 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Inference On Foundation Models For Remote Sensing Text-to-image Retrieval With Complex Queries
Dec 16, 2025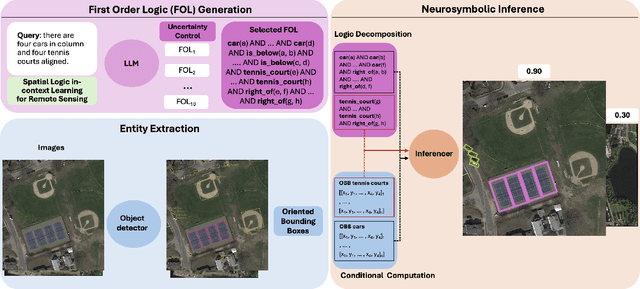
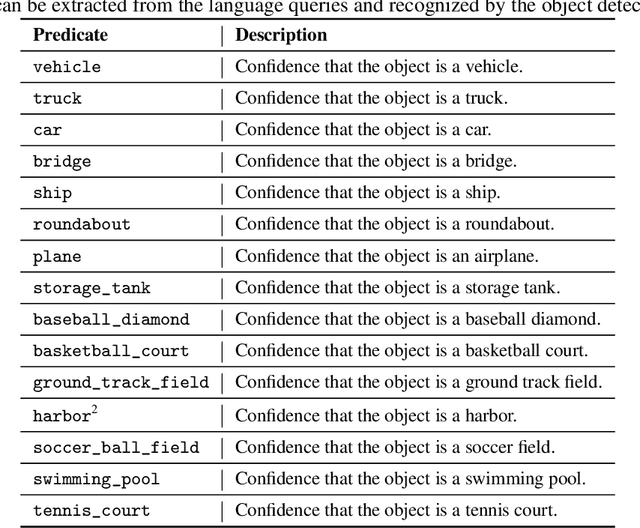

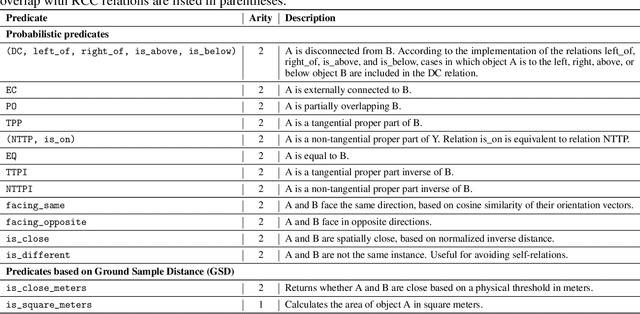
Text-to-image retrieval in remote sensing (RS) has advanced rapidly with the rise of large vision-language models (LVLMs) tailored for aerial and satellite imagery, culminating in remote sensing large vision-language models (RS-LVLMS). However, limited explainability and poor handling of complex spatial relations remain key challenges for real-world use. To address these issues, we introduce RUNE (Reasoning Using Neurosymbolic Entities), an approach that combines Large Language Models (LLMs) with neurosymbolic AI to retrieve images by reasoning over the compatibility between detected entities and First-Order Logic (FOL) expressions derived from text queries. Unlike RS-LVLMs that rely on implicit joint embeddings, RUNE performs explicit reasoning, enhancing performance and interpretability. For scalability, we propose a logic decomposition strategy that operates on conditioned subsets of detected entities, guaranteeing shorter execution time compared to neural approaches. Rather than using foundation models for end-to-end retrieval, we leverage them only to generate FOL expressions, delegating reasoning to a neurosymbolic inference module. For evaluation we repurpose the DOTA dataset, originally designed for object detection, by augmenting it with more complex queries than in existing benchmarks. We show the LLM's effectiveness in text-to-logic translation and compare RUNE with state-of-the-art RS-LVLMs, demonstrating superior performance. We introduce two metrics, Retrieval Robustness to Query Complexity (RRQC) and Retrieval Robustness to Image Uncertainty (RRIU), which evaluate performance relative to query complexity and image uncertainty. RUNE outperforms joint-embedding models in complex RS retrieval tasks, offering gains in performance, robustness, and explainability. We show RUNE's potential for real-world RS applications through a use case on post-flood satellite image retrieval.
Large Language Models are Unreliable for Cyber Threat Intelligence
Mar 29, 2025Several recent works have argued that Large Language Models (LLMs) can be used to tame the data deluge in the cybersecurity field, by improving the automation of Cyber Threat Intelligence (CTI) tasks. This work presents an evaluation methodology that other than allowing to test LLMs on CTI tasks when using zero-shot learning, few-shot learning and fine-tuning, also allows to quantify their consistency and their confidence level. We run experiments with three state-of-the-art LLMs and a dataset of 350 threat intelligence reports and present new evidence of potential security risks in relying on LLMs for CTI. We show how LLMs cannot guarantee sufficient performance on real-size reports while also being inconsistent and overconfident. Few-shot learning and fine-tuning only partially improve the results, thus posing doubts about the possibility of using LLMs for CTI scenarios, where labelled datasets are lacking and where confidence is a fundamental factor.
Beyond the Veil of Similarity: Quantifying Semantic Continuity in Explainable AI
Jul 17, 2024We introduce a novel metric for measuring semantic continuity in Explainable AI methods and machine learning models. We posit that for models to be truly interpretable and trustworthy, similar inputs should yield similar explanations, reflecting a consistent semantic understanding. By leveraging XAI techniques, we assess semantic continuity in the task of image recognition. We conduct experiments to observe how incremental changes in input affect the explanations provided by different XAI methods. Through this approach, we aim to evaluate the models' capability to generalize and abstract semantic concepts accurately and to evaluate different XAI methods in correctly capturing the model behaviour. This paper contributes to the broader discourse on AI interpretability by proposing a quantitative measure for semantic continuity for XAI methods, offering insights into the models' and explainers' internal reasoning processes, and promoting more reliable and transparent AI systems.