 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2023): Workshop and Shared Task Report
Dec 02, 2023We provide a summary of the sixth edition of the CASE workshop that is held in the scope of RANLP 2023. The workshop consists of regular papers, three keynotes, working papers of shared task participants, and shared task overview papers. This workshop series has been bringing together all aspects of event information collection across technical and social science fields. In addition to contributing to the progress in text based event extraction, the workshop provides a space for the organization of a multimodal event information collection task.
Challenges and Applications of Automated Extraction of Socio-political Events from Text : Workshop and Shared Task Report
Nov 21, 2022We provide a summary of the fifth edition of the CASE workshop that is held in the scope of EMNLP 2022. The workshop consists of regular papers, two keynotes, working papers of shared task participants, and task overview papers. This workshop has been bringing together all aspects of event information collection across technical and social science fields. In addition to the progress in depth, the submission and acceptance of multimodal approaches show the widening of this interdisciplinary research topic.
Automated Extraction of Socio-political Events from News (AESPEN): Workshop and Shared Task Report
May 12, 2020

We describe our effort on automated extraction of socio-political events from news in the scope of a workshop and a shared task we organized at Language Resources and Evaluation Conference (LREC 2020). We believe the event extraction studies in computational linguistics and social and political sciences should further support each other in order to enable large scale socio-political event information collection across sources, countries, and languages. The event consists of regular research papers and a shared task, which is about event sentence coreference identification (ESCI), tracks. All submissions were reviewed by five members of the program committee. The workshop attracted research papers related to evaluation of machine learning methodologies, language resources, material conflict forecasting, and a shared task participation report in the scope of socio-political event information collection. It has shown us the volume and variety of both the data sources and event information collection approaches related to socio-political events and the need to fill the gap between automated text processing techniques and requirements of social and political sciences.
Observing Trends in Automated Multilingual Media Analysis
Mar 08, 2016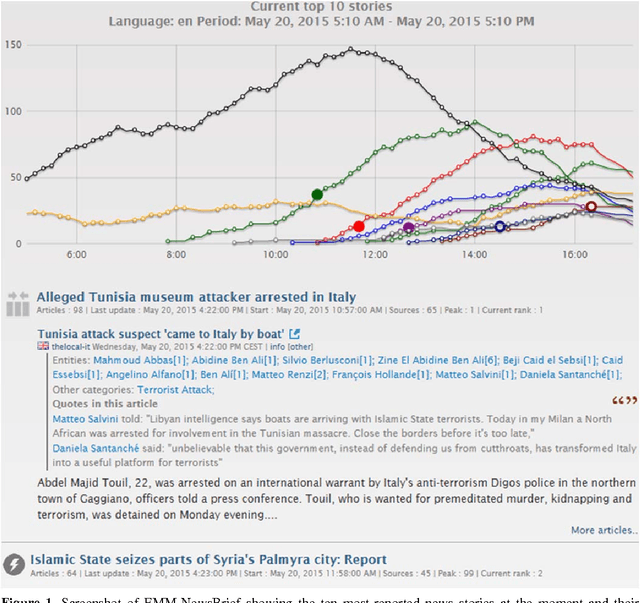
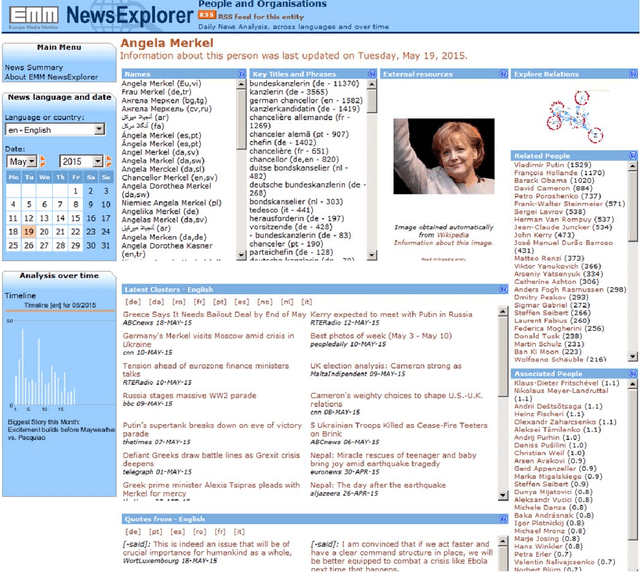
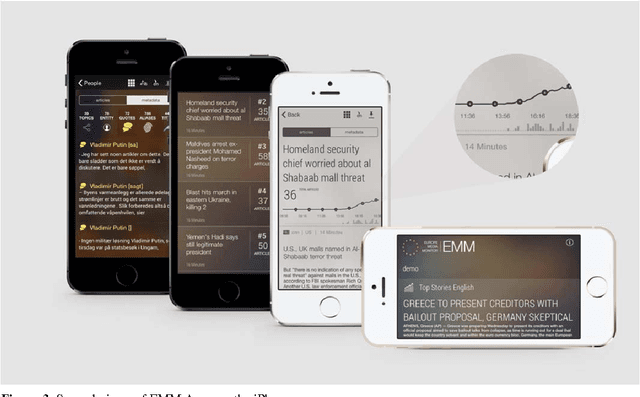
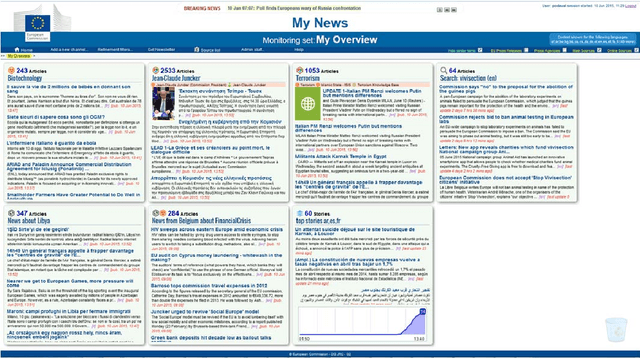
Any large organisation, be it public or private, monitors the media for information to keep abreast of developments in their field of interest, and usually also to become aware of positive or negative opinions expressed towards them. At least for the written media, computer programs have become very efficient at helping the human analysts significantly in their monitoring task by gathering media reports, analysing them, detecting trends and - in some cases - even to issue early warnings or to make predictions of likely future developments. We present here trend recognition-related functionality of the Europe Media Monitor (EMM) system, which was developed by the European Commission's Joint Research Centre (JRC) for public administrations in the European Union (EU) and beyond. EMM performs large-scale media analysis in up to seventy languages and recognises various types of trends, some of them combining information from news articles written in different languages and from social media posts. EMM also lets users explore the huge amount of multilingual media data through interactive maps and graphs, allowing them to examine the data from various view points and according to multiple criteria. A lot of EMM's functionality is accessibly freely over the internet or via apps for hand-held devices.
Acronym recognition and processing in 22 languages
Sep 24, 2013
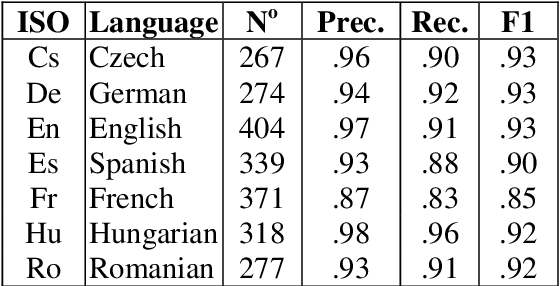
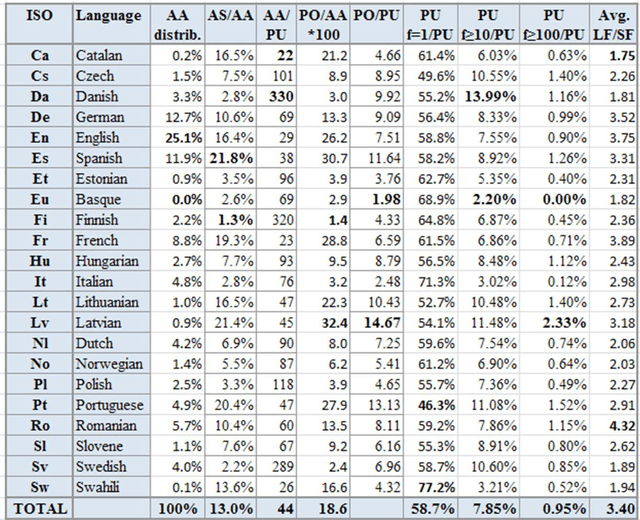
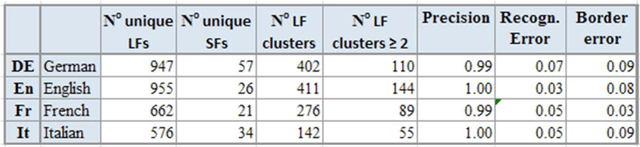
We are presenting work on recognising acronyms of the form Long-Form (Short-Form) such as "International Monetary Fund (IMF)" in millions of news articles in twenty-two languages, as part of our more general effort to recognise entities and their variants in news text and to use them for the automatic analysis of the news, including the linking of related news across languages. We show how the acronym recognition patterns, initially developed for medical terms, needed to be adapted to the more general news domain and we present evaluation results. We describe our effort to automatically merge the numerous long-form variants referring to the same short-form, while keeping non-related long-forms separate. Finally, we provide extensive statistics on the frequency and the distribution of short-form/long-form pairs across languages.