 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiOCR-QA: Dataset for Evaluating Robustness of LLMs in Question Answering on Multilingual OCR Texts
Feb 24, 2025Optical Character Recognition (OCR) plays a crucial role in digitizing historical and multilingual documents, yet OCR errors -- imperfect extraction of the text, including character insertion, deletion and permutation -- can significantly impact downstream tasks like question-answering (QA). In this work, we introduce a multilingual QA dataset MultiOCR-QA, designed to analyze the effects of OCR noise on QA systems' performance. The MultiOCR-QA dataset comprises 60K question-answer pairs covering three languages, English, French, and German. The dataset is curated from OCR-ed old documents, allowing for the evaluation of OCR-induced challenges on question answering. We evaluate MultiOCR-QA on various levels and types of OCR errors to access the robustness of LLMs in handling real-world digitization errors. Our findings show that QA systems are highly prone to OCR induced errors and exhibit performance degradation on noisy OCR text.
DocSum: Domain-Adaptive Pre-training for Document Abstractive Summarization
Dec 11, 2024Abstractive summarization has made significant strides in condensing and rephrasing large volumes of text into coherent summaries. However, summarizing administrative documents presents unique challenges due to domain-specific terminology, OCR-generated errors, and the scarcity of annotated datasets for model fine-tuning. Existing models often struggle to adapt to the intricate structure and specialized content of such documents. To address these limitations, we introduce DocSum, a domain-adaptive abstractive summarization framework tailored for administrative documents. Leveraging pre-training on OCR-transcribed text and fine-tuning with an innovative integration of question-answer pairs, DocSum enhances summary accuracy and relevance. This approach tackles the complexities inherent in administrative content, ensuring outputs that align with real-world business needs. To evaluate its capabilities, we define a novel downstream task setting-Document Abstractive Summarization-which reflects the practical requirements of business and organizational settings. Comprehensive experiments demonstrate DocSum's effectiveness in producing high-quality summaries, showcasing its potential to improve decision-making and operational workflows across the public and private sectors.
L3iTC at the FinLLM Challenge Task: Quantization for Financial Text Classification & Summarization
Aug 06, 2024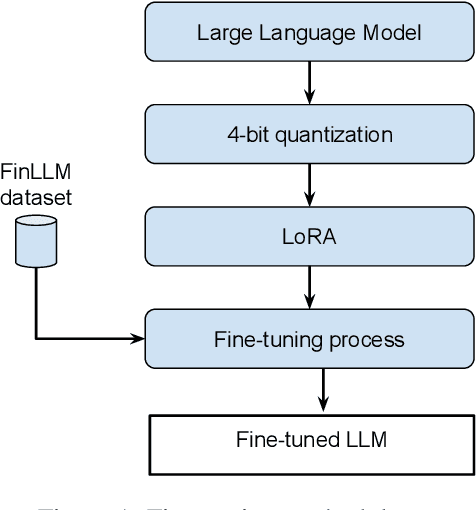


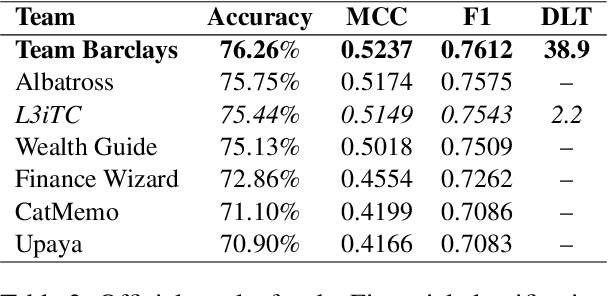
This article details our participation (L3iTC) in the FinLLM Challenge Task 2024, focusing on two key areas: Task 1, financial text classification, and Task 2, financial text summarization. To address these challenges, we fine-tuned several large language models (LLMs) to optimize performance for each task. Specifically, we used 4-bit quantization and LoRA to determine which layers of the LLMs should be trained at a lower precision. This approach not only accelerated the fine-tuning process on the training data provided by the organizers but also enabled us to run the models on low GPU memory. Our fine-tuned models achieved third place for the financial classification task with an F1-score of 0.7543 and secured sixth place in the financial summarization task on the official test datasets.
CoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
Jun 13, 2024



The growing impact of climate change on coastal areas, particularly active but fragile regions, necessitates collaboration among diverse stakeholders and disciplines to formulate effective environmental protection policies. We introduce a novel specialized corpus comprising 2,491 sentences from 410 scientific abstracts concerning coastal areas, for the Automatic Term Extraction (ATE) and Classification (ATC) tasks. Inspired by the ARDI framework, focused on the identification of Actors, Resources, Dynamics and Interactions, we automatically extract domain terms and their distinct roles in the functioning of coastal systems by leveraging monolingual and multilingual transformer models. The evaluation demonstrates consistent results, achieving an F1 score of approximately 80\% for automated term extraction and F1 of 70\% for extracting terms and their labels. These findings are promising and signify an initial step towards the development of a specialized Knowledge Base dedicated to coastal areas.
A Comprehensive Survey of Document-level Relation Extraction (2016-2023)
Oct 12, 2023



Document-level relation extraction (DocRE) is an active area of research in natural language processing (NLP) concerned with identifying and extracting relationships between entities beyond sentence boundaries. Compared to the more traditional sentence-level relation extraction, DocRE provides a broader context for analysis and is more challenging because it involves identifying relationships that may span multiple sentences or paragraphs. This task has gained increased interest as a viable solution to build and populate knowledge bases automatically from unstructured large-scale documents (e.g., scientific papers, legal contracts, or news articles), in order to have a better understanding of relationships between entities. This paper aims to provide a comprehensive overview of recent advances in this field, highlighting its different applications in comparison to sentence-level relation extraction.
Yes but.. Can ChatGPT Identify Entities in Historical Documents?
Mar 30, 2023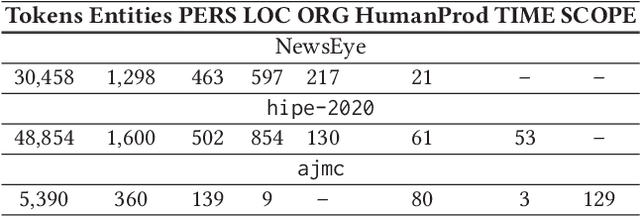


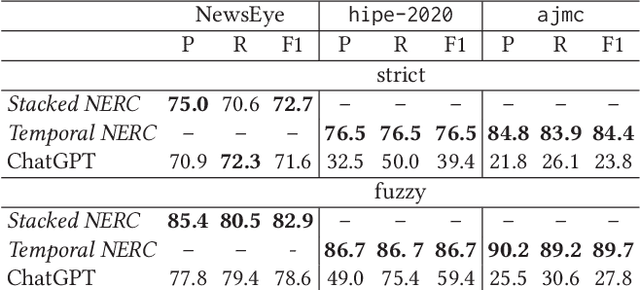
Large language models (LLMs) have been leveraged for several years now, obtaining state-of-the-art performance in recognizing entities from modern documents. For the last few months, the conversational agent ChatGPT has "prompted" a lot of interest in the scientific community and public due to its capacity of generating plausible-sounding answers. In this paper, we explore this ability by probing it in the named entity recognition and classification (NERC) task in primary sources (e.g., historical newspapers and classical commentaries) in a zero-shot manner and by comparing it with state-of-the-art LM-based systems. Our findings indicate several shortcomings in identifying entities in historical text that range from the consistency of entity annotation guidelines, entity complexity, and code-switching, to the specificity of prompting. Moreover, as expected, the inaccessibility of historical archives to the public (and thus on the Internet) also impacts its performance.
DocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


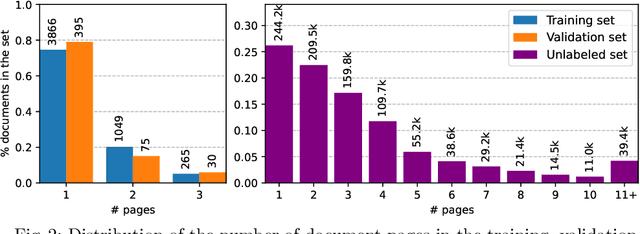
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
Archive TimeLine Summarization (ATLS): Conceptual Framework for Timeline Generation over Historical Document Collections
Jan 31, 2023

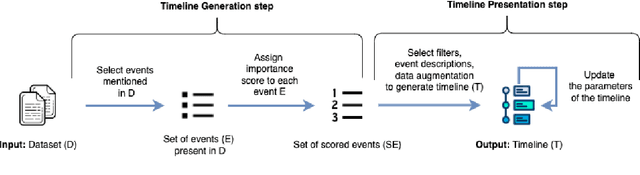
Archive collections are nowadays mostly available through search engines interfaces, which allow a user to retrieve documents by issuing queries. The study of these collections may be, however, impaired by some aspects of search engines, such as the overwhelming number of documents returned or the lack of contextual knowledge provided. New methods that could work independently or in combination with search engines are then required to access these collections. In this position paper, we propose to extend TimeLine Summarization (TLS) methods on archive collections to assist in their studies. We provide an overview of existing TLS methods and we describe a conceptual framework for an Archive TimeLine Summarization (ATLS) system, which aims to generate informative, readable and interpretable timelines.
Contextualizing Emerging Trends in Financial News Articles
Jan 20, 2023
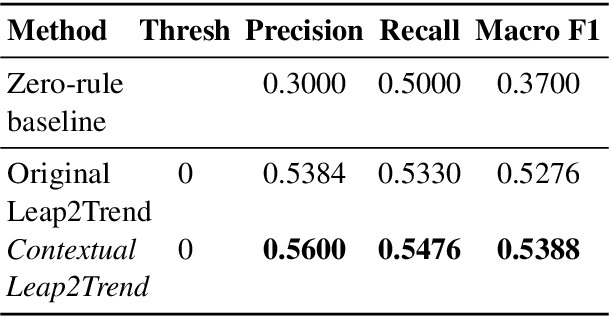
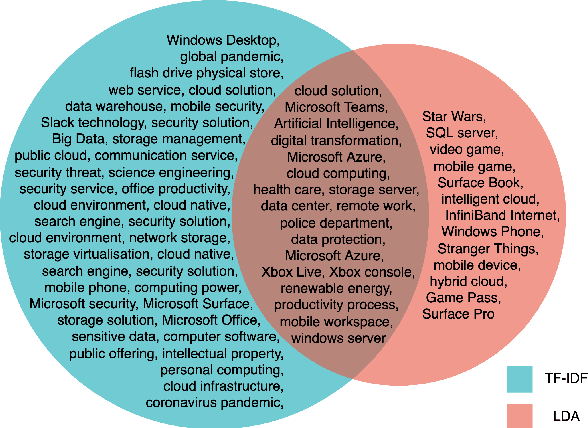
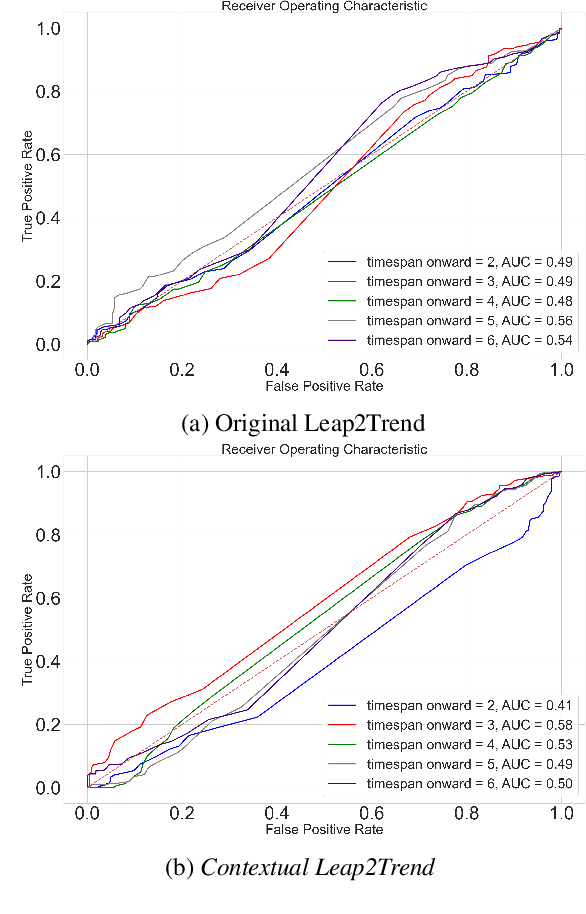
Identifying and exploring emerging trends in the news is becoming more essential than ever with many changes occurring worldwide due to the global health crises. However, most of the recent research has focused mainly on detecting trends in social media, thus, benefiting from social features (e.g. likes and retweets on Twitter) which helped the task as they can be used to measure the engagement and diffusion rate of content. Yet, formal text data, unlike short social media posts, comes with a longer, less restricted writing format, and thus, more challenging. In this paper, we focus our study on emerging trends detection in financial news articles about Microsoft, collected before and during the start of the COVID-19 pandemic (July 2019 to July 2020). We make the dataset accessible and propose a strong baseline (Contextual Leap2Trend) for exploring the dynamics of similarities between pairs of keywords based on topic modelling and term frequency. Finally, we evaluate against a gold standard (Google Trends) and present noteworthy real-world scenarios regarding the influence of the pandemic on Microsoft.
The Recent Advances in Automatic Term Extraction: A survey
Jan 17, 2023Automatic term extraction (ATE) is a Natural Language Processing (NLP) task that eases the effort of manually identifying terms from domain-specific corpora by providing a list of candidate terms. As units of knowledge in a specific field of expertise, extracted terms are not only beneficial for several terminographical tasks, but also support and improve several complex downstream tasks, e.g., information retrieval, machine translation, topic detection, and sentiment analysis. ATE systems, along with annotated datasets, have been studied and developed widely for decades, but recently we observed a surge in novel neural systems for the task at hand. Despite a large amount of new research on ATE, systematic survey studies covering novel neural approaches are lacking. We present a comprehensive survey of deep learning-based approaches to ATE, with a focus on Transformer-based neural models. The study also offers a comparison between these systems and previous ATE approaches, which were based on feature engineering and non-neural supervised learning algorithms.