 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDeMON: Ontology-based function prediction by Deep Learning from Dynamic Multiplex Networks
Feb 08, 2023



Biological systems can be studied at multiple levels of information, including gene, protein, RNA and different interaction networks levels. The goal of this work is to explore how the fusion of systems' level information with temporal dynamics of gene expression can be used in combination with non-linear approximation power of deep neural networks to predict novel gene functions in a non-model organism potato \emph{Solanum tuberosum}. We propose DDeMON (Dynamic Deep learning from temporal Multiplex Ontology-annotated Networks), an approach for scalable, systems-level inference of function annotation using time-dependent multiscale biological information. The proposed method, which is capable of considering billions of potential links between the genes of interest, was applied on experimental gene expression data and the background knowledge network to reliably classify genes with unknown function into five different functional ontology categories, linked to the experimental data set. Predicted novel functions of genes were validated using extensive protein domain search approach.
Symbolic Graph Embedding using Frequent Pattern Mining
Oct 29, 2019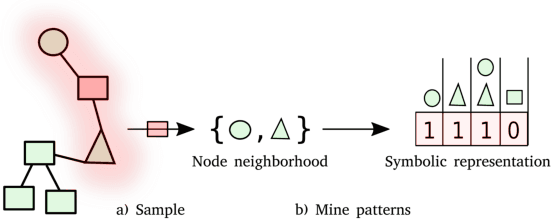
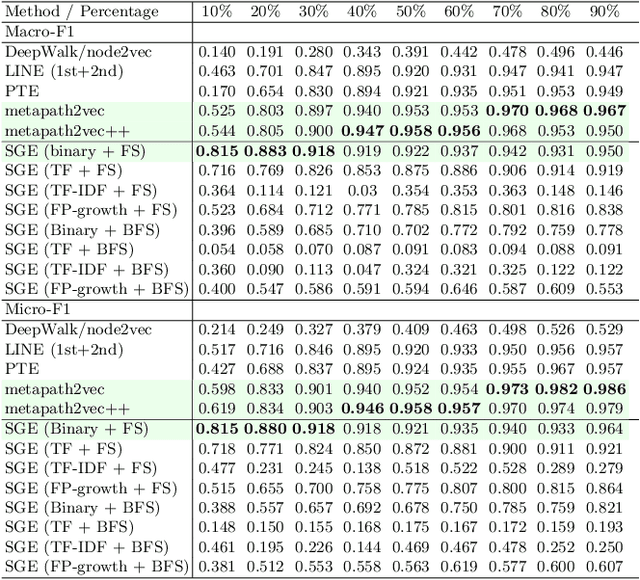
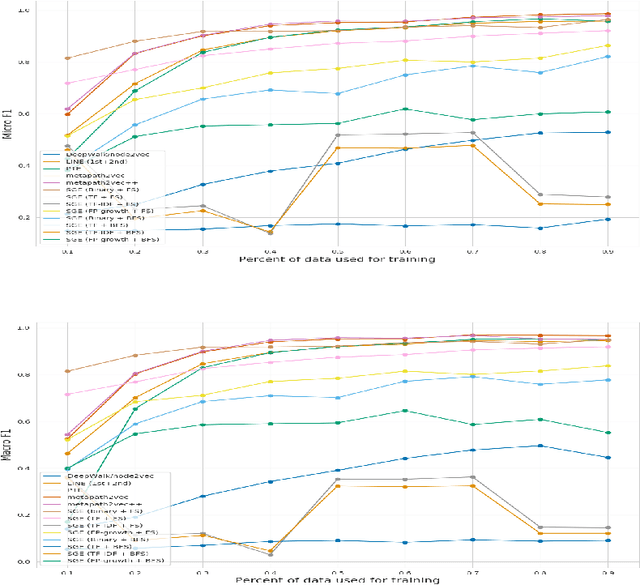

Relational data mining is becoming ubiquitous in many fields of study. It offers insights into behaviour of complex, real-world systems which cannot be modeled directly using propositional learning. We propose Symbolic Graph Embedding (SGE), an algorithm aimed to learn symbolic node representations. Built on the ideas from the field of inductive logic programming, SGE first samples a given node's neighborhood and interprets it as a transaction database, which is used for frequent pattern mining to identify logical conjuncts of items that co-occur frequently in a given context. Such patterns are in this work used as features to represent individual nodes, yielding interpretable, symbolic node embeddings. The proposed SGE approach on a venue classification task outperforms shallow node embedding methods such as DeepWalk, and performs similarly to metapath2vec, a black-box representation learner that can exploit node and edge types in a given graph. The proposed SGE approach performs especially well when small amounts of data are used for learning, scales to graphs with millions of nodes and edges, and can be run on an of-the-shelf laptop.
Embedding-based Silhouette Community Detection
Jul 17, 2019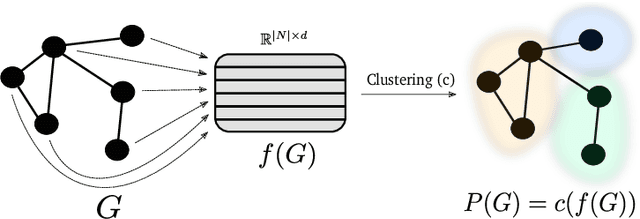
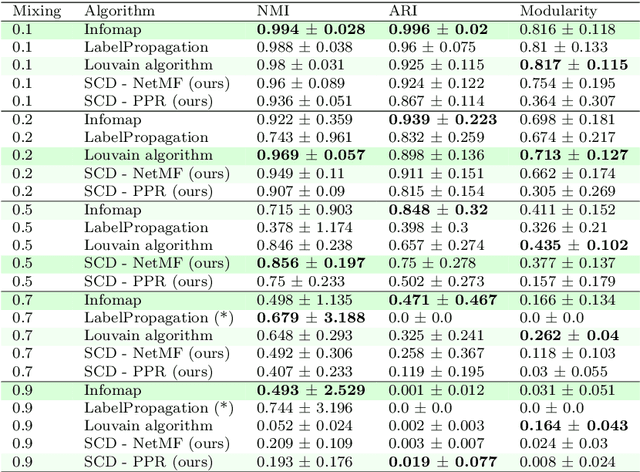

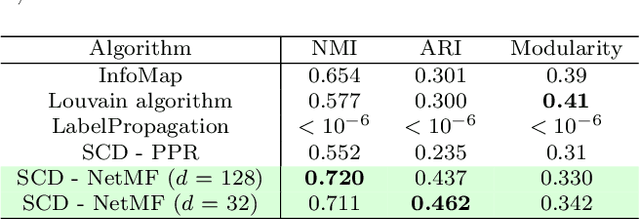
Mining complex data in the form of networks is of increasing interest in many scientific disciplines. Network communities correspond to densely connected subnetworks, and often represent key functional parts of real-world systems. In this work, we propose Silhouette Community Detection (SCD), an approach for detecting communities, based on clustering of network node embeddings, i.e. real valued representations of nodes derived from their neighborhoods. We investigate the performance of the proposed SCD approach on 234 synthetic networks, as well as on a real-life social network. Even though SCD is not based on any form of modularity optimization, it performs comparably or better than state-of-the-art community detection algorithms, such as the InfoMap and Louvain algorithms. Further, we demonstrate how SCD's outputs can be used along with domain ontologies in semantic subgroup discovery, yielding human-understandable explanations of communities detected in a real-life protein interaction network. Being embedding-based, SCD is widely applicable and can be tested out-of-the-box as part of many existing network learning and exploration pipelines.
Deep Node Ranking: Structural Network Embedding and End-to-End Node Classification
Apr 17, 2019

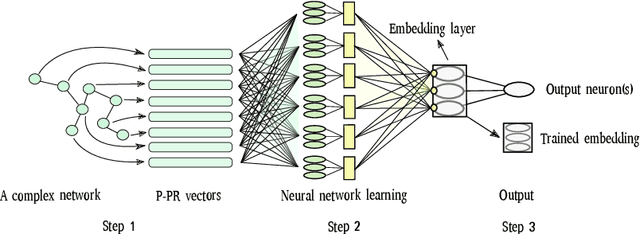
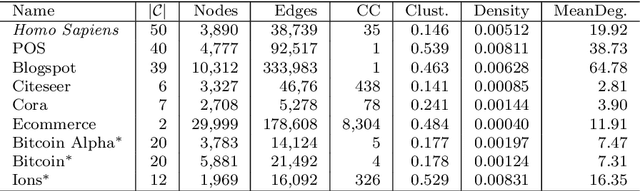
Complex networks are used as an abstraction for systems modeling in physics, biology, sociology, and other areas. We propose an algorithm, named Deep Node Ranking (DNR), based on fast personalized node ranking and raw approximation power of deep learning for learning supervised and unsupervised network embeddings as well as for classifying network nodes directly. The experiments demonstrate that the DNR algorithm is competitive with strong baselines on nine node classification benchmarks from the domains of molecular biology, finance, social media and language processing in terms of speed, as well as predictive accuracy. Embeddings, obtained by the proposed algorithm, are also a viable option for network visualization.
tax2vec: Constructing Interpretable Features from Taxonomies for Short Text Classification
Apr 07, 2019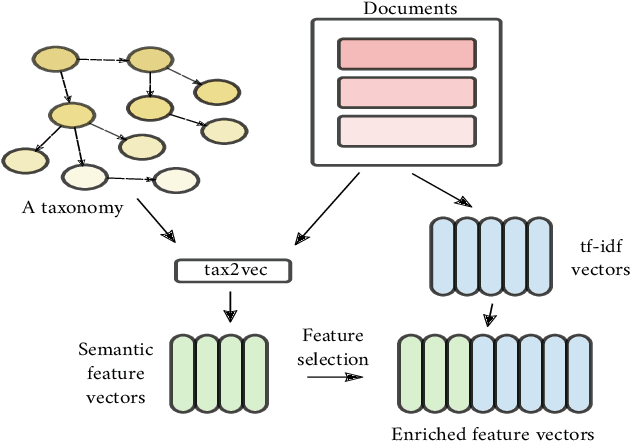
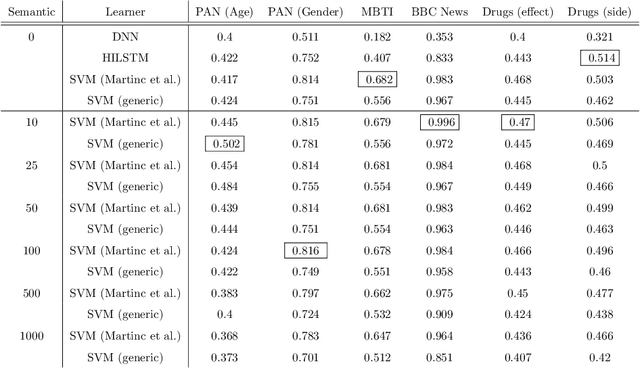
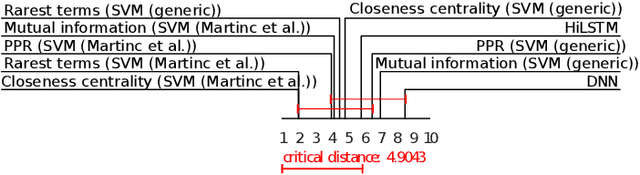
The use of background knowledge remains largely unexploited in many text classification tasks. In this work, we explore word taxonomies as means for constructing new semantic features, which may improve the performance and robustness of the learned classifiers. We propose tax2vec, a parallel algorithm for constructing taxonomy based features, and demonstrate its use on six short-text classification problems, including gender, age and personality type prediction, drug effectiveness and side effect prediction, and news topic prediction. The experimental results indicate that the interpretable features constructed using tax2vec can notably improve the performance of classifiers; the constructed features, in combination with fast, linear classifiers tested against strong baselines, such as hierarchical attention neural networks, achieved comparable or better classification results on short documents. Further, tax2vec can also serve for extraction of corpus-specific keywords. Finally, we investigated the semantic space of potential features where we observe a similarity with the well known Zipf's law.