 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Literature-Based Discovery Great Again through Reproducible Pipelines
Feb 23, 2025By connecting disparate sources of scientific literature, literature\-/based discovery (LBD) methods help to uncover new knowledge and generate new research hypotheses that cannot be found from domain-specific documents alone. Our work focuses on bisociative LBD methods that combine bisociative reasoning with LBD techniques. The paper presents LBD through the lens of reproducible science to ensure the reproducibility of LBD experiments, overcome the inconsistent use of benchmark datasets and methods, trigger collaboration, and advance the LBD field toward more robust and impactful scientific discoveries. The main novelty of this study is a collection of Jupyter Notebooks that illustrate the steps of the bisociative LBD process, including data acquisition, text preprocessing, hypothesis formulation, and evaluation. The contributed notebooks implement a selection of traditional LBD approaches, as well as our own ensemble-based, outlier-based, and link prediction-based approaches. The reader can benefit from hands-on experience with LBD through open access to benchmark datasets, code reuse, and a ready-to-run Docker recipe that ensures reproducibility of the selected LBD methods.
AHAM: Adapt, Help, Ask, Model -- Harvesting LLMs for literature mining
Dec 25, 2023In an era marked by a rapid increase in scientific publications, researchers grapple with the challenge of keeping pace with field-specific advances. We present the `AHAM' methodology and a metric that guides the domain-specific \textbf{adapt}ation of the BERTopic topic modeling framework to improve scientific text analysis. By utilizing the LLaMa2 generative language model, we generate topic definitions via one-shot learning by crafting prompts with the \textbf{help} of domain experts to guide the LLM for literature mining by \textbf{asking} it to model the topic names. For inter-topic similarity evaluation, we leverage metrics from language generation and translation processes to assess lexical and semantic similarity of the generated topics. Our system aims to reduce both the ratio of outlier topics to the total number of topics and the similarity between topic definitions. The methodology has been assessed on a newly gathered corpus of scientific papers on literature-based discovery. Through rigorous evaluation by domain experts, AHAM has been validated as effective in uncovering intriguing and novel insights within broad research areas. We explore the impact of domain adaptation of sentence-transformers for the task of topic \textbf{model}ing using two datasets, each specialized to specific scientific domains within arXiv and medarxiv. We evaluate the impact of data size, the niche of adaptation, and the importance of domain adaptation. Our results suggest a strong interaction between domain adaptation and topic modeling precision in terms of outliers and topic definitions.
COVID-19 therapy target discovery with context-aware literature mining
Jul 30, 2020


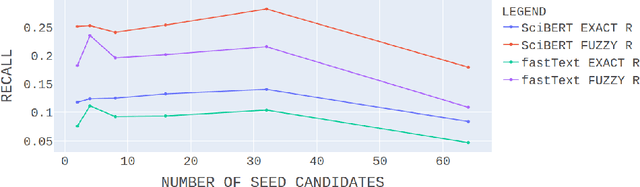
The abundance of literature related to the widespread COVID-19 pandemic is beyond manual inspection of a single expert. Development of systems, capable of automatically processing tens of thousands of scientific publications with the aim to enrich existing empirical evidence with literature-based associations is challenging and relevant. We propose a system for contextualization of empirical expression data by approximating relations between entities, for which representations were learned from one of the largest COVID-19-related literature corpora. In order to exploit a larger scientific context by transfer learning, we propose a novel embedding generation technique that leverages SciBERT language model pretrained on a large multi-domain corpus of scientific publications and fine-tuned for domain adaptation on the CORD-19 dataset. The conducted manual evaluation by the medical expert and the quantitative evaluation based on therapy targets identified in the related work suggest that the proposed method can be successfully employed for COVID-19 therapy target discovery and that it outperforms the baseline FastText method by a large margin.