 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024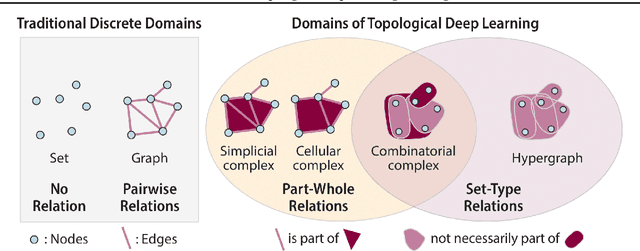
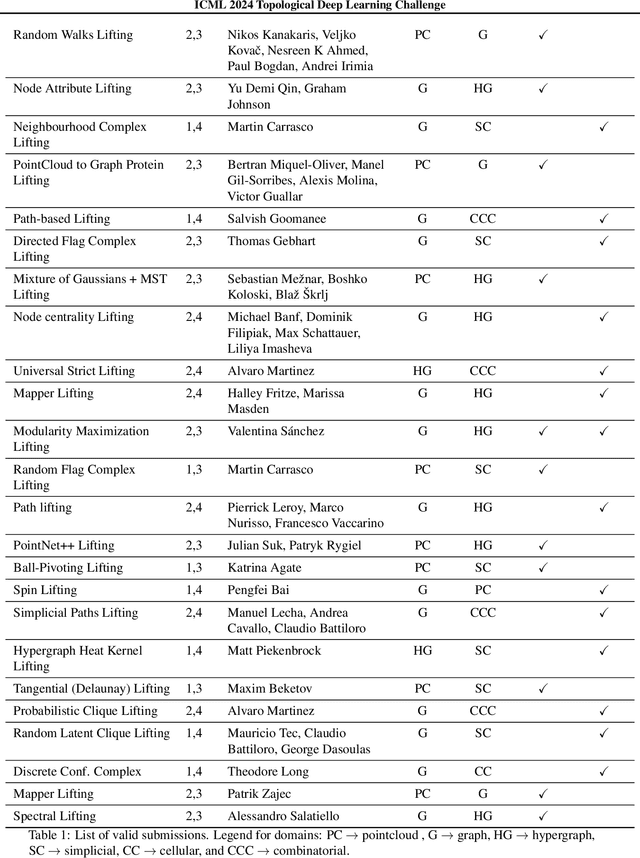
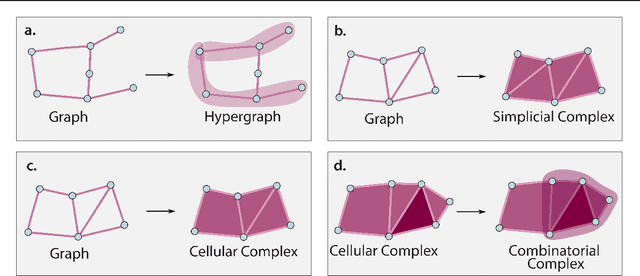
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Quantifying Behavioural Distance Between Mathematical Expressions
Aug 21, 2024Existing symbolic regression methods organize the space of candidate mathematical expressions primarily based on their syntactic, structural similarity. However, this approach overlooks crucial equivalences between expressions that arise from mathematical symmetries, such as commutativity, associativity, and distribution laws for arithmetic operations. Consequently, expressions with similar errors on a given data set are apart from each other in the search space. This leads to a rough error landscape in the search space that efficient local, gradient-based methods cannot explore. This paper proposes and implements a measure of a behavioral distance, BED, that clusters together expressions with similar errors. The experimental results show that the stochastic method for calculating BED achieves consistency with a modest number of sampled values for evaluating the expressions. This leads to computational efficiency comparable to the tree-based syntactic distance. Our findings also reveal that BED significantly improves the smoothness of the error landscape in the search space for symbolic regression.
Efficient Generator of Mathematical Expressions for Symbolic Regression
Feb 20, 2023We propose an approach to symbolic regression based on a novel variational autoencoder for generating hierarchical structures, HVAE. It combines simple atomic units with shared weights to recursively encode and decode the individual nodes in the hierarchy. Encoding is performed bottom-up and decoding top-down. We empirically show that HVAE can be trained efficiently with small corpora of mathematical expressions and can accurately encode expressions into a smooth low-dimensional latent space. The latter can be efficiently explored with various optimization methods to address the task of symbolic regression. Indeed, random search through the latent space of HVAE performs better than random search through expressions generated by manually crafted probabilistic grammars for mathematical expressions. Finally, EDHiE system for symbolic regression, which applies an evolutionary algorithm to the latent space of HVAE, reconstructs equations from a standard symbolic regression benchmark better than a state-of-the-art system based on a similar combination of deep learning and evolutionary algorithms.\v{z}
Link Analysis meets Ontologies: Are Embeddings the Answer?
Nov 23, 2021
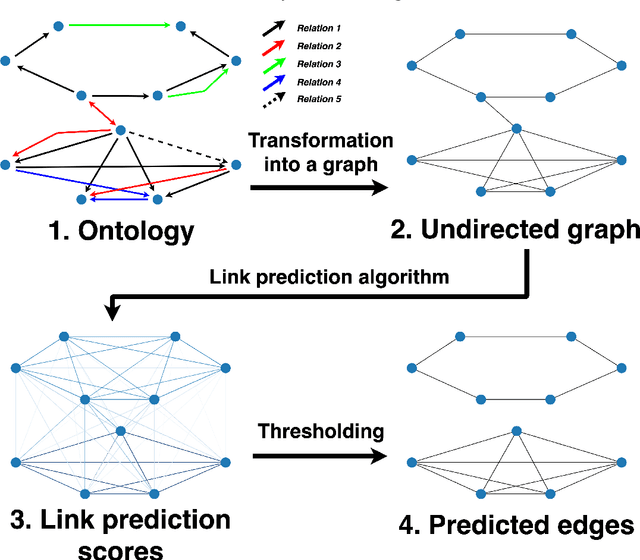
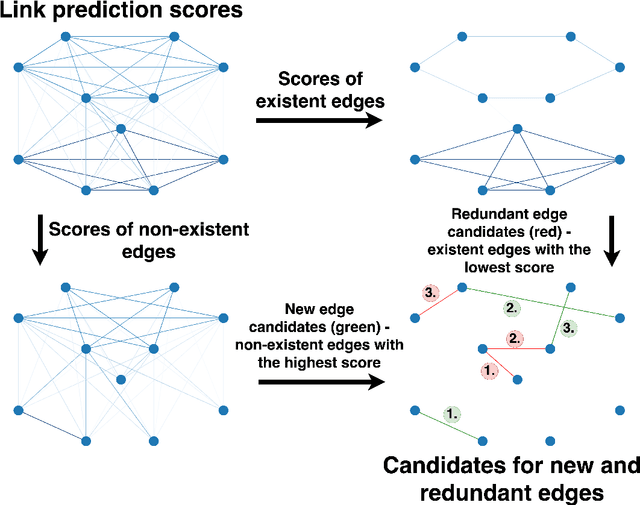
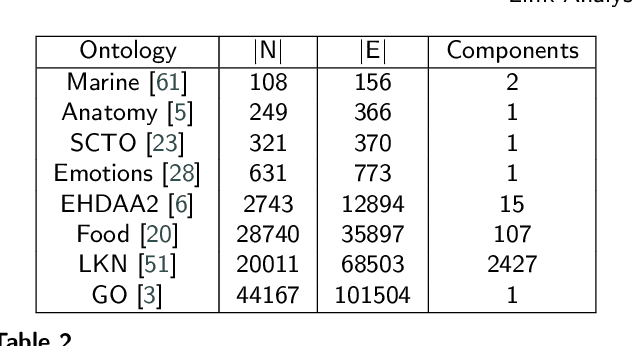
The increasing amounts of semantic resources offer valuable storage of human knowledge; however, the probability of wrong entries increases with the increased size. The development of approaches that identify potentially spurious parts of a given knowledge base is thus becoming an increasingly important area of interest. In this work, we present a systematic evaluation of whether structure-only link analysis methods can already offer a scalable means to detecting possible anomalies, as well as potentially interesting novel relation candidates. Evaluating thirteen methods on eight different semantic resources, including Gene Ontology, Food Ontology, Marine Ontology and similar, we demonstrated that structure-only link analysis could offer scalable anomaly detection for a subset of the data sets. Further, we demonstrated that by considering symbolic node embedding, explanations of the predictions (links) could be obtained, making this branch of methods potentially more valuable than the black-box only ones. To our knowledge, this is currently one of the most extensive systematic studies of the applicability of different types of link analysis methods across semantic resources from different domains.
Transfer Learning for Node Regression Applied to Spreading Prediction
May 03, 2021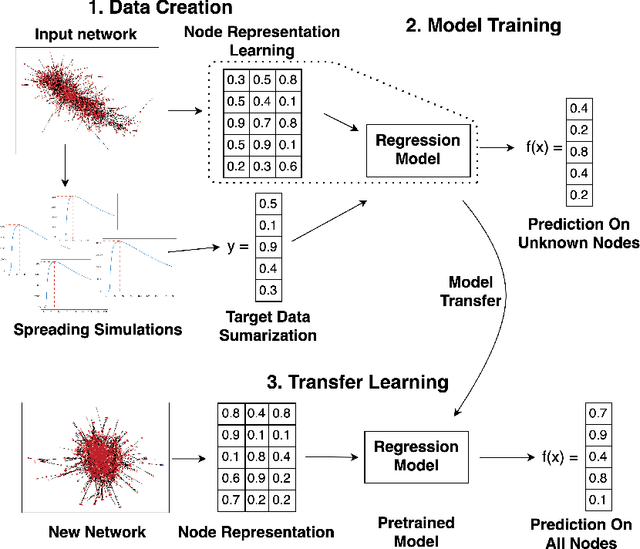



Understanding how information propagates in real-life complex networks yields a better understanding of dynamic processes such as misinformation or epidemic spreading. The recently introduced branch of machine learning methods for learning node representations offers many novel applications, one of them being the task of spreading prediction addressed in this paper. We explore the utility of the state-of-the-art node representation learners when used to assess the effects of spreading from a given node, estimated via extensive simulations. Further, as many real-life networks are topologically similar, we systematically investigate whether the learned models generalize to previously unseen networks, showing that in some cases very good model transfer can be obtained. This work is one of the first to explore transferability of the learned representations for the task of node regression; we show there exist pairs of networks with similar structure between which the trained models can be transferred (zero-shot), and demonstrate their competitive performance. To our knowledge, this is one of the first attempts to evaluate the utility of zero-shot transfer for the task of node regression.
Predicting Generalization in Deep Learning via Metric Learning -- PGDL Shared task
Dec 16, 2020The competition "Predicting Generalization in Deep Learning (PGDL)" aims to provide a platform for rigorous study of generalization of deep learning models and offer insight into the progress of understanding and explaining these models. This report presents the solution that was submitted by the user \emph{smeznar} which achieved the eight place in the competition. In the proposed approach, we create simple metrics and find their best combination with automatic testing on the provided dataset, exploring how combinations of various properties of the input neural network architectures can be used for the prediction of their generalization.
SNoRe: Scalable Unsupervised Learning of Symbolic Node Representations
Sep 08, 2020

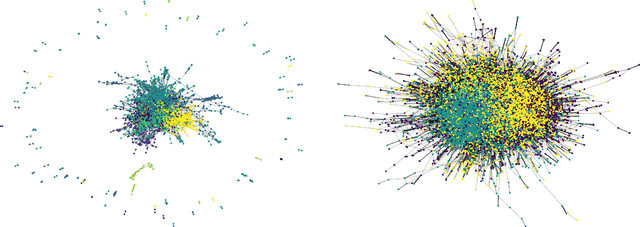

Learning from real-life complex networks is a lively research area, with recent advances in learning information-rich, low-dimensional network node representations. However, state-of-the-art methods offer little insights as the features that constitute the learned node representations are not interpretable and are as such less applicable to sensitive settings in biomedical or user profiling tasks, where bias detection is highly relevant. The proposed SNoRe (Symbolic Node Representations) algorithm is capable of learning symbolic, human-understandable representations of individual network nodes based on the similarity of neighborhood hashes to nodes chosen as features. SNoRe's interpretable features are suitable for direct explanation of individual predictions, which we demonstrate by coupling it with the widely used instance explanation tool SHAP to obtain nomograms representing the relevance of individual features for a given classification, which is to our knowledge one of the first such attempts in a structural node embedding setting. In the experimental evaluation on 11 real-life datasets, SNoRe proved to be competitive to strong baselines, such as variational graph autoencoders, node2vec and LINE. The vectorized implementation of SNoRe scales to large networks, making it suitable for many contemporary network analysis tasks.