 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodSEM: Large Language Model Specialized in Food Named-Entity Linking
Sep 26, 2025This paper introduces FoodSEM, a state-of-the-art fine-tuned open-source large language model (LLM) for named-entity linking (NEL) to food-related ontologies. To the best of our knowledge, food NEL is a task that cannot be accurately solved by state-of-the-art general-purpose (large) language models or custom domain-specific models/systems. Through an instruction-response (IR) scenario, FoodSEM links food-related entities mentioned in a text to several ontologies, including FoodOn, SNOMED-CT, and the Hansard taxonomy. The FoodSEM model achieves state-of-the-art performance compared to related models/systems, with F1 scores even reaching 98% on some ontologies and datasets. The presented comparative analyses against zero-shot, one-shot, and few-shot LLM prompting baselines further highlight FoodSEM's superior performance over its non-fine-tuned version. By making FoodSEM and its related resources publicly available, the main contributions of this article include (1) publishing a food-annotated corpora into an IR format suitable for LLM fine-tuning/evaluation, (2) publishing a robust model to advance the semantic understanding of text in the food domain, and (3) providing a strong baseline on food NEL for future benchmarking.
SEKE: Specialised Experts for Keyword Extraction
Dec 18, 2024



Keyword extraction involves identifying the most descriptive words in a document, allowing automatic categorisation and summarisation of large quantities of diverse textual data. Relying on the insight that real-world keyword detection often requires handling of diverse content, we propose a novel supervised keyword extraction approach based on the mixture of experts (MoE) technique. MoE uses a learnable routing sub-network to direct information to specialised experts, allowing them to specialize in distinct regions of the input space. SEKE, a mixture of Specialised Experts for supervised Keyword Extraction, uses DeBERTa as the backbone model and builds on the MoE framework, where experts attend to each token, by integrating it with a recurrent neural network (RNN), to allow successful extraction even on smaller corpora, where specialisation is harder due to lack of training data. The MoE framework also provides an insight into inner workings of individual experts, enhancing the explainability of the approach. We benchmark SEKE on multiple English datasets, achieving state-of-the-art performance compared to strong supervised and unsupervised baselines. Our analysis reveals that depending on data size and type, experts specialize in distinct syntactic and semantic components, such as punctuation, stopwords, parts-of-speech, or named entities. Code is available at: https://github.com/matejMartinc/SEKE_keyword_extraction
Multi-Task Learning for Features Extraction in Financial Annual Reports
Apr 08, 2024



For assessing various performance indicators of companies, the focus is shifting from strictly financial (quantitative) publicly disclosed information to qualitative (textual) information. This textual data can provide valuable weak signals, for example through stylistic features, which can complement the quantitative data on financial performance or on Environmental, Social and Governance (ESG) criteria. In this work, we use various multi-task learning methods for financial text classification with the focus on financial sentiment, objectivity, forward-looking sentence prediction and ESG-content detection. We propose different methods to combine the information extracted from training jointly on different tasks; our best-performing method highlights the positive effect of explicitly adding auxiliary task predictions as features for the final target task during the multi-task training. Next, we use these classifiers to extract textual features from annual reports of FTSE350 companies and investigate the link between ESG quantitative scores and these features.
Semantic change detection for Slovene language: a novel dataset and an approach based on optimal transport
Feb 26, 2024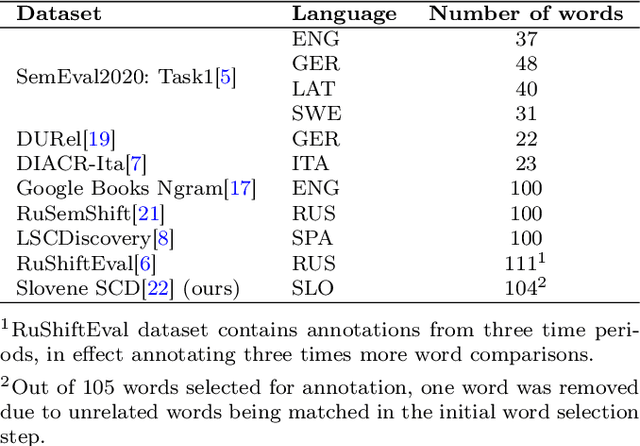

In this paper, we focus on the detection of semantic changes in Slovene, a less resourced Slavic language with two million speakers. Detecting and tracking semantic changes provides insights into the evolution of the language caused by changes in society and culture. Recently, several systems have been proposed to aid in this study, but all depend on manually annotated gold standard datasets for evaluation. In this paper, we present the first Slovene dataset for evaluating semantic change detection systems, which contains aggregated semantic change scores for 104 target words obtained from more than 3000 manually annotated sentence pairs. We evaluate several existing semantic change detection methods on this dataset and also propose a novel approach based on optimal transport that improves on the existing state-of-the-art systems with an error reduction rate of 22.8%.
The Recent Advances in Automatic Term Extraction: A survey
Jan 17, 2023Automatic term extraction (ATE) is a Natural Language Processing (NLP) task that eases the effort of manually identifying terms from domain-specific corpora by providing a list of candidate terms. As units of knowledge in a specific field of expertise, extracted terms are not only beneficial for several terminographical tasks, but also support and improve several complex downstream tasks, e.g., information retrieval, machine translation, topic detection, and sentiment analysis. ATE systems, along with annotated datasets, have been studied and developed widely for decades, but recently we observed a surge in novel neural systems for the task at hand. Despite a large amount of new research on ATE, systematic survey studies covering novel neural approaches are lacking. We present a comprehensive survey of deep learning-based approaches to ATE, with a focus on Transformer-based neural models. The study also offers a comparison between these systems and previous ATE approaches, which were based on feature engineering and non-neural supervised learning algorithms.
Ensembling Transformers for Cross-domain Automatic Term Extraction
Dec 12, 2022Automatic term extraction plays an essential role in domain language understanding and several natural language processing downstream tasks. In this paper, we propose a comparative study on the predictive power of Transformers-based pretrained language models toward term extraction in a multi-language cross-domain setting. Besides evaluating the ability of monolingual models to extract single- and multi-word terms, we also experiment with ensembles of mono- and multilingual models by conducting the intersection or union on the term output sets of different language models. Our experiments have been conducted on the ACTER corpus covering four specialized domains (Corruption, Wind energy, Equitation, and Heart failure) and three languages (English, French, and Dutch), and on the RSDO5 Slovenian corpus covering four additional domains (Biomechanics, Chemistry, Veterinary, and Linguistics). The results show that the strategy of employing monolingual models outperforms the state-of-the-art approaches from the related work leveraging multilingual models, regarding all the languages except Dutch and French if the term extraction task excludes the extraction of named entity terms. Furthermore, by combining the outputs of the two best performing models, we achieve significant improvements.
* 11 pages including references, 3 figures, 2 tables
A bilingual approach to specialised adjectives through word embeddings in the karstology domain
Mar 31, 2022

We present an experiment in extracting adjectives which express a specific semantic relation using word embeddings. The results of the experiment are then thoroughly analysed and categorised into groups of adjectives exhibiting formal or semantic similarity. The experiment and analysis are performed for English and Croatian in the domain of karstology using data sets and methods developed in the TermFrame project. The main original contributions of the article are twofold: firstly, proposing a new and promising method of extracting semantically related words relevant for terminology, and secondly, providing a detailed evaluation of the output so that we gain a better understanding of the domain-specific semantic structures on the one hand and the types of similarities extracted by word embeddings on the other.
Out of Thin Air: Is Zero-Shot Cross-Lingual Keyword Detection Better Than Unsupervised?
Feb 14, 2022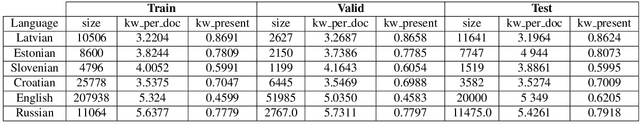


Keyword extraction is the task of retrieving words that are essential to the content of a given document. Researchers proposed various approaches to tackle this problem. At the top-most level, approaches are divided into ones that require training - supervised and ones that do not - unsupervised. In this study, we are interested in settings, where for a language under investigation, no training data is available. More specifically, we explore whether pretrained multilingual language models can be employed for zero-shot cross-lingual keyword extraction on low-resource languages with limited or no available labeled training data and whether they outperform state-of-the-art unsupervised keyword extractors. The comparison is conducted on six news article datasets covering two high-resource languages, English and Russian, and four low-resource languages, Croatian, Estonian, Latvian, and Slovenian. We find that the pretrained models fine-tuned on a multilingual corpus covering languages that do not appear in the test set (i.e. in a zero-shot setting), consistently outscore unsupervised models in all six languages.
Extending Neural Keyword Extraction with TF-IDF tagset matching
Jan 31, 2021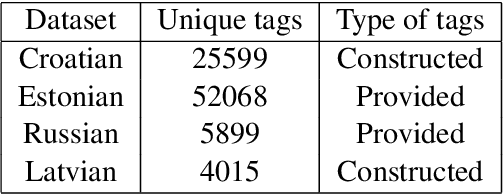

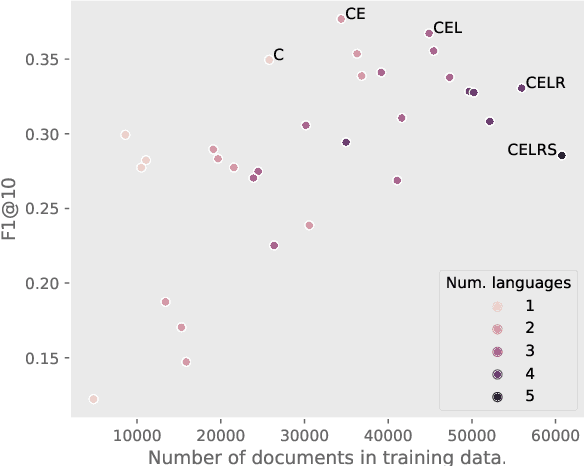
Keyword extraction is the task of identifying words (or multi-word expressions) that best describe a given document and serve in news portals to link articles of similar topics. In this work we develop and evaluate our methods on four novel data sets covering less represented, morphologically-rich languages in European news media industry (Croatian, Estonian, Latvian and Russian). First, we perform evaluation of two supervised neural transformer-based methods (TNT-KID and BERT+BiLSTM CRF) and compare them to a baseline TF-IDF based unsupervised approach. Next, we show that by combining the keywords retrieved by both neural transformer based methods and extending the final set of keywords with an unsupervised TF-IDF based technique, we can drastically improve the recall of the system, making it appropriate to be used as a recommendation system in the media house environment.
COVID-19 therapy target discovery with context-aware literature mining
Jul 30, 2020


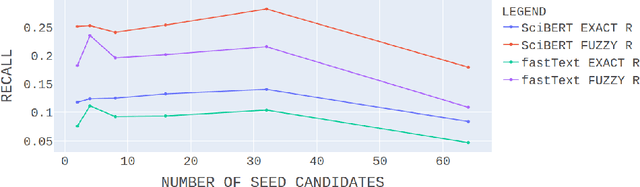
The abundance of literature related to the widespread COVID-19 pandemic is beyond manual inspection of a single expert. Development of systems, capable of automatically processing tens of thousands of scientific publications with the aim to enrich existing empirical evidence with literature-based associations is challenging and relevant. We propose a system for contextualization of empirical expression data by approximating relations between entities, for which representations were learned from one of the largest COVID-19-related literature corpora. In order to exploit a larger scientific context by transfer learning, we propose a novel embedding generation technique that leverages SciBERT language model pretrained on a large multi-domain corpus of scientific publications and fine-tuned for domain adaptation on the CORD-19 dataset. The conducted manual evaluation by the medical expert and the quantitative evaluation based on therapy targets identified in the related work suggest that the proposed method can be successfully employed for COVID-19 therapy target discovery and that it outperforms the baseline FastText method by a large margin.