 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLOCON Database: Design Decisions and User Manual (v1.0)
May 28, 2024
GLOCON is a database of contentious events automatically extracted from national news sources from various countries in multiple languages. National news sources are utilized, and complete news archives are processed to create an event list for each source. Automation is achieved using a gold standard corpus sampled randomly from complete news archives (Y\"or\"uk et al. 2022) and all annotated by at least two domain experts based on the event definition provided in Duru\c{s}an et al. (2022).
Extended Multilingual Protest News Detection -- Shared Task 1, CASE 2021 and 2022
Nov 21, 2022



We report results of the CASE 2022 Shared Task 1 on Multilingual Protest Event Detection. This task is a continuation of CASE 2021 that consists of four subtasks that are i) document classification, ii) sentence classification, iii) event sentence coreference identification, and iv) event extraction. The CASE 2022 extension consists of expanding the test data with more data in previously available languages, namely, English, Hindi, Portuguese, and Spanish, and adding new test data in Mandarin, Turkish, and Urdu for Sub-task 1, document classification. The training data from CASE 2021 in English, Portuguese and Spanish were utilized. Therefore, predicting document labels in Hindi, Mandarin, Turkish, and Urdu occurs in a zero-shot setting. The CASE 2022 workshop accepts reports on systems developed for predicting test data of CASE 2021 as well. We observe that the best systems submitted by CASE 2022 participants achieve between 79.71 and 84.06 F1-macro for new languages in a zero-shot setting. The winning approaches are mainly ensembling models and merging data in multiple languages. The best two submissions on CASE 2021 data outperform submissions from last year for Subtask 1 and Subtask 2 in all languages. Only the following scenarios were not outperformed by new submissions on CASE 2021: Subtask 3 Portuguese \& Subtask 4 English.
Event Coreference Resolution for Contentious Politics Events
Mar 18, 2022
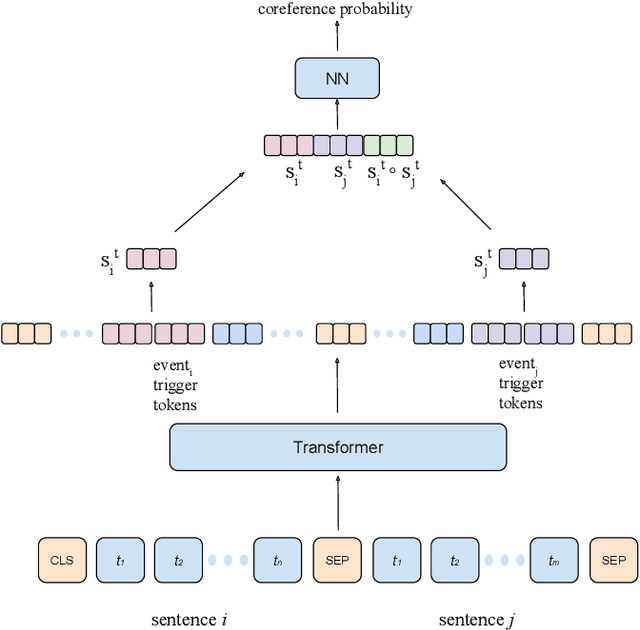


We propose a dataset for event coreference resolution, which is based on random samples drawn from multiple sources, languages, and countries. Early scholarship on event information collection has not quantified the contribution of event coreference resolution. We prepared and analyzed a representative multilingual corpus and measured the performance and contribution of the state-of-the-art event coreference resolution approaches. We found that almost half of the event mentions in documents co-occur with other event mentions and this makes it inevitable to obtain erroneous or partial event information. We showed that event coreference resolution could help improving this situation. Our contribution sheds light on a challenge that has been overlooked or hard to study to date. Future event information collection studies can be designed based on the results we present in this report. The repository for this study is on https://github.com/emerging-welfare/ECR4-Contentious-Politics.
Cross-context News Corpus for Protest Events related Knowledge Base Construction
Aug 01, 2020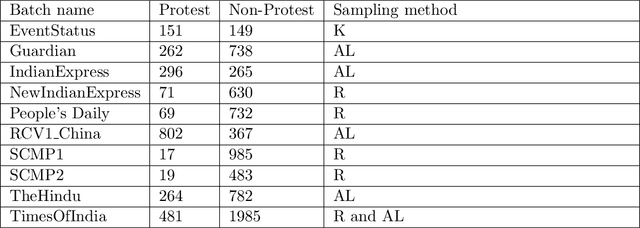



We describe a gold standard corpus of protest events that comprise of various local and international sources from various countries in English. The corpus contains document, sentence, and token level annotations. This corpus facilitates creating machine learning models that automatically classify news articles and extract protest event-related information, constructing knowledge bases which enable comparative social and political science studies. For each news source, the annotation starts on random samples of news articles and continues with samples that are drawn using active learning. Each batch of samples was annotated by two social and political scientists, adjudicated by an annotation supervisor, and was improved by identifying annotation errors semi-automatically. We found that the corpus has the variety and quality to develop and benchmark text classification and event extraction systems in a cross-context setting, which contributes to the generalizability and robustness of automated text processing systems. This corpus and the reported results will set the currently lacking common ground in automated protest event collection studies.
Overview of CLEF 2019 Lab ProtestNews: Extracting Protests from News in a Cross-context Setting
Aug 01, 2020


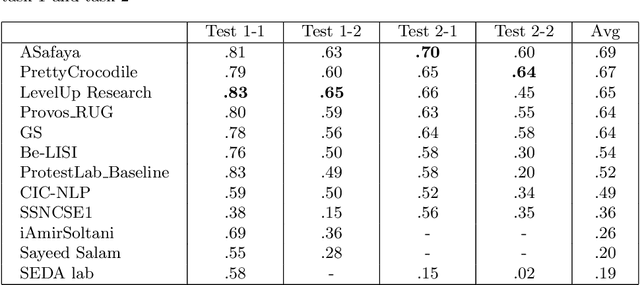
We present an overview of the CLEF-2019 Lab ProtestNews on Extracting Protests from News in the context of generalizable natural language processing. The lab consists of document, sentence, and token level information classification and extraction tasks that were referred as task 1, task 2, and task 3 respectively in the scope of this lab. The tasks required the participants to identify protest relevant information from English local news at one or more aforementioned levels in a cross-context setting, which is cross-country in the scope of this lab. The training and development data were collected from India and test data was collected from India and China. The lab attracted 58 teams to participate in the lab. 12 and 9 of these teams submitted results and working notes respectively. We have observed neural networks yield the best results and the performance drops significantly for majority of the submissions in the cross-country setting, which is China.