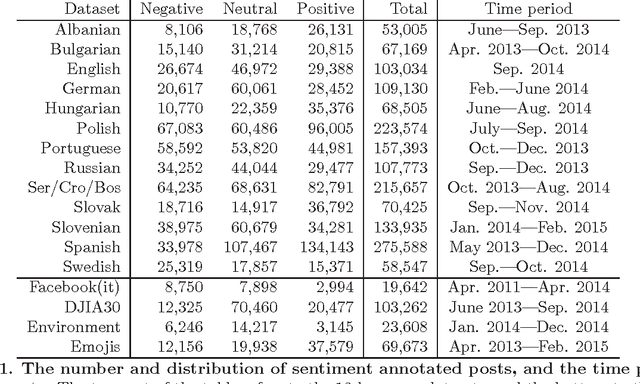
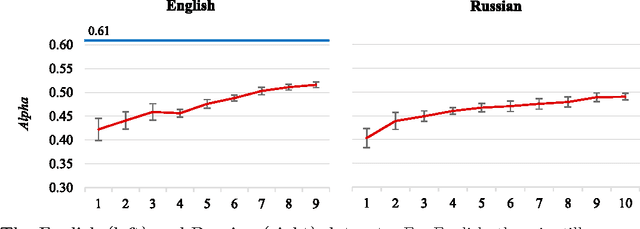
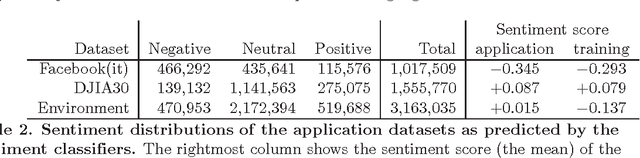
What are the limits of automated Twitter sentiment classification? We analyze a large set of manually labeled tweets in different languages, use them as training data, and construct automated classification models. It turns out that the quality of classification models depends much more on the quality and size of training data than on the type of the model trained. Experimental results indicate that there is no statistically significant difference between the performance of the top classification models. We quantify the quality of training data by applying various annotator agreement measures, and identify the weakest points of different datasets. We show that the model performance approaches the inter-annotator agreement when the size of the training set is sufficiently large. However, it is crucial to regularly monitor the self- and inter-annotator agreements since this improves the training datasets and consequently the model performance. Finally, we show that there is strong evidence that humans perceive the sentiment classes (negative, neutral, and positive) as ordered.