 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Metalinguistic Knowledge in Large Language Models across the World's Languages
Feb 02, 2026Large language models (LLMs) are routinely evaluated on language use tasks, yet their knowledge of linguistic structure remains poorly understood. Existing linguistic benchmarks typically focus on narrow phenomena, emphasize high-resource languages, and rarely evaluate metalinguistic knowledge-explicit reasoning about language structure rather than language use. Using accuracy and macro F1, together with majority-class and chance baselines, we analyse overall performance and examine variation by linguistic domains and language-related factors. Our results show that metalinguistic knowledge in current LLMs is limited: GPT-4o performs best but achieves only moderate accuracy (0.367), while open-source models lag behind. All models perform above chance but fail to outperform the majority-class baseline, suggesting they capture cross-linguistic patterns but lack fine-grained grammatical distinctions. Performance varies across linguistic domains, with lexical features showing the highest accuracy and phonological features among the lowest, partially reflecting differences in online visibility. At the language level, accuracy shows a strong association with digital language status: languages with higher digital presence and resource availability are evaluated more accurately, while low-resource languages show substantially lower performance. Analyses of predictive factors confirm that resource-related indicators (Wikipedia size, corpus availability) are more informative predictors of accuracy than geographical, genealogical, or sociolinguistic factors. Together, these results suggest that LLMs' metalinguistic knowledge is fragmented and shaped by data availability rather than generalizable grammatical competence across the world's languages. We release our benchmark as an open-source dataset to support systematic evaluation and encourage greater global linguistic diversity in future LLMs.
A Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
Counting trees: A treebank-driven exploration of syntactic variation in speech and writing across languages
May 28, 2025This paper presents a novel treebank-driven approach to comparing syntactic structures in speech and writing using dependency-parsed corpora. Adopting a fully inductive, bottom-up method, we define syntactic structures as delexicalized dependency (sub)trees and extract them from spoken and written Universal Dependencies (UD) treebanks in two syntactically distinct languages, English and Slovenian. For each corpus, we analyze the size, diversity, and distribution of syntactic inventories, their overlap across modalities, and the structures most characteristic of speech. Results show that, across both languages, spoken corpora contain fewer and less diverse syntactic structures than their written counterparts, with consistent cross-linguistic preferences for certain structural types across modalities. Strikingly, the overlap between spoken and written syntactic inventories is very limited: most structures attested in speech do not occur in writing, pointing to modality-specific preferences in syntactic organization that reflect the distinct demands of real-time interaction and elaborated writing. This contrast is further supported by a keyness analysis of the most frequent speech-specific structures, which highlights patterns associated with interactivity, context-grounding, and economy of expression. We argue that this scalable, language-independent framework offers a useful general method for systematically studying syntactic variation across corpora, laying the groundwork for more comprehensive data-driven theories of grammar in use.
Semantic change detection for Slovene language: a novel dataset and an approach based on optimal transport
Feb 26, 2024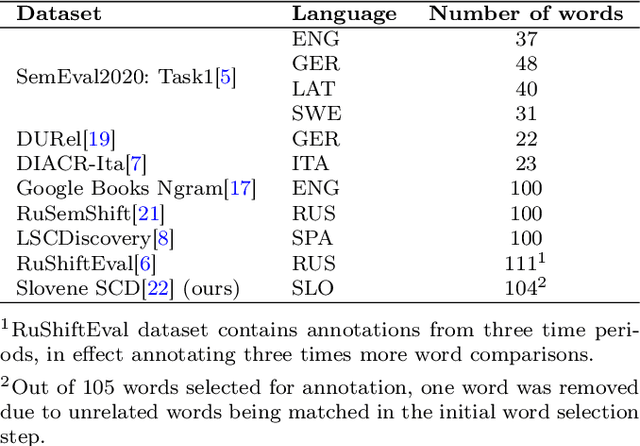
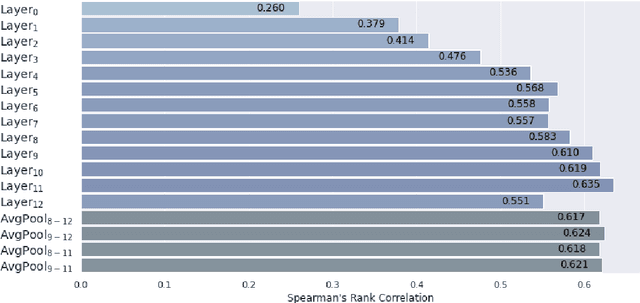

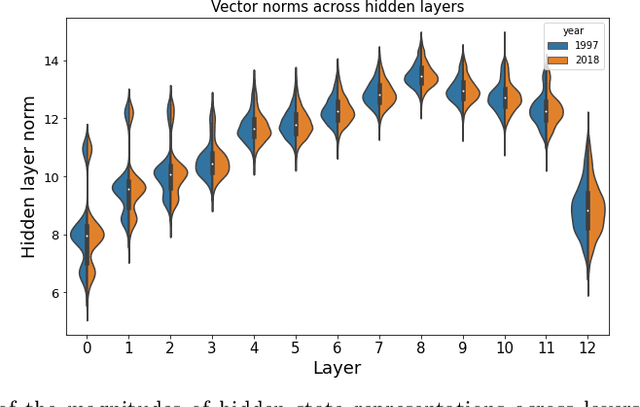
In this paper, we focus on the detection of semantic changes in Slovene, a less resourced Slavic language with two million speakers. Detecting and tracking semantic changes provides insights into the evolution of the language caused by changes in society and culture. Recently, several systems have been proposed to aid in this study, but all depend on manually annotated gold standard datasets for evaluation. In this paper, we present the first Slovene dataset for evaluating semantic change detection systems, which contains aggregated semantic change scores for 104 target words obtained from more than 3000 manually annotated sentence pairs. We evaluate several existing semantic change detection methods on this dataset and also propose a novel approach based on optimal transport that improves on the existing state-of-the-art systems with an error reduction rate of 22.8%.