 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GDN-CC Dataset: Automatic Corpus Clarification for AI-enhanced Democratic Citizen Consultations
Jan 21, 2026LLMs are ubiquitous in modern NLP, and while their applicability extends to texts produced for democratic activities such as online deliberations or large-scale citizen consultations, ethical questions have been raised for their usage as analysis tools. We continue this line of research with two main goals: (a) to develop resources that can help standardize citizen contributions in public forums at the pragmatic level, and make them easier to use in topic modeling and political analysis; (b) to study how well this standardization can reliably be performed by small, open-weights LLMs, i.e. models that can be run locally and transparently with limited resources. Accordingly, we introduce Corpus Clarification as a preprocessing framework for large-scale consultation data that transforms noisy, multi-topic contributions into structured, self-contained argumentative units ready for downstream analysis. We present GDN-CC, a manually-curated dataset of 1,231 contributions to the French Grand Débat National, comprising 2,285 argumentative units annotated for argumentative structure and manually clarified. We then show that finetuned Small Language Models match or outperform LLMs on reproducing these annotations, and measure their usability for an opinion clustering task. We finally release GDN-CC-large, an automatically annotated corpus of 240k contributions, the largest annotated democratic consultation dataset to date.
Contextualizing Emerging Trends in Financial News Articles
Jan 20, 2023
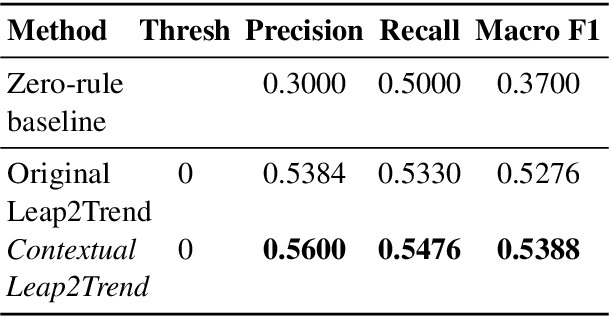
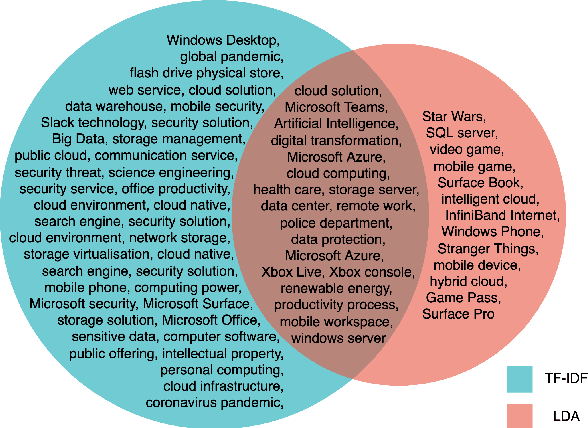
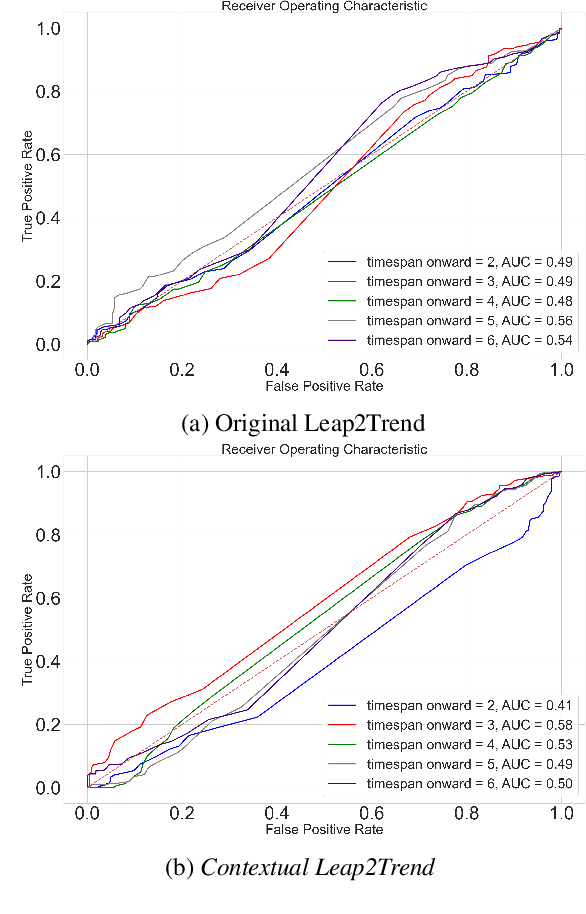
Identifying and exploring emerging trends in the news is becoming more essential than ever with many changes occurring worldwide due to the global health crises. However, most of the recent research has focused mainly on detecting trends in social media, thus, benefiting from social features (e.g. likes and retweets on Twitter) which helped the task as they can be used to measure the engagement and diffusion rate of content. Yet, formal text data, unlike short social media posts, comes with a longer, less restricted writing format, and thus, more challenging. In this paper, we focus our study on emerging trends detection in financial news articles about Microsoft, collected before and during the start of the COVID-19 pandemic (July 2019 to July 2020). We make the dataset accessible and propose a strong baseline (Contextual Leap2Trend) for exploring the dynamics of similarities between pairs of keywords based on topic modelling and term frequency. Finally, we evaluate against a gold standard (Google Trends) and present noteworthy real-world scenarios regarding the influence of the pandemic on Microsoft.