 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrange Lab: Lowering Barriers to Data Mining through Embedded Interactive Workflows
Jun 08, 2026While visual programming of data analysis workflows has become an important vehicle for the democratization of data science, such systems remain largely confined to standalone applications and offer limited support for transitioning their visual analytics solutions into interactive web environments. As a result, data analysis pipelines are difficult to share, embed, and adapt into user-facing analytical tools. We present Orange Lab, a web-based collaborative environment for visual data analytics. At its core, Orange Lab enables users to visually construct machine learning workflows from modular components, where interactions in any component propagate seamlessly through the workflow, turning static pipelines into dynamic, reactive systems that support exploration and data-driven storytelling. Our key contribution is component exposition, a paradigm that allows authors to embed selected workflow components, or parts of their interfaces, into arbitrary web contexts, creating synchronized, interactive interfaces while hiding underlying workflow complexity. This enables the development of tailored analytical views and narrative-driven experiences that integrate data analysis directly into online materials. We demonstrate the approach through deployments in data literacy education, where embedded components guide students in hands-on exploration of machine learning concepts without requiring knowledge of the underlying system, showing that Orange Lab effectively lowers barriers to entry and supports the democratization of data science.
Link Analysis meets Ontologies: Are Embeddings the Answer?
Nov 23, 2021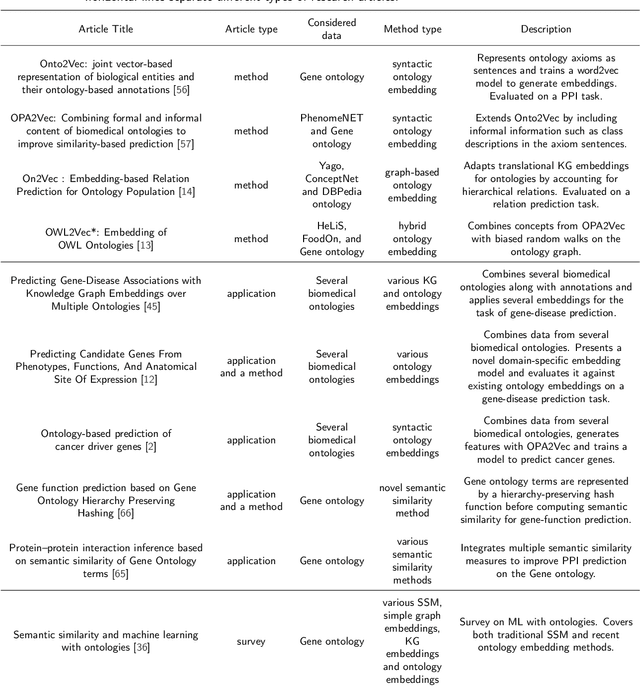
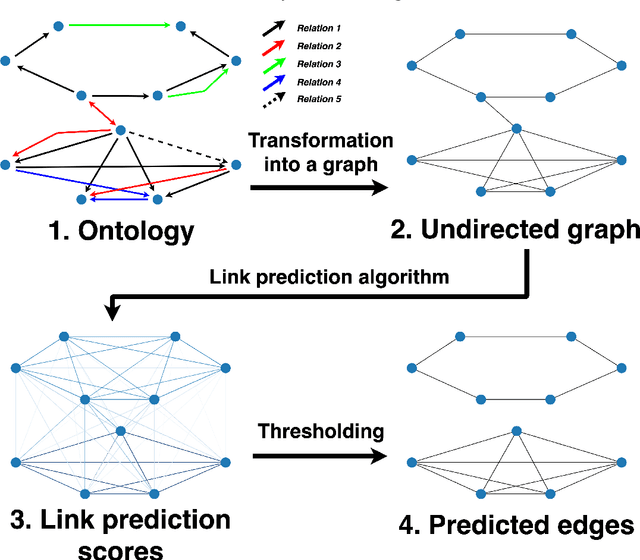
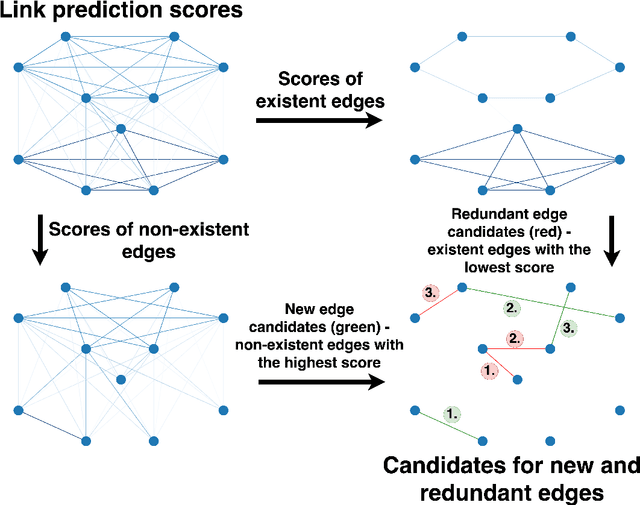
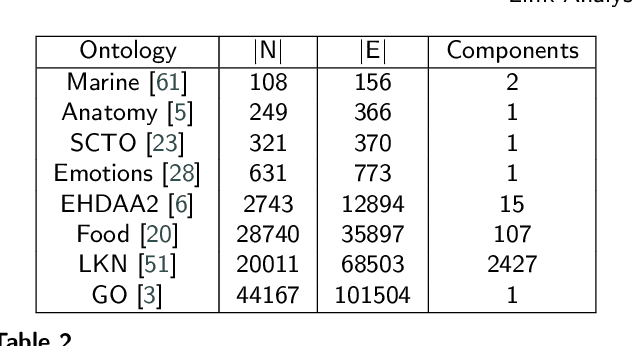
The increasing amounts of semantic resources offer valuable storage of human knowledge; however, the probability of wrong entries increases with the increased size. The development of approaches that identify potentially spurious parts of a given knowledge base is thus becoming an increasingly important area of interest. In this work, we present a systematic evaluation of whether structure-only link analysis methods can already offer a scalable means to detecting possible anomalies, as well as potentially interesting novel relation candidates. Evaluating thirteen methods on eight different semantic resources, including Gene Ontology, Food Ontology, Marine Ontology and similar, we demonstrated that structure-only link analysis could offer scalable anomaly detection for a subset of the data sets. Further, we demonstrated that by considering symbolic node embedding, explanations of the predictions (links) could be obtained, making this branch of methods potentially more valuable than the black-box only ones. To our knowledge, this is currently one of the most extensive systematic studies of the applicability of different types of link analysis methods across semantic resources from different domains.