 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Applications of Automated Extraction of Socio-political Events from Text : Workshop and Shared Task Report
Nov 21, 2022We provide a summary of the fifth edition of the CASE workshop that is held in the scope of EMNLP 2022. The workshop consists of regular papers, two keynotes, working papers of shared task participants, and task overview papers. This workshop has been bringing together all aspects of event information collection across technical and social science fields. In addition to the progress in depth, the submission and acceptance of multimodal approaches show the widening of this interdisciplinary research topic.
SU-NLP at SemEval-2022 Task 11: Complex Named Entity Recognition with Entity Linking
Mar 22, 2022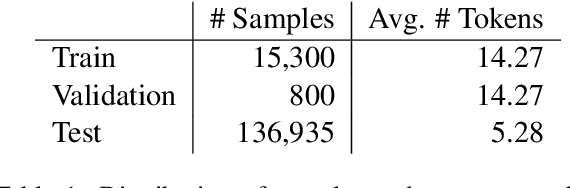
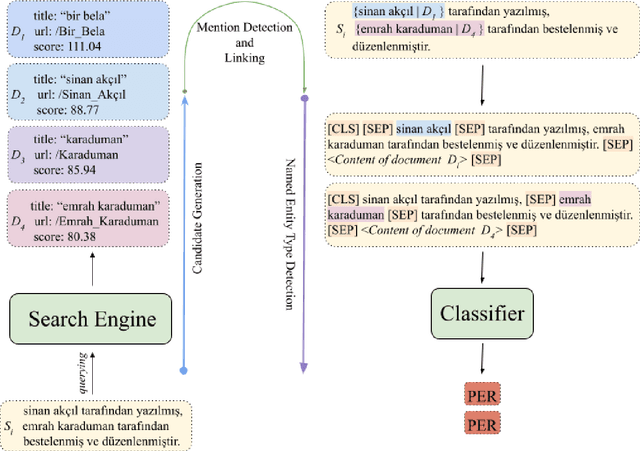
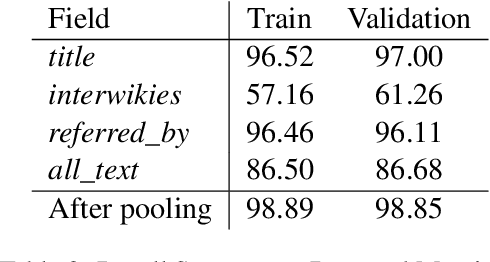
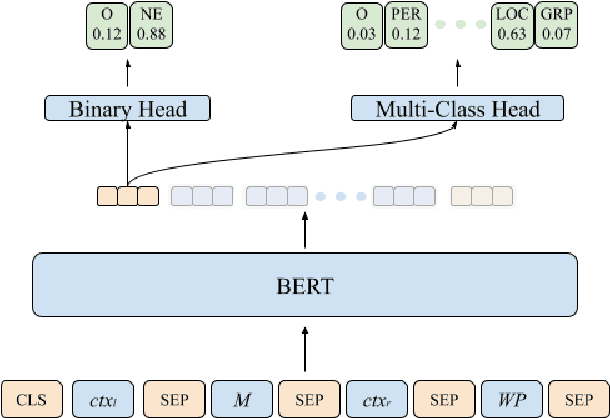
This paper describes the system proposed by Sabanc{\i} University Natural Language Processing Group in the SemEval-2022 MultiCoNER task. We developed an unsupervised entity linking pipeline that detects potential entity mentions with the help of Wikipedia and also uses the corresponding Wikipedia context to help the classifier in finding the named entity type of that mention. Our results showed that our pipeline improved performance significantly, especially for complex entities in low-context settings.
Event Coreference Resolution for Contentious Politics Events
Mar 18, 2022
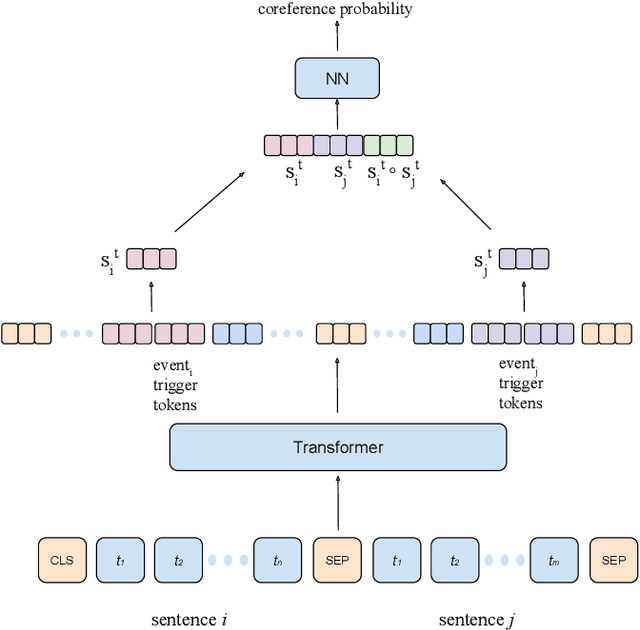


We propose a dataset for event coreference resolution, which is based on random samples drawn from multiple sources, languages, and countries. Early scholarship on event information collection has not quantified the contribution of event coreference resolution. We prepared and analyzed a representative multilingual corpus and measured the performance and contribution of the state-of-the-art event coreference resolution approaches. We found that almost half of the event mentions in documents co-occur with other event mentions and this makes it inevitable to obtain erroneous or partial event information. We showed that event coreference resolution could help improving this situation. Our contribution sheds light on a challenge that has been overlooked or hard to study to date. Future event information collection studies can be designed based on the results we present in this report. The repository for this study is on https://github.com/emerging-welfare/ECR4-Contentious-Politics.
Focusing on Possible Named Entities in Active Named Entity Label Acquisition
Nov 06, 2021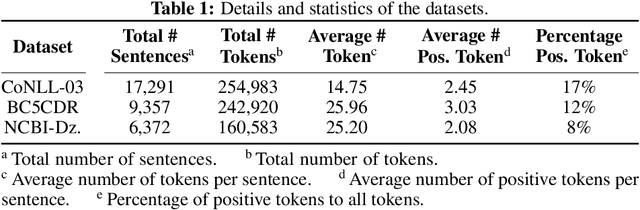
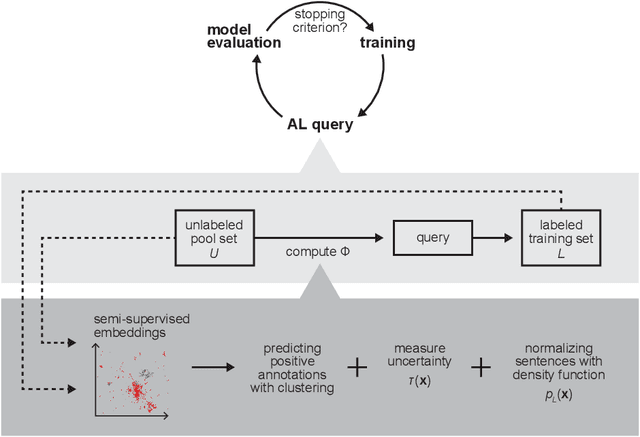
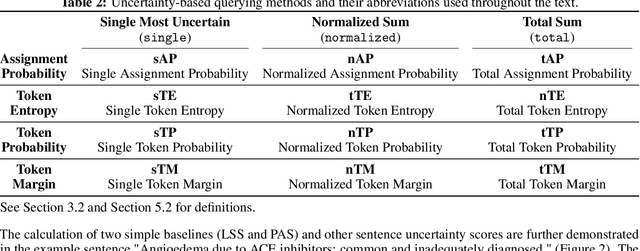
Named entity recognition (NER) aims to identify mentions of named entities in an unstructured text and classify them into the predefined named entity classes. Even though deep learning-based pre-trained language models achieve good predictive performances, many domain-specific NERtasks still require a sufficient amount of labeled data. Active learning (AL), a general framework for the label acquisition problem, has been used for the NER tasks to minimize the annotation cost without sacrificing model performance. However, heavily imbalanced class distribution of tokens introduces challenges in designing effective AL querying methods for NER. We propose AL sentence query evaluation functions which pay more attention to possible positive tokens, and evaluate these proposed functions with both sentence-based and token-based cost evaluation strategies. We also propose a better data-driven normalization approach to penalize too long or too short sentences. Our experiments on three datasets from different domains reveal that the proposed approaches reduce the number of annotated tokens while achieving better or comparable prediction performance with conventional methods.