 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Investigating OCR-Sensitive Neurons to Improve Entity Recognition in Historical Documents
Sep 26, 2024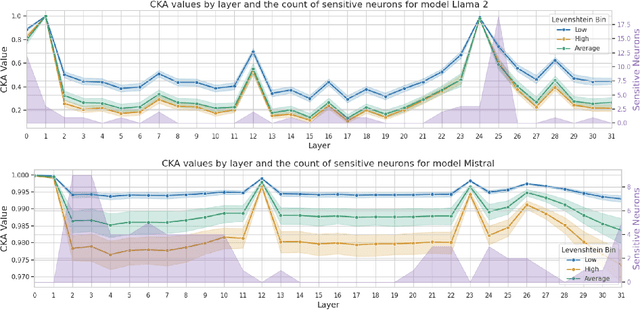
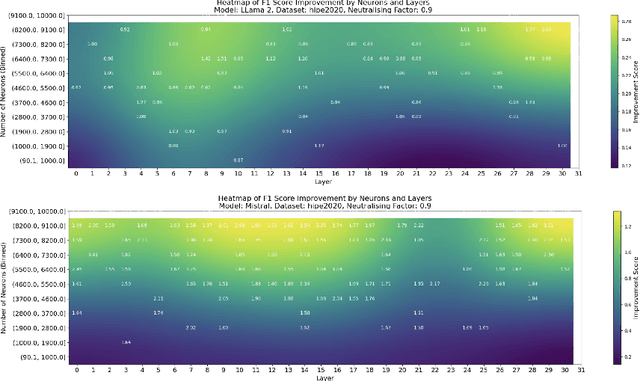
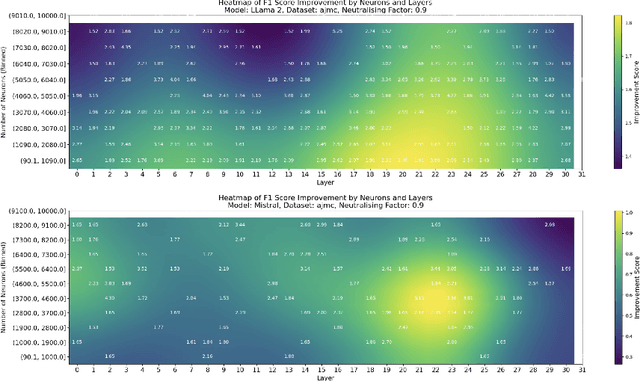
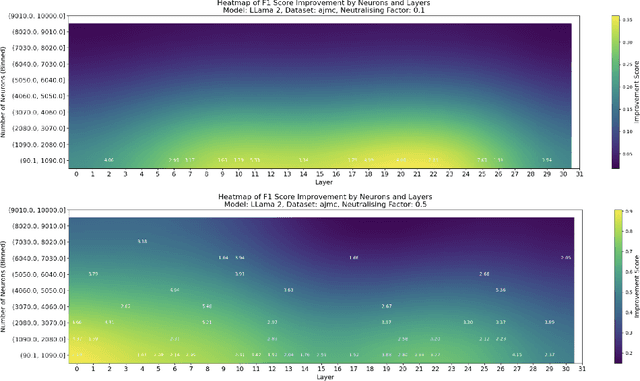
This paper investigates the presence of OCR-sensitive neurons within the Transformer architecture and their influence on named entity recognition (NER) performance on historical documents. By analysing neuron activation patterns in response to clean and noisy text inputs, we identify and then neutralise OCR-sensitive neurons to improve model performance. Based on two open access large language models (Llama2 and Mistral), experiments demonstrate the existence of OCR-sensitive regions and show improvements in NER performance on historical newspapers and classical commentaries, highlighting the potential of targeted neuron modulation to improve models' performance on noisy text.
Named Entity Recognition and Classification on Historical Documents: A Survey
Sep 23, 2021

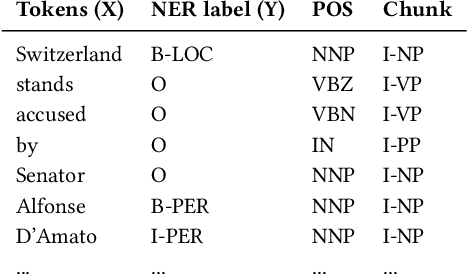

After decades of massive digitisation, an unprecedented amount of historical documents is available in digital format, along with their machine-readable texts. While this represents a major step forward with respect to preservation and accessibility, it also opens up new opportunities in terms of content mining and the next fundamental challenge is to develop appropriate technologies to efficiently search, retrieve and explore information from this 'big data of the past'. Among semantic indexing opportunities, the recognition and classification of named entities are in great demand among humanities scholars. Yet, named entity recognition (NER) systems are heavily challenged with diverse, historical and noisy inputs. In this survey, we present the array of challenges posed by historical documents to NER, inventory existing resources, describe the main approaches deployed so far, and identify key priorities for future developments.
Combining Visual and Textual Features for Semantic Segmentation of Historical Newspapers
Feb 14, 2020
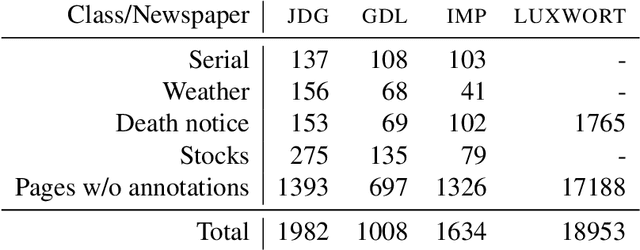
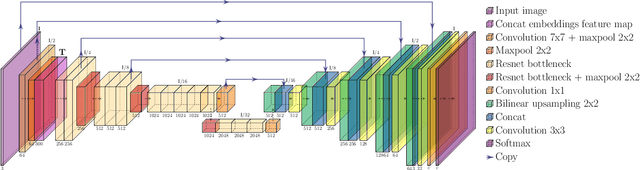
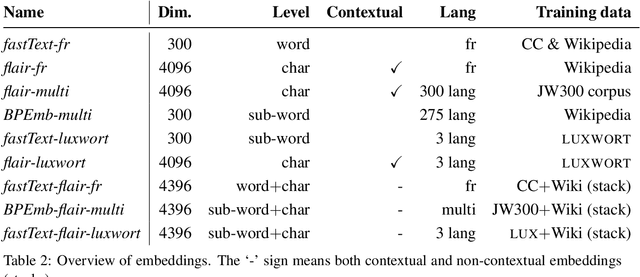
The massive amounts of digitized historical documents acquired over the last decades naturally lend themselves to automatic processing and exploration. Research work seeking to automatically process facsimiles and extract information thereby are multiplying with, as a first essential step, document layout analysis. If the identification and categorization of segments of interest in document images have seen significant progress over the last years thanks to deep learning techniques, many challenges remain with, among others, the use of finer-grained segmentation typologies and the consideration of complex, heterogeneous documents such as historical newspapers. Besides, most approaches consider visual features only, ignoring textual signal. In this context, we introduce a multimodal approach for the semantic segmentation of historical newspapers that combines visual and textual features. Based on a series of experiments on diachronic Swiss and Luxembourgish newspapers, we investigate, among others, the predictive power of visual and textual features and their capacity to generalize across time and sources. Results show consistent improvement of multimodal models in comparison to a strong visual baseline, as well as better robustness to high material variance.
Acronym recognition and processing in 22 languages
Sep 24, 2013
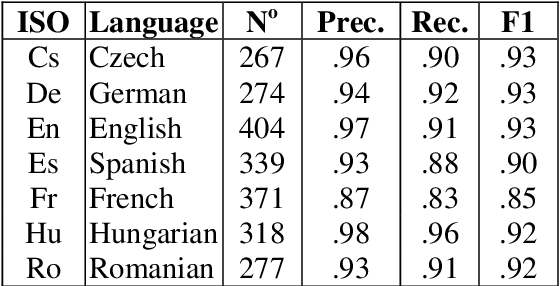
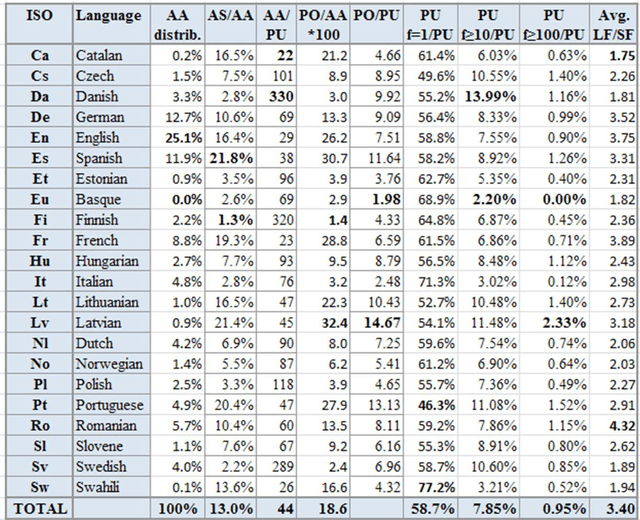
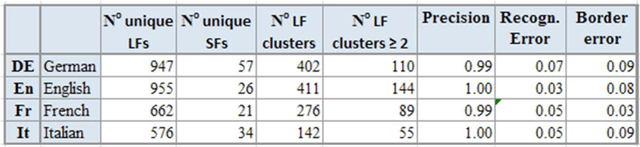
We are presenting work on recognising acronyms of the form Long-Form (Short-Form) such as "International Monetary Fund (IMF)" in millions of news articles in twenty-two languages, as part of our more general effort to recognise entities and their variants in news text and to use them for the automatic analysis of the news, including the linking of related news across languages. We show how the acronym recognition patterns, initially developed for medical terms, needed to be adapted to the more general news domain and we present evaluation results. We describe our effort to automatically merge the numerous long-form variants referring to the same short-form, while keeping non-related long-forms separate. Finally, we provide extensive statistics on the frequency and the distribution of short-form/long-form pairs across languages.