 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-context News Corpus for Protest Events related Knowledge Base Construction
Paper and Code
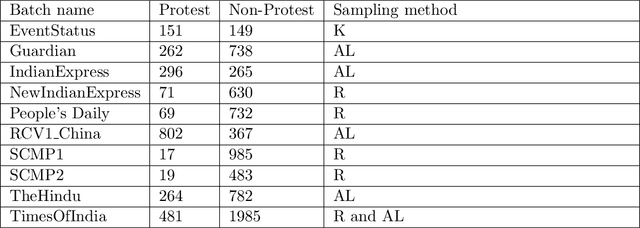



We describe a gold standard corpus of protest events that comprise of various local and international sources from various countries in English. The corpus contains document, sentence, and token level annotations. This corpus facilitates creating machine learning models that automatically classify news articles and extract protest event-related information, constructing knowledge bases which enable comparative social and political science studies. For each news source, the annotation starts on random samples of news articles and continues with samples that are drawn using active learning. Each batch of samples was annotated by two social and political scientists, adjudicated by an annotation supervisor, and was improved by identifying annotation errors semi-automatically. We found that the corpus has the variety and quality to develop and benchmark text classification and event extraction systems in a cross-context setting, which contributes to the generalizability and robustness of automated text processing systems. This corpus and the reported results will set the currently lacking common ground in automated protest event collection studies.