 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Stable and Personalised Profiles for Lexical Alignment in Spoken Human-Agent Dialogue
Sep 04, 2025Lexical alignment, where speakers start to use similar words across conversation, is known to contribute to successful communication. However, its implementation in conversational agents remains underexplored, particularly considering the recent advancements in large language models (LLMs). As a first step towards enabling lexical alignment in human-agent dialogue, this study draws on strategies for personalising conversational agents and investigates the construction of stable, personalised lexical profiles as a basis for lexical alignment. Specifically, we varied the amounts of transcribed spoken data used for construction as well as the number of items included in the profiles per part-of-speech (POS) category and evaluated profile performance across time using recall, coverage, and cosine similarity metrics. It was shown that smaller and more compact profiles, created after 10 min of transcribed speech containing 5 items for adjectives, 5 items for conjunctions, and 10 items for adverbs, nouns, pronouns, and verbs each, offered the best balance in both performance and data efficiency. In conclusion, this study offers practical insights into constructing stable, personalised lexical profiles, taking into account minimal data requirements, serving as a foundational step toward lexical alignment strategies in conversational agents.
BrightCookies at SemEval-2025 Task 9: Exploring Data Augmentation for Food Hazard Classification
Apr 29, 2025This paper presents our system developed for the SemEval-2025 Task 9: The Food Hazard Detection Challenge. The shared task's objective is to evaluate explainable classification systems for classifying hazards and products in two levels of granularity from food recall incident reports. In this work, we propose text augmentation techniques as a way to improve poor performance on minority classes and compare their effect for each category on various transformer and machine learning models. We explore three word-level data augmentation techniques, namely synonym replacement, random word swapping, and contextual word insertion. The results show that transformer models tend to have a better overall performance. None of the three augmentation techniques consistently improved overall performance for classifying hazards and products. We observed a statistically significant improvement (P < 0.05) in the fine-grained categories when using the BERT model to compare the baseline with each augmented model. Compared to the baseline, the contextual words insertion augmentation improved the accuracy of predictions for the minority hazard classes by 6%. This suggests that targeted augmentation of minority classes can improve the performance of transformer models.
SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals
Nov 23, 2019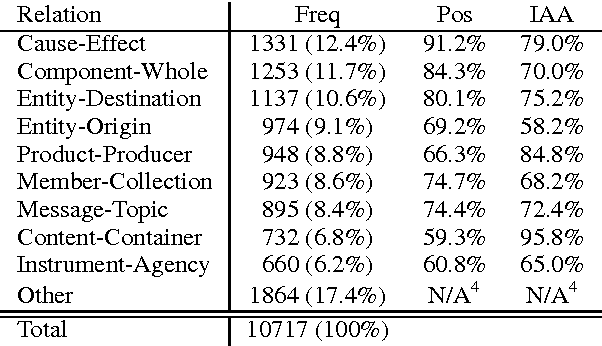
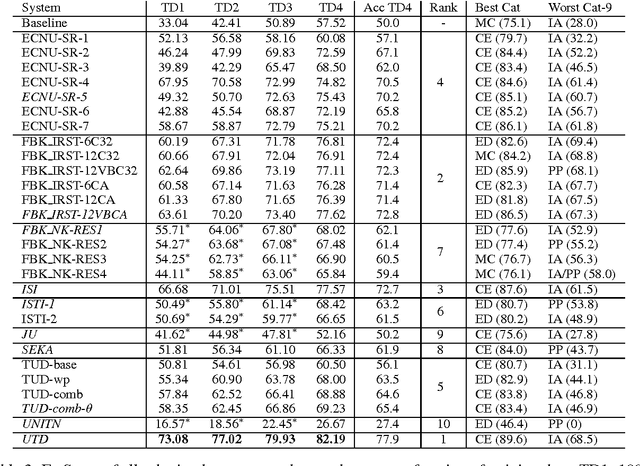
In response to the continuing research interest in computational semantic analysis, we have proposed a new task for SemEval-2010: multi-way classification of mutually exclusive semantic relations between pairs of nominals. The task is designed to compare different approaches to the problem and to provide a standard testbed for future research. In this paper, we define the task, describe the creation of the datasets, and discuss the results of the participating 28 systems submitted by 10 teams.
* semantic relations, nominals
SemEval-2013 Task 4: Free Paraphrases of Noun Compounds
Nov 23, 2019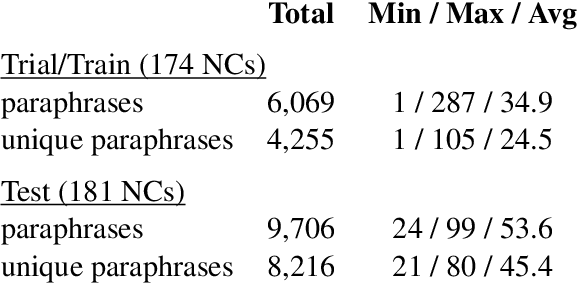
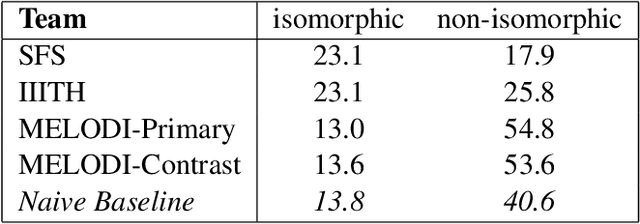
In this paper, we describe SemEval-2013 Task 4: the definition, the data, the evaluation and the results. The task is to capture some of the meaning of English noun compounds via paraphrasing. Given a two-word noun compound, the participating system is asked to produce an explicitly ranked list of its free-form paraphrases. The list is automatically compared and evaluated against a similarly ranked list of paraphrases proposed by human annotators, recruited and managed through Amazon's Mechanical Turk. The comparison of raw paraphrases is sensitive to syntactic and morphological variation. The "gold" ranking is based on the relative popularity of paraphrases among annotators. To make the ranking more reliable, highly similar paraphrases are grouped, so as to downplay superficial differences in syntax and morphology. Three systems participated in the task. They all beat a simple baseline on one of the two evaluation measures, but not on both measures. This shows that the task is difficult.
* noun compounds, paraphrasing verbs, semantic interpretation, multi-word expressions, MWEs
Unraveling reported dreams with text analytics
Dec 12, 2016
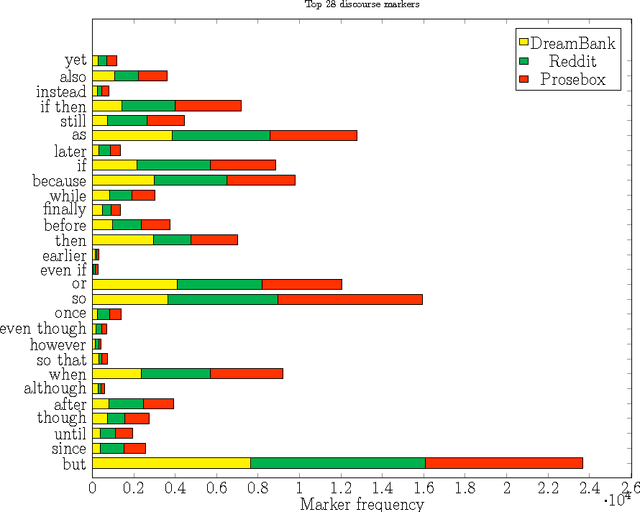

We investigate what distinguishes reported dreams from other personal narratives. The continuity hypothesis, stemming from psychological dream analysis work, states that most dreams refer to a person's daily life and personal concerns, similar to other personal narratives such as diary entries. Differences between the two texts may reveal the linguistic markers of dream text, which could be the basis for new dream analysis work and for the automatic detection of dream descriptions. We used three text analytics methods: text classification, topic modeling, and text coherence analysis, and applied these methods to a balanced set of texts representing dreams, diary entries, and other personal stories. We observed that dream texts could be distinguished from other personal narratives nearly perfectly, mostly based on the presence of uncertainty markers and descriptions of scenes. Important markers for non-dream narratives are specific time expressions and conversational expressions. Dream texts also exhibit a lower discourse coherence than other personal narratives.