 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Thin Air: Is Zero-Shot Cross-Lingual Keyword Detection Better Than Unsupervised?
Paper and Code
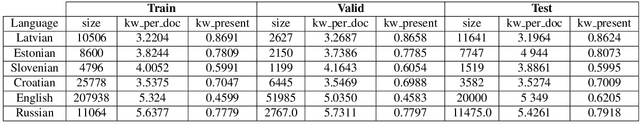


Keyword extraction is the task of retrieving words that are essential to the content of a given document. Researchers proposed various approaches to tackle this problem. At the top-most level, approaches are divided into ones that require training - supervised and ones that do not - unsupervised. In this study, we are interested in settings, where for a language under investigation, no training data is available. More specifically, we explore whether pretrained multilingual language models can be employed for zero-shot cross-lingual keyword extraction on low-resource languages with limited or no available labeled training data and whether they outperform state-of-the-art unsupervised keyword extractors. The comparison is conducted on six news article datasets covering two high-resource languages, English and Russian, and four low-resource languages, Croatian, Estonian, Latvian, and Slovenian. We find that the pretrained models fine-tuned on a multilingual corpus covering languages that do not appear in the test set (i.e. in a zero-shot setting), consistently outscore unsupervised models in all six languages.