Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing coarse-grained data in low-data settings for event extraction
Paper and Code

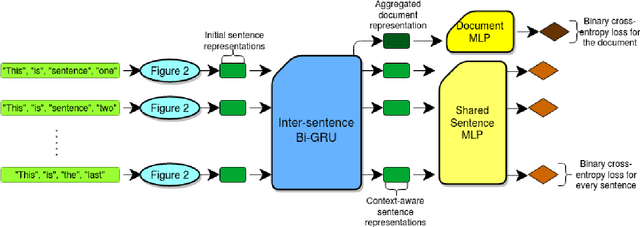
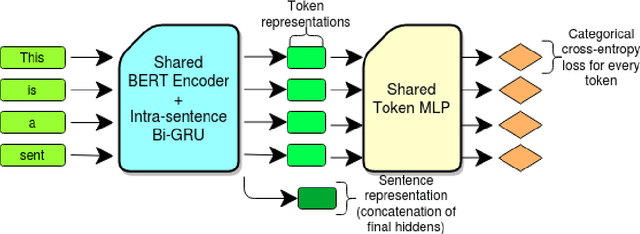
Annotating text data for event information extraction systems is hard, expensive, and error-prone. We investigate the feasibility of integrating coarse-grained data (document or sentence labels), which is far more feasible to obtain, instead of annotating more documents. We utilize a multi-task model with two auxiliary tasks, document and sentence binary classification, in addition to the main task of token classification. We perform a series of experiments with varying data regimes for the aforementioned integration. Results show that while introducing extra coarse-grained data offers greater improvement and robustness, a gain is still possible with only the addition of negative documents that have no information on any event.
* A Dissertation Submitted to the Graduate School of Sciences and
Engineering in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Computer Science and Engineering
View paper on