 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcronym recognition and processing in 22 languages
Sep 24, 2013
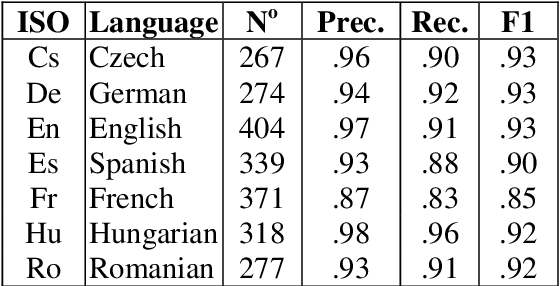
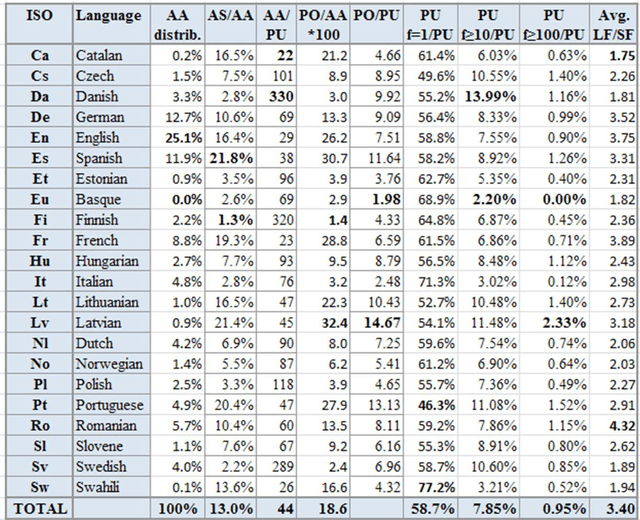
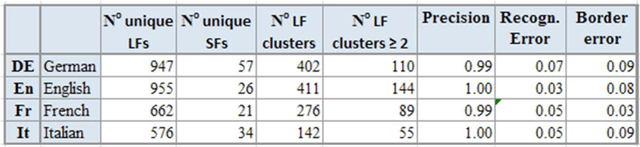
We are presenting work on recognising acronyms of the form Long-Form (Short-Form) such as "International Monetary Fund (IMF)" in millions of news articles in twenty-two languages, as part of our more general effort to recognise entities and their variants in news text and to use them for the automatic analysis of the news, including the linking of related news across languages. We show how the acronym recognition patterns, initially developed for medical terms, needed to be adapted to the more general news domain and we present evaluation results. We describe our effort to automatically merge the numerous long-form variants referring to the same short-form, while keeping non-related long-forms separate. Finally, we provide extensive statistics on the frequency and the distribution of short-form/long-form pairs across languages.