 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Graph Construction Enables Robust Spectral Clustering of Texts
Mar 05, 2026Neighborhood graphs are a critical but often fragile step in spectral clustering of text embeddings. On realistic text datasets, standard $k$-NN graphs can contain many disconnected components at practical sparsity levels (small $k$), making spectral clustering degenerate and sensitive to hyperparameters. We introduce a simple incremental $k$-NN graph construction that preserves connectivity by design: each new node is linked to its $k$ nearest previously inserted nodes, which guarantees a connected graph for any $k$. We provide an inductive proof of connectedness and discuss implications for incremental updates when new documents arrive. We validate the approach on spectral clustering of SentenceTransformer embeddings using Laplacian eigenmaps across six clustering datasets from the Massive Text Embedding Benchmark. Compared to standard $k$-NN graphs, our method outperforms in the low-$k$ regime where disconnected components are prevalent, and matches standard $k$-NN at larger $k$.
From Symbolic to Neural and Back: Exploring Knowledge Graph-Large Language Model Synergies
Jun 11, 2025Integrating structured knowledge from Knowledge Graphs (KGs) into Large Language Models (LLMs) enhances factual grounding and reasoning capabilities. This survey paper systematically examines the synergy between KGs and LLMs, categorizing existing approaches into two main groups: KG-enhanced LLMs, which improve reasoning, reduce hallucinations, and enable complex question answering; and LLM-augmented KGs, which facilitate KG construction, completion, and querying. Through comprehensive analysis, we identify critical gaps and highlight the mutual benefits of structured knowledge integration. Compared to existing surveys, our study uniquely emphasizes scalability, computational efficiency, and data quality. Finally, we propose future research directions, including neuro-symbolic integration, dynamic KG updating, data reliability, and ethical considerations, paving the way for intelligent systems capable of managing more complex real-world knowledge tasks.
Extracting domain-specific terms using contextual word embeddings
Feb 24, 2025



Automated terminology extraction refers to the task of extracting meaningful terms from domain-specific texts. This paper proposes a novel machine learning approach to terminology extraction, which combines features from traditional term extraction systems with novel contextual features derived from contextual word embeddings. Instead of using a predefined list of part-of-speech patterns, we first analyse a new term-annotated corpus RSDO5 for the Slovenian language and devise a set of rules for term candidate selection and then generate statistical, linguistic and context-based features. We use a support-vector machine algorithm to train a classification model, evaluate it on the four domains (biomechanics, linguistics, chemistry, veterinary) of the RSDO5 corpus and compare the results with state-of-art term extraction approaches for the Slovenian language. Our approach provides significant improvements in terms of F1 score over the previous state-of-the-art, which proves that contextual word embeddings are valuable for improving term extraction.
Make Literature-Based Discovery Great Again through Reproducible Pipelines
Feb 23, 2025By connecting disparate sources of scientific literature, literature\-/based discovery (LBD) methods help to uncover new knowledge and generate new research hypotheses that cannot be found from domain-specific documents alone. Our work focuses on bisociative LBD methods that combine bisociative reasoning with LBD techniques. The paper presents LBD through the lens of reproducible science to ensure the reproducibility of LBD experiments, overcome the inconsistent use of benchmark datasets and methods, trigger collaboration, and advance the LBD field toward more robust and impactful scientific discoveries. The main novelty of this study is a collection of Jupyter Notebooks that illustrate the steps of the bisociative LBD process, including data acquisition, text preprocessing, hypothesis formulation, and evaluation. The contributed notebooks implement a selection of traditional LBD approaches, as well as our own ensemble-based, outlier-based, and link prediction-based approaches. The reader can benefit from hands-on experience with LBD through open access to benchmark datasets, code reuse, and a ready-to-run Docker recipe that ensures reproducibility of the selected LBD methods.
HorNets: Learning from Discrete and Continuous Signals with Routing Neural Networks
Jan 24, 2025Construction of neural network architectures suitable for learning from both continuous and discrete tabular data is a challenging research endeavor. Contemporary high-dimensional tabular data sets are often characterized by a relatively small instance count, requiring data-efficient learning. We propose HorNets (Horn Networks), a neural network architecture with state-of-the-art performance on synthetic and real-life data sets from scarce-data tabular domains. HorNets are based on a clipped polynomial-like activation function, extended by a custom discrete-continuous routing mechanism that decides which part of the neural network to optimize based on the input's cardinality. By explicitly modeling parts of the feature combination space or combining whole space in a linear attention-like manner, HorNets dynamically decide which mode of operation is the most suitable for a given piece of data with no explicit supervision. This architecture is one of the few approaches that reliably retrieves logical clauses (including noisy XNOR) and achieves state-of-the-art classification performance on 14 real-life biomedical high-dimensional data sets. HorNets are made freely available under a permissive license alongside a synthetic generator of categorical benchmarks.
Evaluating and explaining training strategies for zero-shot cross-lingual news sentiment analysis
Sep 30, 2024
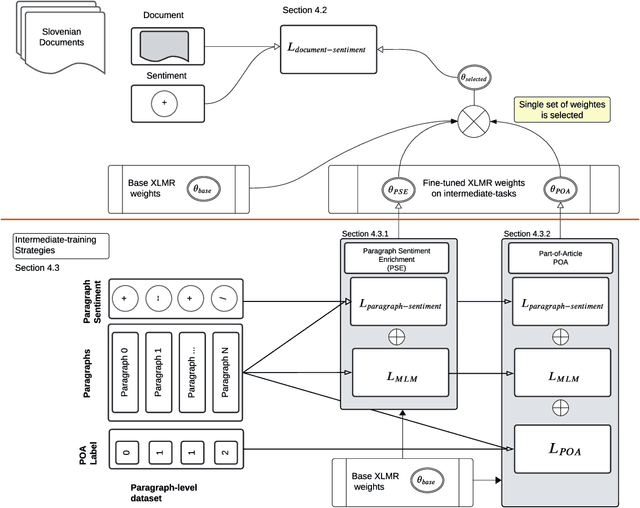
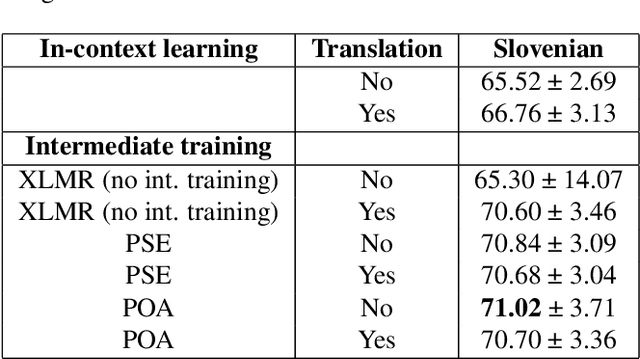
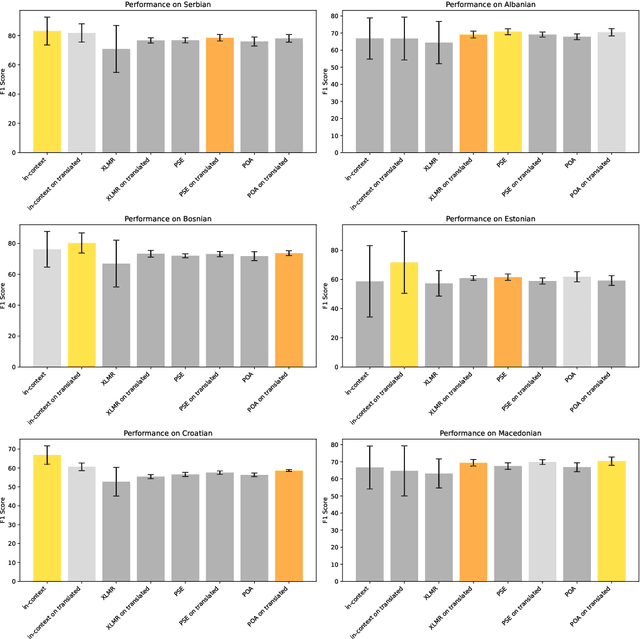
We investigate zero-shot cross-lingual news sentiment detection, aiming to develop robust sentiment classifiers that can be deployed across multiple languages without target-language training data. We introduce novel evaluation datasets in several less-resourced languages, and experiment with a range of approaches including the use of machine translation; in-context learning with large language models; and various intermediate training regimes including a novel task objective, POA, that leverages paragraph-level information. Our results demonstrate significant improvements over the state of the art, with in-context learning generally giving the best performance, but with the novel POA approach giving a competitive alternative with much lower computational overhead. We also show that language similarity is not in itself sufficient for predicting the success of cross-lingual transfer, but that similarity in semantic content and structure can be equally important.
AHAM: Adapt, Help, Ask, Model -- Harvesting LLMs for literature mining
Dec 25, 2023In an era marked by a rapid increase in scientific publications, researchers grapple with the challenge of keeping pace with field-specific advances. We present the `AHAM' methodology and a metric that guides the domain-specific \textbf{adapt}ation of the BERTopic topic modeling framework to improve scientific text analysis. By utilizing the LLaMa2 generative language model, we generate topic definitions via one-shot learning by crafting prompts with the \textbf{help} of domain experts to guide the LLM for literature mining by \textbf{asking} it to model the topic names. For inter-topic similarity evaluation, we leverage metrics from language generation and translation processes to assess lexical and semantic similarity of the generated topics. Our system aims to reduce both the ratio of outlier topics to the total number of topics and the similarity between topic definitions. The methodology has been assessed on a newly gathered corpus of scientific papers on literature-based discovery. Through rigorous evaluation by domain experts, AHAM has been validated as effective in uncovering intriguing and novel insights within broad research areas. We explore the impact of domain adaptation of sentence-transformers for the task of topic \textbf{model}ing using two datasets, each specialized to specific scientific domains within arXiv and medarxiv. We evaluate the impact of data size, the niche of adaptation, and the importance of domain adaptation. Our results suggest a strong interaction between domain adaptation and topic modeling precision in terms of outliers and topic definitions.
Latent Graphs for Semi-Supervised Learning on Biomedical Tabular Data
Oct 14, 2023



In the domain of semi-supervised learning, the current approaches insufficiently exploit the potential of considering inter-instance relationships among (un)labeled data. In this work, we address this limitation by providing an approach for inferring latent graphs that capture the intrinsic data relationships. By leveraging graph-based representations, our approach facilitates the seamless propagation of information throughout the graph, effectively incorporating global and local knowledge. Through evaluations on biomedical tabular datasets, we compare the capabilities of our approach to other contemporary methods. Our work demonstrates the significance of inter-instance relationship discovery as practical means for constructing robust latent graphs to enhance semi-supervised learning techniques. The experiments show that the proposed methodology outperforms contemporary state-of-the-art methods for (semi-)supervised learning on three biomedical datasets.
DDeMON: Ontology-based function prediction by Deep Learning from Dynamic Multiplex Networks
Feb 08, 2023



Biological systems can be studied at multiple levels of information, including gene, protein, RNA and different interaction networks levels. The goal of this work is to explore how the fusion of systems' level information with temporal dynamics of gene expression can be used in combination with non-linear approximation power of deep neural networks to predict novel gene functions in a non-model organism potato \emph{Solanum tuberosum}. We propose DDeMON (Dynamic Deep learning from temporal Multiplex Ontology-annotated Networks), an approach for scalable, systems-level inference of function annotation using time-dependent multiscale biological information. The proposed method, which is capable of considering billions of potential links between the genes of interest, was applied on experimental gene expression data and the background knowledge network to reliably classify genes with unknown function into five different functional ontology categories, linked to the experimental data set. Predicted novel functions of genes were validated using extensive protein domain search approach.
Link Analysis meets Ontologies: Are Embeddings the Answer?
Nov 23, 2021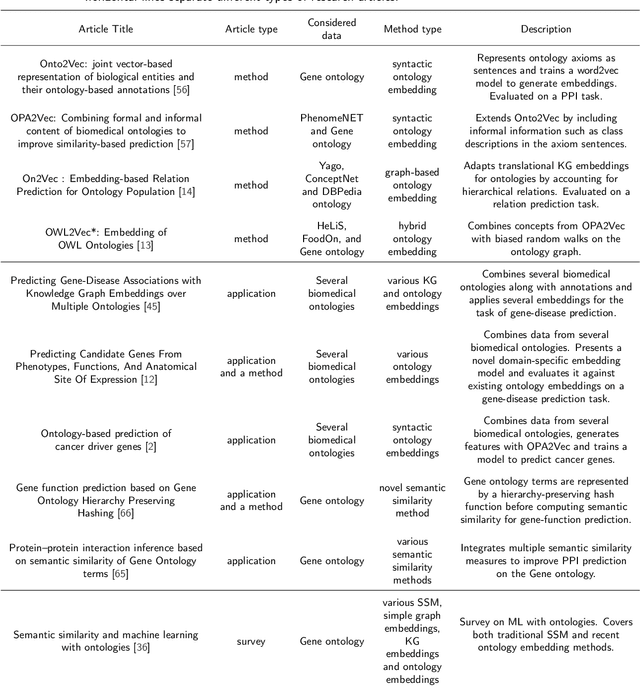
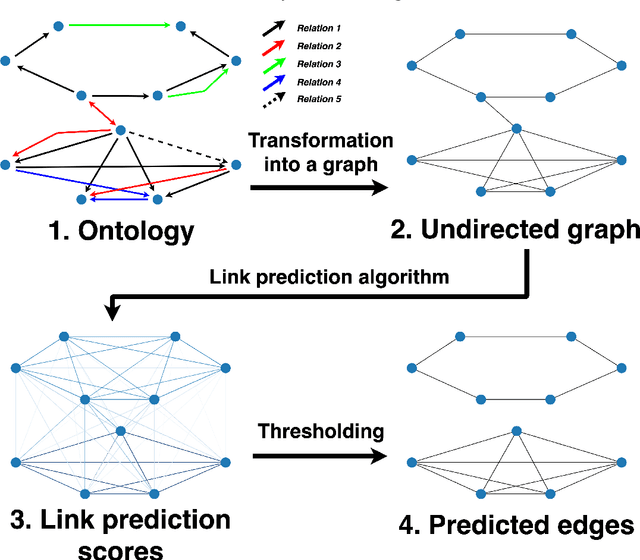
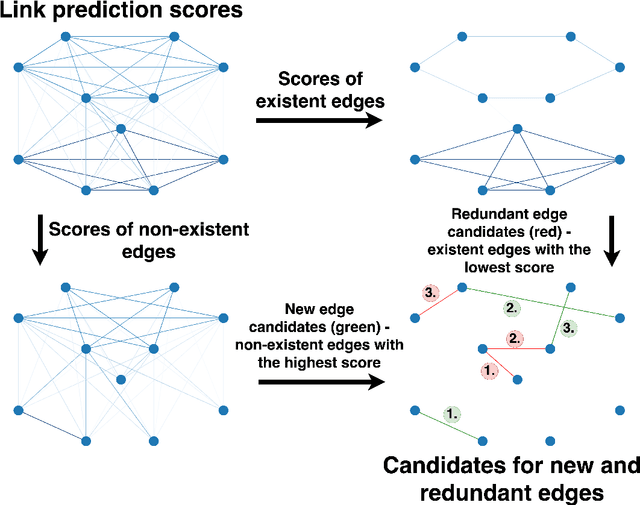
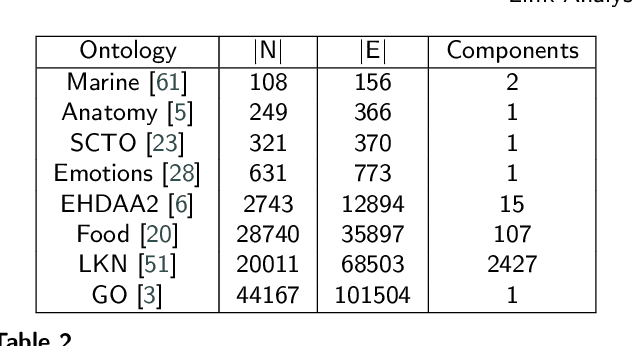
The increasing amounts of semantic resources offer valuable storage of human knowledge; however, the probability of wrong entries increases with the increased size. The development of approaches that identify potentially spurious parts of a given knowledge base is thus becoming an increasingly important area of interest. In this work, we present a systematic evaluation of whether structure-only link analysis methods can already offer a scalable means to detecting possible anomalies, as well as potentially interesting novel relation candidates. Evaluating thirteen methods on eight different semantic resources, including Gene Ontology, Food Ontology, Marine Ontology and similar, we demonstrated that structure-only link analysis could offer scalable anomaly detection for a subset of the data sets. Further, we demonstrated that by considering symbolic node embedding, explanations of the predictions (links) could be obtained, making this branch of methods potentially more valuable than the black-box only ones. To our knowledge, this is currently one of the most extensive systematic studies of the applicability of different types of link analysis methods across semantic resources from different domains.