 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffective Polarization across European Parliaments
Aug 26, 2025
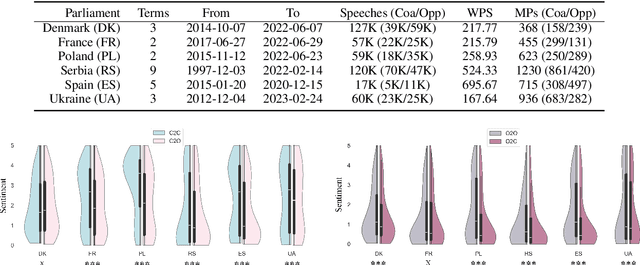
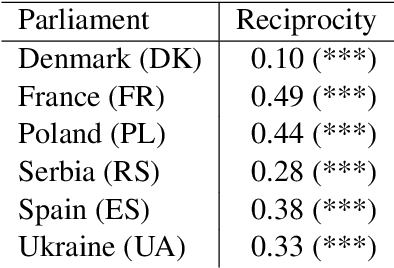
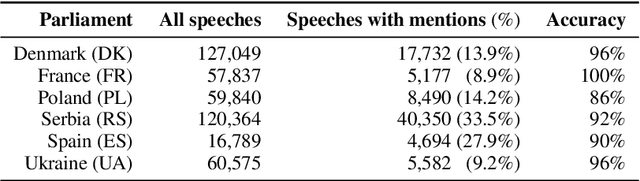
Affective polarization, characterized by increased negativity and hostility towards opposing groups, has become a prominent feature of political discourse worldwide. Our study examines the presence of this type of polarization in a selection of European parliaments in a fully automated manner. Utilizing a comprehensive corpus of parliamentary speeches from the parliaments of six European countries, we employ natural language processing techniques to estimate parliamentarian sentiment. By comparing the levels of negativity conveyed in references to individuals from opposing groups versus one's own, we discover patterns of affectively polarized interactions. The findings demonstrate the existence of consistent affective polarization across all six European parliaments. Although activity correlates with negativity, there is no observed difference in affective polarization between less active and more active members of parliament. Finally, we show that reciprocity is a contributing mechanism in affective polarization between parliamentarians across all six parliaments.
Retweet communities reveal the main sources of hate speech
May 31, 2021

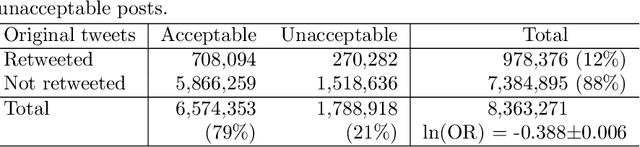
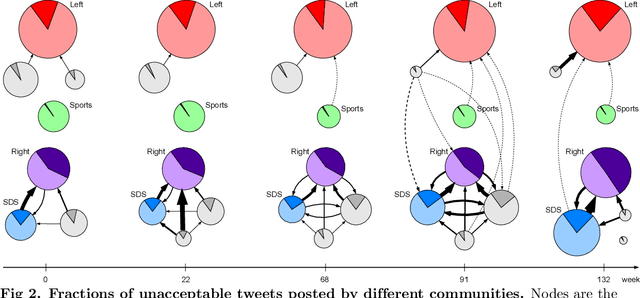
We address a challenging problem of identifying main sources of hate speech on Twitter. On one hand, we carefully annotate a large set of tweets for hate speech, and deploy advanced deep learning to produce high quality hate speech classification models. On the other hand, we create retweet networks, detect communities and monitor their evolution through time. This combined approach is applied to three years of Slovenian Twitter data. We report a number of interesting results. Hate speech is dominated by offensive tweets, related to political and ideological issues. The share of unacceptable tweets is moderately increasing with time, from the initial 20% to 30% by the end of 2020. Unacceptable tweets are retweeted significantly more often than acceptable tweets. About 60% of unacceptable tweets are produced by a single right-wing community of only moderate size. Institutional Twitter accounts and media accounts post significantly less unacceptable tweets than individual accounts. However, the main sources of unacceptable tweets are anonymous accounts, and accounts that were suspended or closed during the last three years.
Online Hate: Behavioural Dynamics and Relationship with Misinformation
May 28, 2021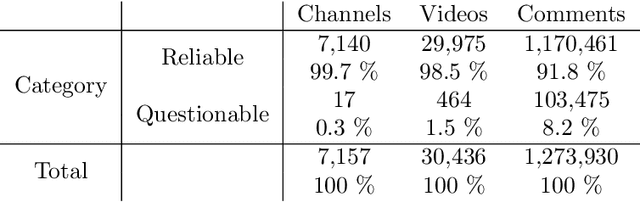
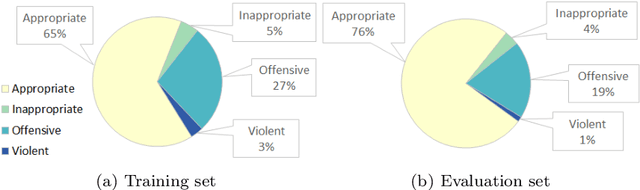

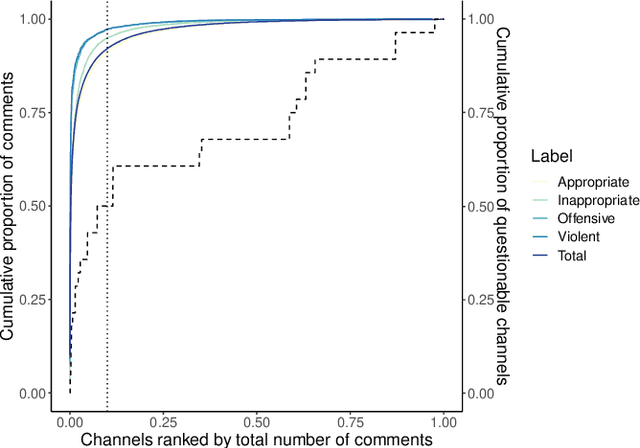
Online debates are often characterised by extreme polarisation and heated discussions among users. The presence of hate speech online is becoming increasingly problematic, making necessary the development of appropriate countermeasures. In this work, we perform hate speech detection on a corpus of more than one million comments on YouTube videos through a machine learning model fine-tuned on a large set of hand-annotated data. Our analysis shows that there is no evidence of the presence of "serial haters", intended as active users posting exclusively hateful comments. Moreover, coherently with the echo chamber hypothesis, we find that users skewed towards one of the two categories of video channels (questionable, reliable) are more prone to use inappropriate, violent, or hateful language within their opponents community. Interestingly, users loyal to reliable sources use on average a more toxic language than their counterpart. Finally, we find that the overall toxicity of the discussion increases with its length, measured both in terms of number of comments and time. Our results show that, coherently with Godwin's law, online debates tend to degenerate towards increasingly toxic exchanges of views.
Leveraging Contextual Embeddings for Detecting Diachronic Semantic Shift
Dec 02, 2019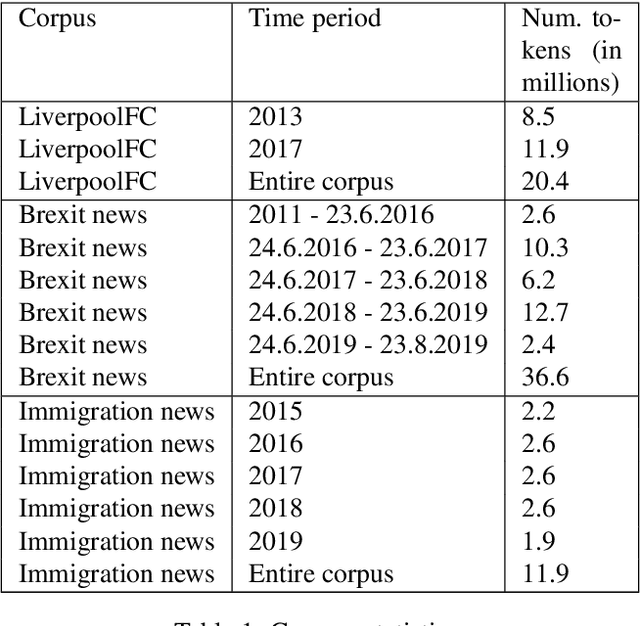
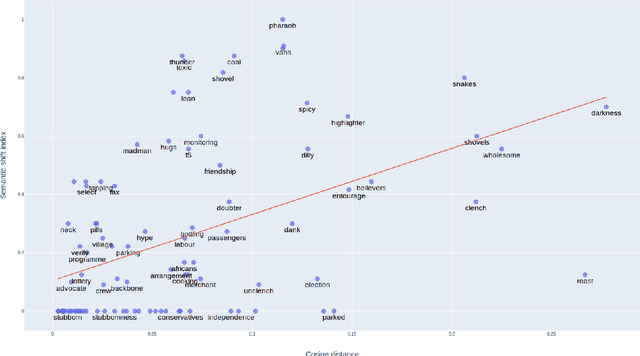
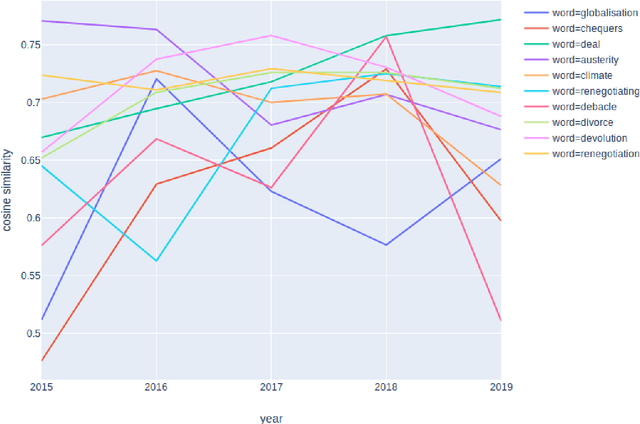
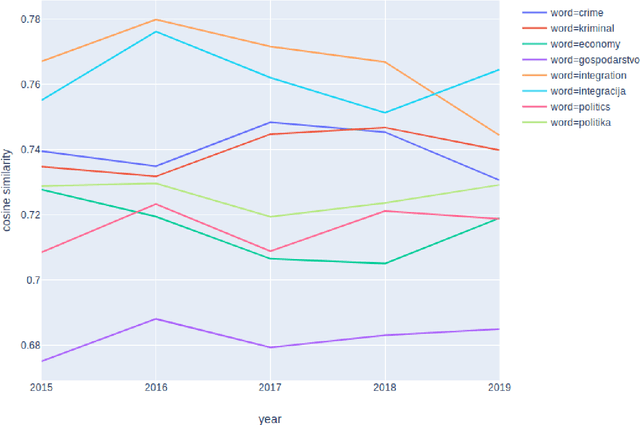
We propose a new method that leverages contextual embeddings for the task of diachronic semantic shift detection by generating time specific word representations from BERT embeddings. The results of the experiments in the domain specific LiverpoolFC corpus suggest that the proposed method has performance comparable to the current state-of-the-art without requiring any time consuming domain adaptation on a large corpora. The results on a newly created Brexit news corpus suggest that the method can be successfully used for the detection of a short-term yearly semantic shift. And lastly, the model also shows promising results in a multilingual settings, where the task was to detect differences and similarities between diachronic semantic shifts in different languages.
Forex trading and Twitter: Spam, bots, and reputation manipulation
Apr 16, 2018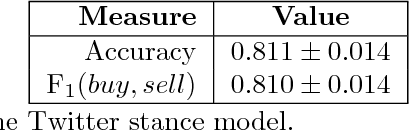
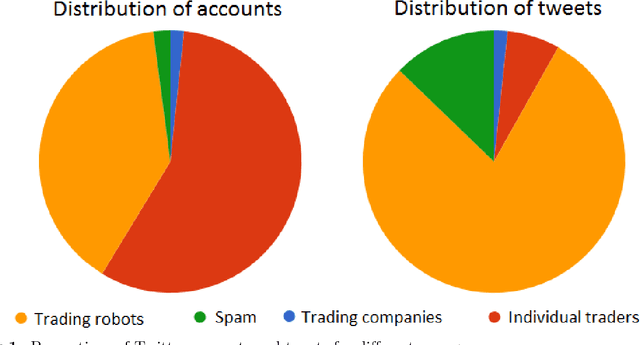
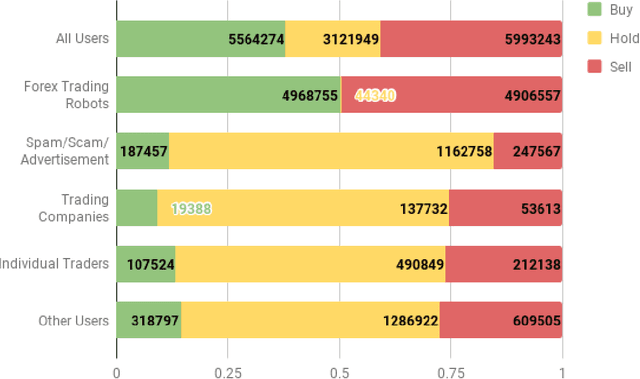
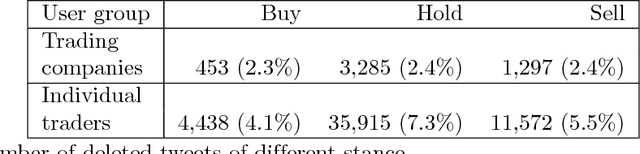
Currency trading (Forex) is the largest world market in terms of volume. We analyze trading and tweeting about the EUR-USD currency pair over a period of three years. First, a large number of tweets were manually labeled, and a Twitter stance classification model is constructed. The model then classifies all the tweets by the trading stance signal: buy, hold, or sell (EUR vs. USD). The Twitter stance is compared to the actual currency rates by applying the event study methodology, well-known in financial economics. It turns out that there are large differences in Twitter stance distribution and potential trading returns between the four groups of Twitter users: trading robots, spammers, trading companies, and individual traders. Additionally, we observe attempts of reputation manipulation by post festum removal of tweets with poor predictions, and deleting/reposting of identical tweets to increase the visibility without tainting one's Twitter timeline.
Sentiment of Emojis
Dec 08, 2015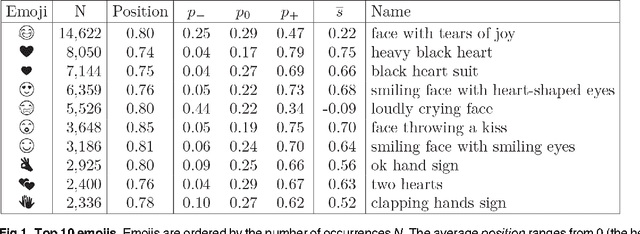

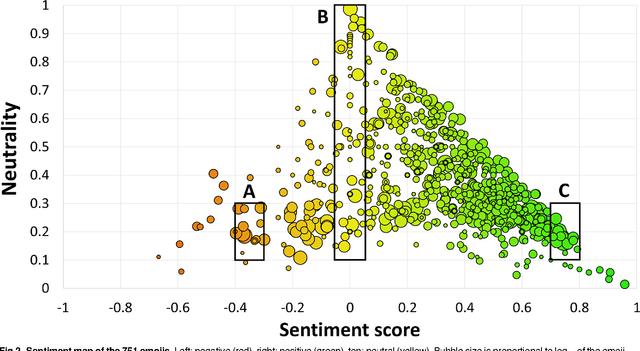
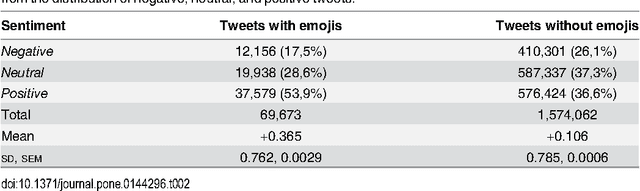
There is a new generation of emoticons, called emojis, that is increasingly being used in mobile communications and social media. In the past two years, over ten billion emojis were used on Twitter. Emojis are Unicode graphic symbols, used as a shorthand to express concepts and ideas. In contrast to the small number of well-known emoticons that carry clear emotional contents, there are hundreds of emojis. But what are their emotional contents? We provide the first emoji sentiment lexicon, called the Emoji Sentiment Ranking, and draw a sentiment map of the 751 most frequently used emojis. The sentiment of the emojis is computed from the sentiment of the tweets in which they occur. We engaged 83 human annotators to label over 1.6 million tweets in 13 European languages by the sentiment polarity (negative, neutral, or positive). About 4% of the annotated tweets contain emojis. The sentiment analysis of the emojis allows us to draw several interesting conclusions. It turns out that most of the emojis are positive, especially the most popular ones. The sentiment distribution of the tweets with and without emojis is significantly different. The inter-annotator agreement on the tweets with emojis is higher. Emojis tend to occur at the end of the tweets, and their sentiment polarity increases with the distance. We observe no significant differences in the emoji rankings between the 13 languages and the Emoji Sentiment Ranking. Consequently, we propose our Emoji Sentiment Ranking as a European language-independent resource for automated sentiment analysis. Finally, the paper provides a formalization of sentiment and a novel visualization in the form of a sentiment bar.