 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer verbatim in-context retrieval across time and scale
Nov 11, 2024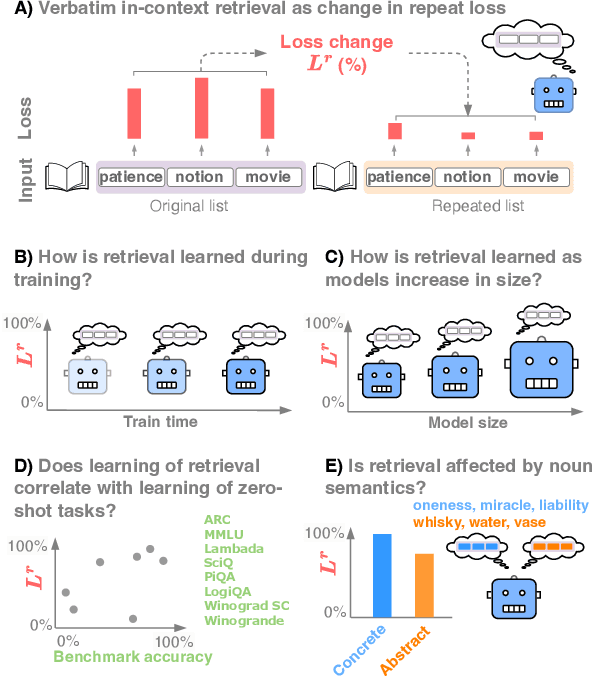

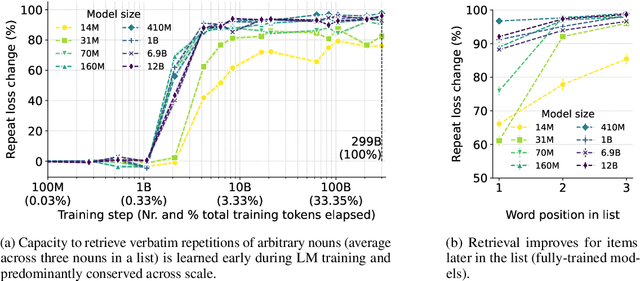

To predict upcoming text, language models must in some cases retrieve in-context information verbatim. In this report, we investigated how the ability of language models to retrieve arbitrary in-context nouns developed during training (across time) and as language models trained on the same dataset increase in size (across scale). We then asked whether learning of in-context retrieval correlates with learning of more challenging zero-shot benchmarks. Furthermore, inspired by semantic effects in human short-term memory, we evaluated the retrieval with respect to a major semantic component of target nouns, namely whether they denote a concrete or abstract entity, as rated by humans. We show that verbatim in-context retrieval developed in a sudden transition early in the training process, after about 1% of the training tokens. This was observed across model sizes (from 14M and up to 12B parameters), and the transition occurred slightly later for the two smallest models. We further found that the development of verbatim in-context retrieval is positively correlated with the learning of zero-shot benchmarks. Around the transition point, all models showed the advantage of retrieving concrete nouns as opposed to abstract nouns. In all but two smallest models, the advantage dissipated away toward the end of training.
Semantic change detection for Slovene language: a novel dataset and an approach based on optimal transport
Feb 26, 2024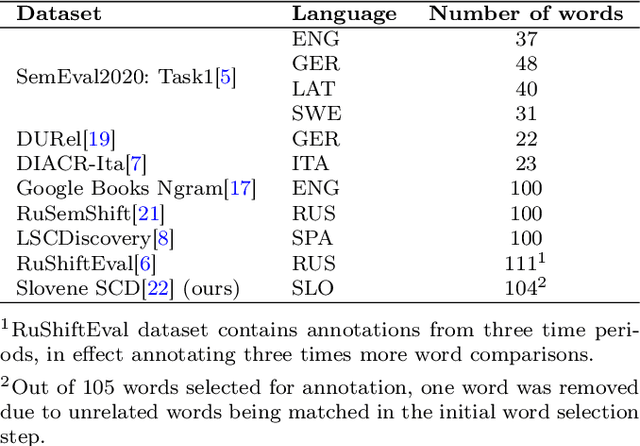
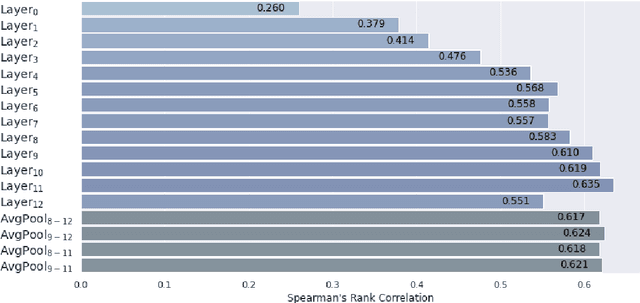

In this paper, we focus on the detection of semantic changes in Slovene, a less resourced Slavic language with two million speakers. Detecting and tracking semantic changes provides insights into the evolution of the language caused by changes in society and culture. Recently, several systems have been proposed to aid in this study, but all depend on manually annotated gold standard datasets for evaluation. In this paper, we present the first Slovene dataset for evaluating semantic change detection systems, which contains aggregated semantic change scores for 104 target words obtained from more than 3000 manually annotated sentence pairs. We evaluate several existing semantic change detection methods on this dataset and also propose a novel approach based on optimal transport that improves on the existing state-of-the-art systems with an error reduction rate of 22.8%.