 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Towards an Accurate and Effective Robot Vision (The Problem of Topological Localization for Mobile Robots)
Sep 05, 2025Topological localization is a fundamental problem in mobile robotics, since robots must be able to determine their position in order to accomplish tasks. Visual localization and place recognition are challenging due to perceptual ambiguity, sensor noise, and illumination variations. This work addresses topological localization in an office environment using only images acquired with a perspective color camera mounted on a robot platform, without relying on temporal continuity of image sequences. We evaluate state-of-the-art visual descriptors, including Color Histograms, SIFT, ASIFT, RGB-SIFT, and Bag-of-Visual-Words approaches inspired by text retrieval. Our contributions include a systematic, quantitative comparison of these features, distance measures, and classifiers. Performance was analyzed using standard evaluation metrics and visualizations, extending previous experiments. Results demonstrate the advantages of proper configurations of appearance descriptors, similarity measures, and classifiers. The quality of these configurations was further validated in the Robot Vision task of the ImageCLEF evaluation campaign, where the system identified the most likely location of novel image sequences. Future work will explore hierarchical models, ranking methods, and feature combinations to build more robust localization systems, reducing training and runtime while avoiding the curse of dimensionality. Ultimately, this aims toward integrated, real-time localization across varied illumination and longer routes.
Investigating OCR-Sensitive Neurons to Improve Entity Recognition in Historical Documents
Sep 26, 2024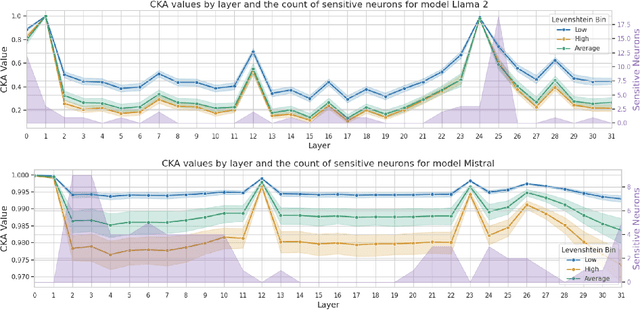
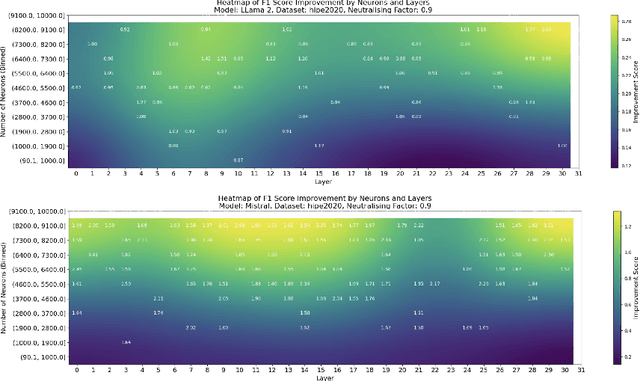
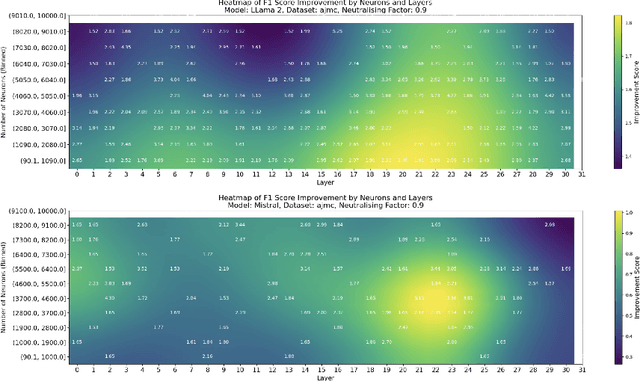
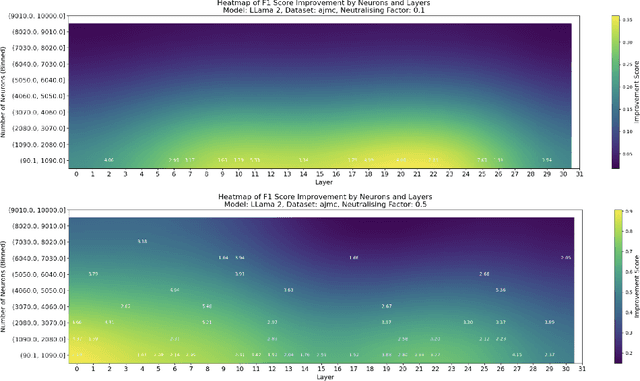
This paper investigates the presence of OCR-sensitive neurons within the Transformer architecture and their influence on named entity recognition (NER) performance on historical documents. By analysing neuron activation patterns in response to clean and noisy text inputs, we identify and then neutralise OCR-sensitive neurons to improve model performance. Based on two open access large language models (Llama2 and Mistral), experiments demonstrate the existence of OCR-sensitive regions and show improvements in NER performance on historical newspapers and classical commentaries, highlighting the potential of targeted neuron modulation to improve models' performance on noisy text.
Yes but.. Can ChatGPT Identify Entities in Historical Documents?
Mar 30, 2023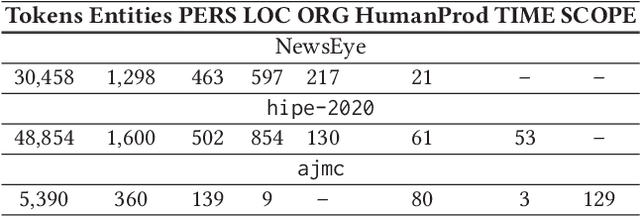


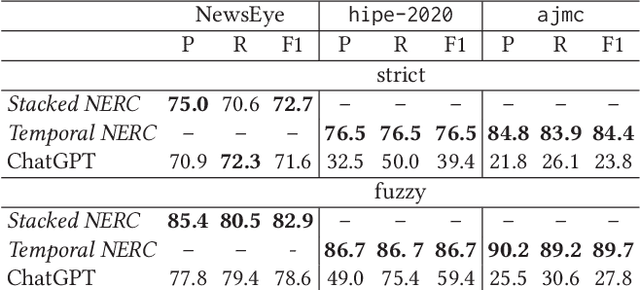
Large language models (LLMs) have been leveraged for several years now, obtaining state-of-the-art performance in recognizing entities from modern documents. For the last few months, the conversational agent ChatGPT has "prompted" a lot of interest in the scientific community and public due to its capacity of generating plausible-sounding answers. In this paper, we explore this ability by probing it in the named entity recognition and classification (NERC) task in primary sources (e.g., historical newspapers and classical commentaries) in a zero-shot manner and by comparing it with state-of-the-art LM-based systems. Our findings indicate several shortcomings in identifying entities in historical text that range from the consistency of entity annotation guidelines, entity complexity, and code-switching, to the specificity of prompting. Moreover, as expected, the inaccessibility of historical archives to the public (and thus on the Internet) also impacts its performance.
Contextualizing Emerging Trends in Financial News Articles
Jan 20, 2023
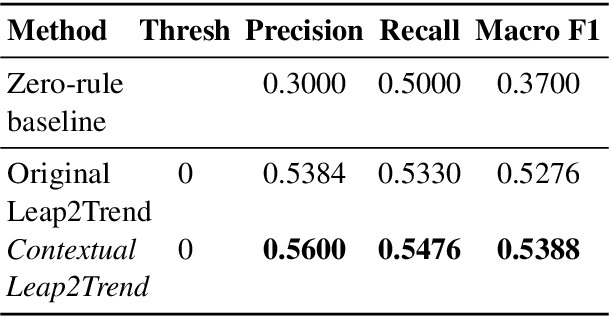
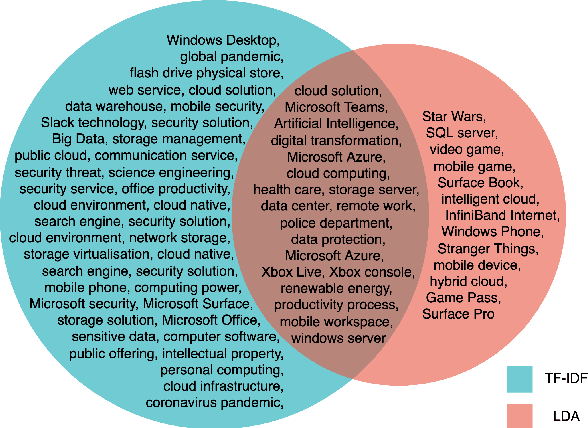
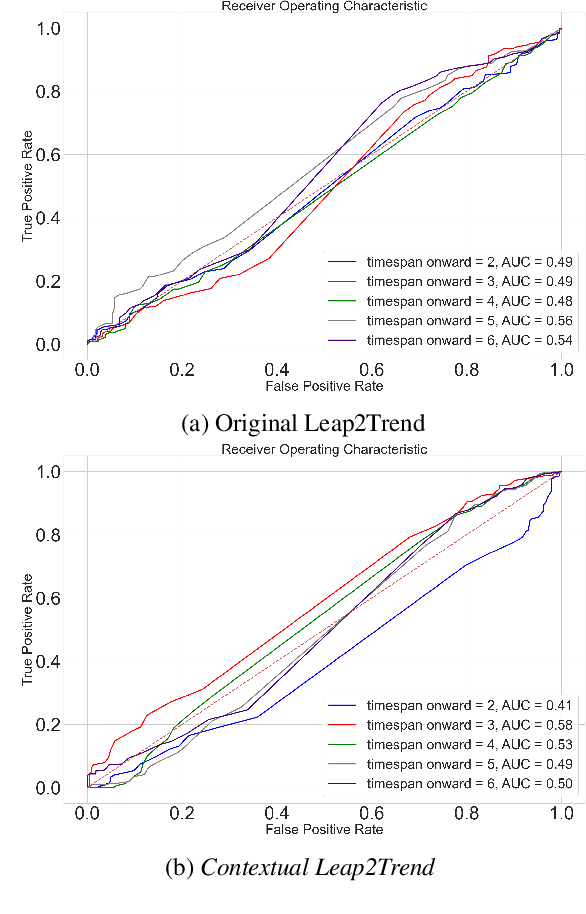
Identifying and exploring emerging trends in the news is becoming more essential than ever with many changes occurring worldwide due to the global health crises. However, most of the recent research has focused mainly on detecting trends in social media, thus, benefiting from social features (e.g. likes and retweets on Twitter) which helped the task as they can be used to measure the engagement and diffusion rate of content. Yet, formal text data, unlike short social media posts, comes with a longer, less restricted writing format, and thus, more challenging. In this paper, we focus our study on emerging trends detection in financial news articles about Microsoft, collected before and during the start of the COVID-19 pandemic (July 2019 to July 2020). We make the dataset accessible and propose a strong baseline (Contextual Leap2Trend) for exploring the dynamics of similarities between pairs of keywords based on topic modelling and term frequency. Finally, we evaluate against a gold standard (Google Trends) and present noteworthy real-world scenarios regarding the influence of the pandemic on Microsoft.
Event Detection as Question Answering with Entity Information
Apr 14, 2021

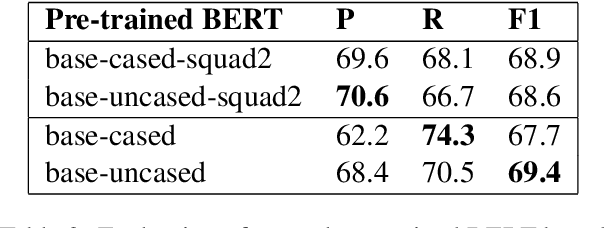

In this paper, we propose a recent and under-researched paradigm for the task of event detection (ED) by casting it as a question-answering (QA) problem with the possibility of multiple answers and the support of entities. The extraction of event triggers is, thus, transformed into the task of identifying answer spans from a context, while also focusing on the surrounding entities. The architecture is based on a pre-trained and fine-tuned language model, where the input context is augmented with entities marked at different levels, their positions, their types, and, finally, the argument roles. Experiments on the ACE~2005 corpus demonstrate that the proposed paradigm is a viable solution for the ED task and it significantly outperforms the state-of-the-art models. Moreover, we prove that our methods are also able to extract unseen event types.
Transformer-based Methods for Recognizing Ultra Fine-grained Entities (RUFES)
Apr 13, 2021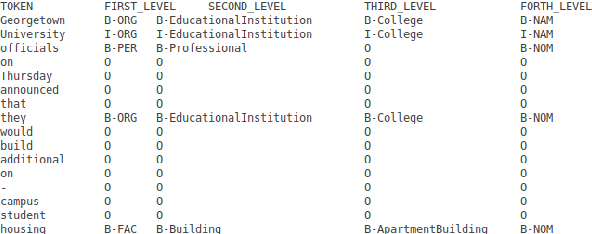
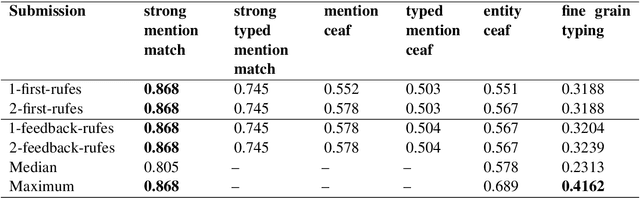
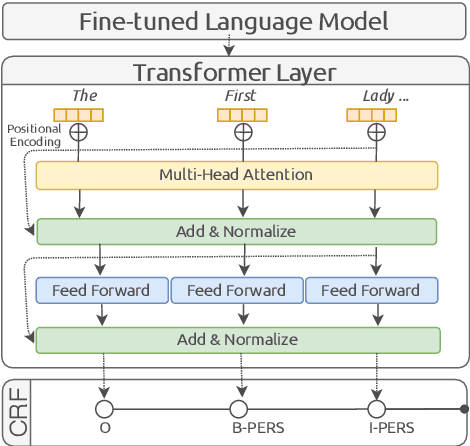
This paper summarizes the participation of the Laboratoire Informatique, Image et Interaction (L3i laboratory) of the University of La Rochelle in the Recognizing Ultra Fine-grained Entities (RUFES) track within the Text Analysis Conference (TAC) series of evaluation workshops. Our participation relies on two neural-based models, one based on a pre-trained and fine-tuned language model with a stack of Transformer layers for fine-grained entity extraction and one out-of-the-box model for within-document entity coreference. We observe that our approach has great potential in increasing the performance of fine-grained entity recognition. Thus, the future work envisioned is to enhance the ability of the models following additional experiments and a deeper analysis of the results.