 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer verbatim in-context retrieval across time and scale
Paper and Code
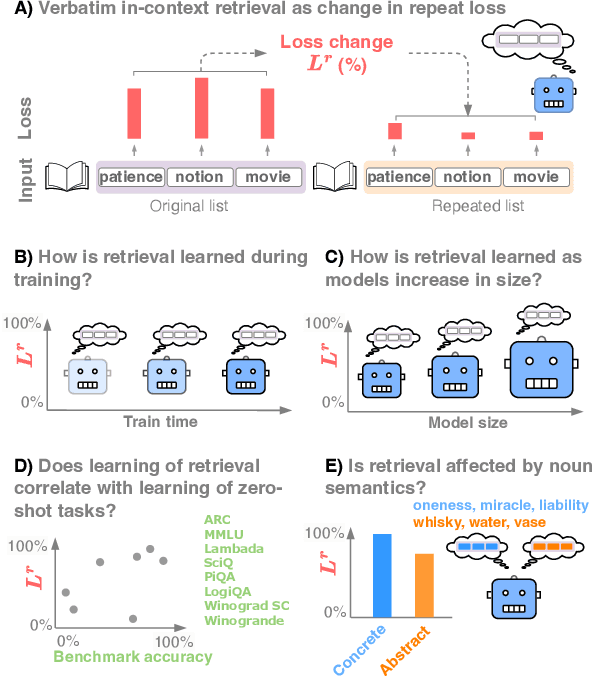

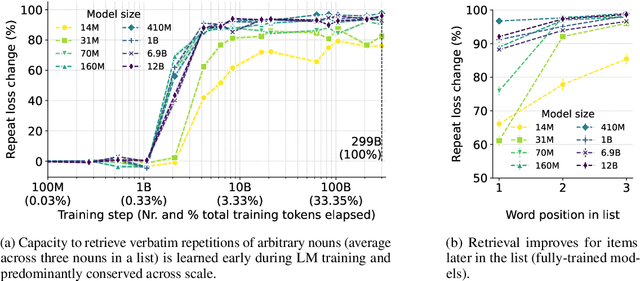

To predict upcoming text, language models must in some cases retrieve in-context information verbatim. In this report, we investigated how the ability of language models to retrieve arbitrary in-context nouns developed during training (across time) and as language models trained on the same dataset increase in size (across scale). We then asked whether learning of in-context retrieval correlates with learning of more challenging zero-shot benchmarks. Furthermore, inspired by semantic effects in human short-term memory, we evaluated the retrieval with respect to a major semantic component of target nouns, namely whether they denote a concrete or abstract entity, as rated by humans. We show that verbatim in-context retrieval developed in a sudden transition early in the training process, after about 1% of the training tokens. This was observed across model sizes (from 14M and up to 12B parameters), and the transition occurred slightly later for the two smallest models. We further found that the development of verbatim in-context retrieval is positively correlated with the learning of zero-shot benchmarks. Around the transition point, all models showed the advantage of retrieving concrete nouns as opposed to abstract nouns. In all but two smallest models, the advantage dissipated away toward the end of training.