 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrightCookies at SemEval-2025 Task 9: Exploring Data Augmentation for Food Hazard Classification
Apr 29, 2025This paper presents our system developed for the SemEval-2025 Task 9: The Food Hazard Detection Challenge. The shared task's objective is to evaluate explainable classification systems for classifying hazards and products in two levels of granularity from food recall incident reports. In this work, we propose text augmentation techniques as a way to improve poor performance on minority classes and compare their effect for each category on various transformer and machine learning models. We explore three word-level data augmentation techniques, namely synonym replacement, random word swapping, and contextual word insertion. The results show that transformer models tend to have a better overall performance. None of the three augmentation techniques consistently improved overall performance for classifying hazards and products. We observed a statistically significant improvement (P < 0.05) in the fine-grained categories when using the BERT model to compare the baseline with each augmented model. Compared to the baseline, the contextual words insertion augmentation improved the accuracy of predictions for the minority hazard classes by 6%. This suggests that targeted augmentation of minority classes can improve the performance of transformer models.
Beyond the Veil of Similarity: Quantifying Semantic Continuity in Explainable AI
Jul 17, 2024We introduce a novel metric for measuring semantic continuity in Explainable AI methods and machine learning models. We posit that for models to be truly interpretable and trustworthy, similar inputs should yield similar explanations, reflecting a consistent semantic understanding. By leveraging XAI techniques, we assess semantic continuity in the task of image recognition. We conduct experiments to observe how incremental changes in input affect the explanations provided by different XAI methods. Through this approach, we aim to evaluate the models' capability to generalize and abstract semantic concepts accurately and to evaluate different XAI methods in correctly capturing the model behaviour. This paper contributes to the broader discourse on AI interpretability by proposing a quantitative measure for semantic continuity for XAI methods, offering insights into the models' and explainers' internal reasoning processes, and promoting more reliable and transparent AI systems.
Federated learning in food research
Jun 10, 2024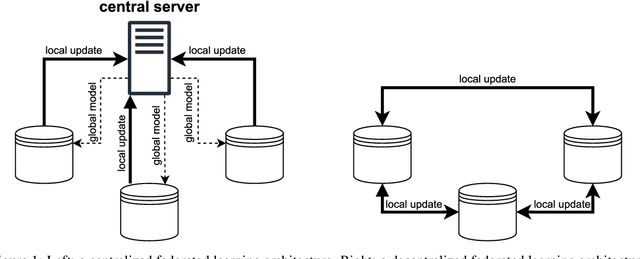
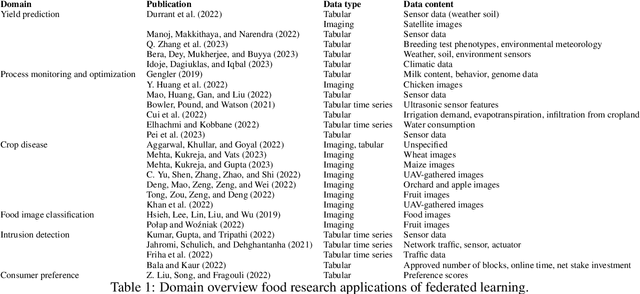
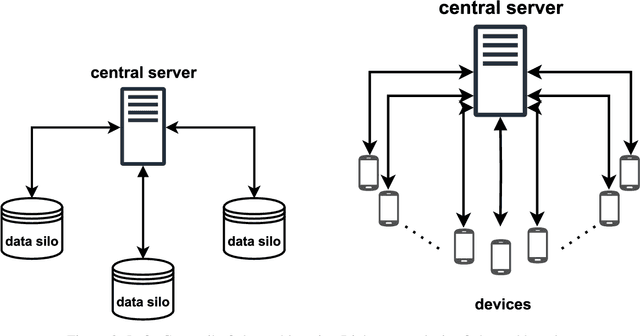

Research in the food domain is at times limited due to data sharing obstacles, such as data ownership, privacy requirements, and regulations. While important, these obstacles can restrict data-driven methods such as machine learning. Federated learning, the approach of training models on locally kept data and only sharing the learned parameters, is a potential technique to alleviate data sharing obstacles. This systematic review investigates the use of federated learning within the food domain, structures included papers in a federated learning framework, highlights knowledge gaps, and discusses potential applications. A total of 41 papers were included in the review. The current applications include solutions to water and milk quality assessment, cybersecurity of water processing, pesticide residue risk analysis, weed detection, and fraud detection, focusing on centralized horizontal federated learning. One of the gaps found was the lack of vertical or transfer federated learning and decentralized architectures.
GLOCON Database: Design Decisions and User Manual (v1.0)
May 28, 2024
GLOCON is a database of contentious events automatically extracted from national news sources from various countries in multiple languages. National news sources are utilized, and complete news archives are processed to create an event list for each source. Automation is achieved using a gold standard corpus sampled randomly from complete news archives (Y\"or\"uk et al. 2022) and all annotated by at least two domain experts based on the event definition provided in Duru\c{s}an et al. (2022).
Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2023): Workshop and Shared Task Report
Dec 02, 2023We provide a summary of the sixth edition of the CASE workshop that is held in the scope of RANLP 2023. The workshop consists of regular papers, three keynotes, working papers of shared task participants, and shared task overview papers. This workshop series has been bringing together all aspects of event information collection across technical and social science fields. In addition to contributing to the progress in text based event extraction, the workshop provides a space for the organization of a multimodal event information collection task.
Challenges and Applications of Automated Extraction of Socio-political Events from Text : Workshop and Shared Task Report
Nov 21, 2022We provide a summary of the fifth edition of the CASE workshop that is held in the scope of EMNLP 2022. The workshop consists of regular papers, two keynotes, working papers of shared task participants, and task overview papers. This workshop has been bringing together all aspects of event information collection across technical and social science fields. In addition to the progress in depth, the submission and acceptance of multimodal approaches show the widening of this interdisciplinary research topic.
Extended Multilingual Protest News Detection -- Shared Task 1, CASE 2021 and 2022
Nov 21, 2022



We report results of the CASE 2022 Shared Task 1 on Multilingual Protest Event Detection. This task is a continuation of CASE 2021 that consists of four subtasks that are i) document classification, ii) sentence classification, iii) event sentence coreference identification, and iv) event extraction. The CASE 2022 extension consists of expanding the test data with more data in previously available languages, namely, English, Hindi, Portuguese, and Spanish, and adding new test data in Mandarin, Turkish, and Urdu for Sub-task 1, document classification. The training data from CASE 2021 in English, Portuguese and Spanish were utilized. Therefore, predicting document labels in Hindi, Mandarin, Turkish, and Urdu occurs in a zero-shot setting. The CASE 2022 workshop accepts reports on systems developed for predicting test data of CASE 2021 as well. We observe that the best systems submitted by CASE 2022 participants achieve between 79.71 and 84.06 F1-macro for new languages in a zero-shot setting. The winning approaches are mainly ensembling models and merging data in multiple languages. The best two submissions on CASE 2021 data outperform submissions from last year for Subtask 1 and Subtask 2 in all languages. Only the following scenarios were not outperformed by new submissions on CASE 2021: Subtask 3 Portuguese \& Subtask 4 English.
Utilizing coarse-grained data in low-data settings for event extraction
May 11, 2022
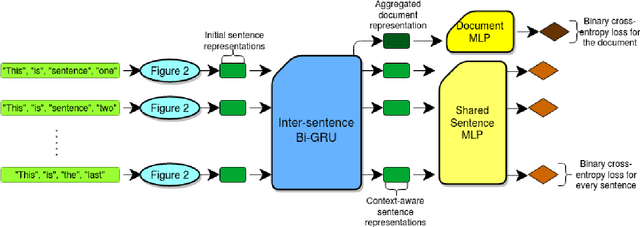
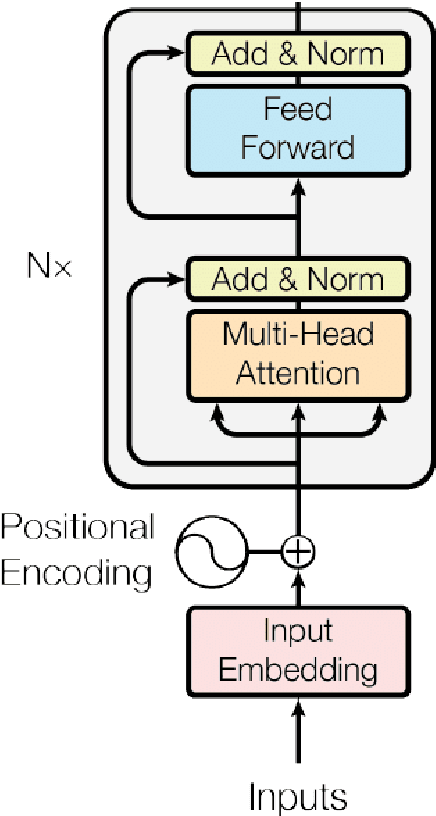
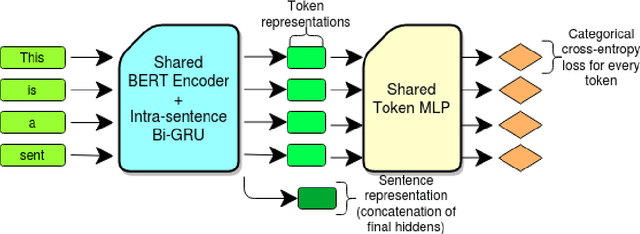
Annotating text data for event information extraction systems is hard, expensive, and error-prone. We investigate the feasibility of integrating coarse-grained data (document or sentence labels), which is far more feasible to obtain, instead of annotating more documents. We utilize a multi-task model with two auxiliary tasks, document and sentence binary classification, in addition to the main task of token classification. We perform a series of experiments with varying data regimes for the aforementioned integration. Results show that while introducing extra coarse-grained data offers greater improvement and robustness, a gain is still possible with only the addition of negative documents that have no information on any event.
Event Coreference Resolution for Contentious Politics Events
Mar 18, 2022
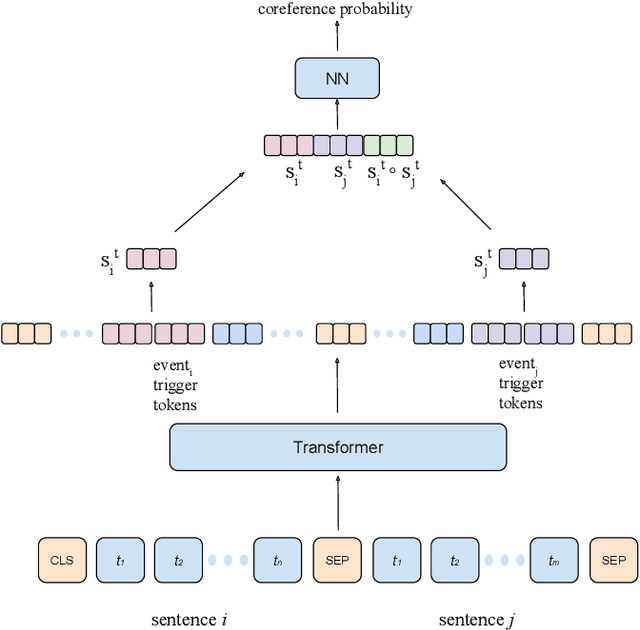


We propose a dataset for event coreference resolution, which is based on random samples drawn from multiple sources, languages, and countries. Early scholarship on event information collection has not quantified the contribution of event coreference resolution. We prepared and analyzed a representative multilingual corpus and measured the performance and contribution of the state-of-the-art event coreference resolution approaches. We found that almost half of the event mentions in documents co-occur with other event mentions and this makes it inevitable to obtain erroneous or partial event information. We showed that event coreference resolution could help improving this situation. Our contribution sheds light on a challenge that has been overlooked or hard to study to date. Future event information collection studies can be designed based on the results we present in this report. The repository for this study is on https://github.com/emerging-welfare/ECR4-Contentious-Politics.
COVCOR20 at WNUT-2020 Task 2: An Attempt to Combine Deep Learning and Expert rules
Sep 07, 2020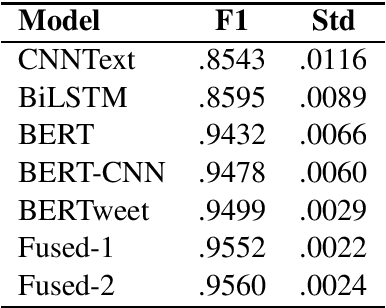
In the scope of WNUT-2020 Task 2, we developed various text classification systems, using deep learning models and one using linguistically informed rules. While both of the deep learning systems outperformed the system using the linguistically informed rules, we found that through the integration of (the output of) the three systems a better performance could be achieved than the standalone performance of each approach in a cross-validation setting. However, on the test data the performance of the integration was slightly lower than our best performing deep learning model. These results hardly indicate any progress in line of integrating machine learning and expert rules driven systems. We expect that the release of the annotation manuals and gold labels of the test data after this workshop will shed light on these perplexing results.