 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Assistant Language Understanding On Device
Aug 07, 2023
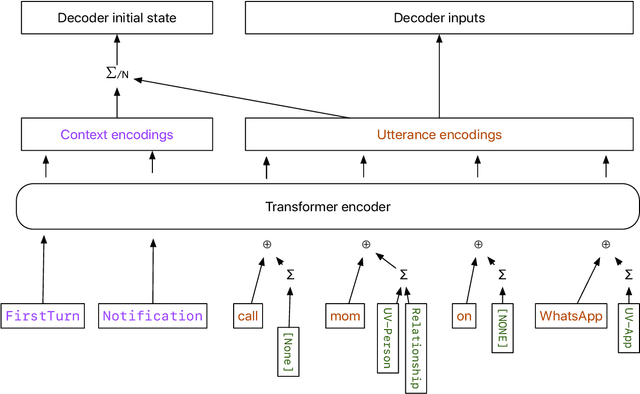
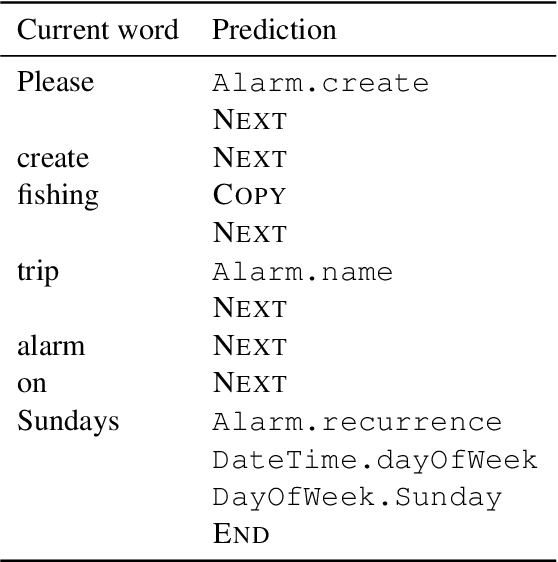

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals
Nov 23, 2019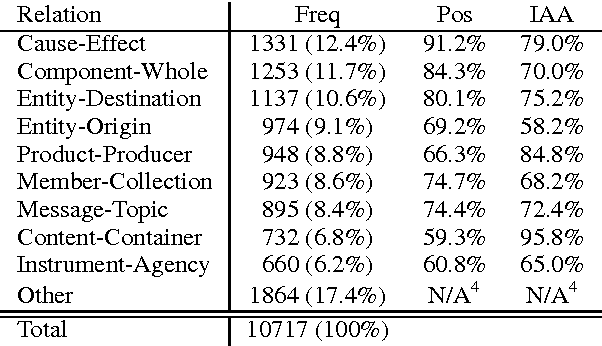
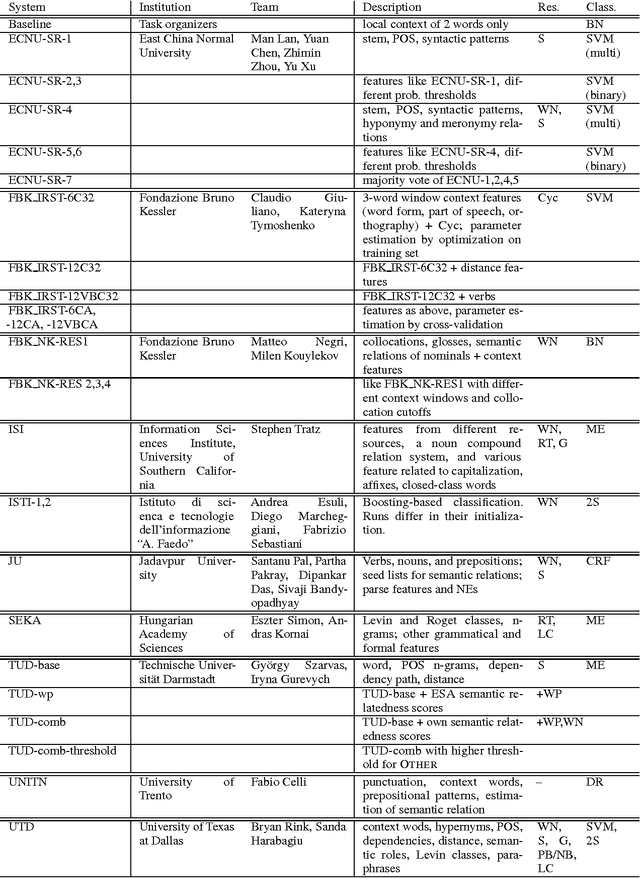
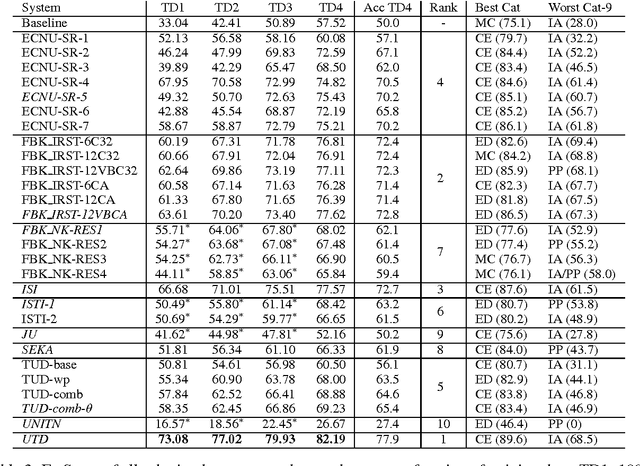
In response to the continuing research interest in computational semantic analysis, we have proposed a new task for SemEval-2010: multi-way classification of mutually exclusive semantic relations between pairs of nominals. The task is designed to compare different approaches to the problem and to provide a standard testbed for future research. In this paper, we define the task, describe the creation of the datasets, and discuss the results of the participating 28 systems submitted by 10 teams.
* semantic relations, nominals
SemEval-2013 Task 4: Free Paraphrases of Noun Compounds
Nov 23, 2019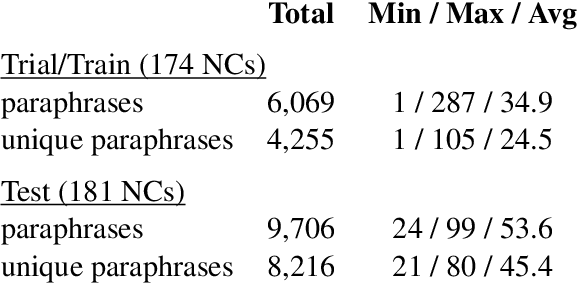
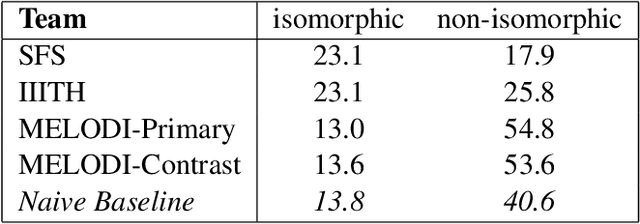
In this paper, we describe SemEval-2013 Task 4: the definition, the data, the evaluation and the results. The task is to capture some of the meaning of English noun compounds via paraphrasing. Given a two-word noun compound, the participating system is asked to produce an explicitly ranked list of its free-form paraphrases. The list is automatically compared and evaluated against a similarly ranked list of paraphrases proposed by human annotators, recruited and managed through Amazon's Mechanical Turk. The comparison of raw paraphrases is sensitive to syntactic and morphological variation. The "gold" ranking is based on the relative popularity of paraphrases among annotators. To make the ranking more reliable, highly similar paraphrases are grouped, so as to downplay superficial differences in syntax and morphology. Three systems participated in the task. They all beat a simple baseline on one of the two evaluation measures, but not on both measures. This shows that the task is difficult.
* noun compounds, paraphrasing verbs, semantic interpretation, multi-word expressions, MWEs
Morph-fitting: Fine-Tuning Word Vector Spaces with Simple Language-Specific Rules
Jun 01, 2017
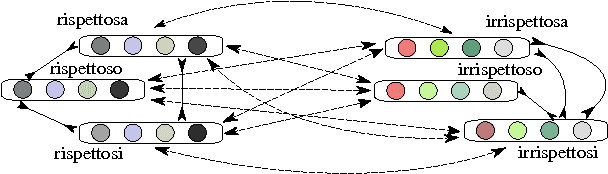

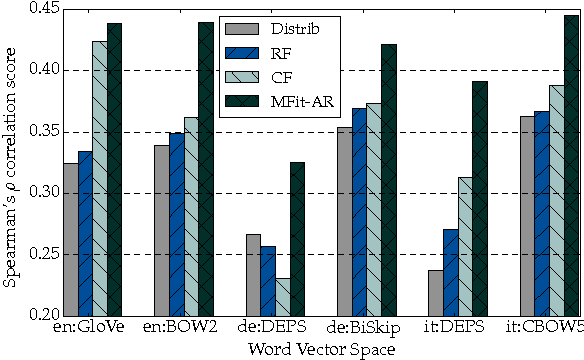
Morphologically rich languages accentuate two properties of distributional vector space models: 1) the difficulty of inducing accurate representations for low-frequency word forms; and 2) insensitivity to distinct lexical relations that have similar distributional signatures. These effects are detrimental for language understanding systems, which may infer that 'inexpensive' is a rephrasing for 'expensive' or may not associate 'acquire' with 'acquires'. In this work, we propose a novel morph-fitting procedure which moves past the use of curated semantic lexicons for improving distributional vector spaces. Instead, our method injects morphological constraints generated using simple language-specific rules, pulling inflectional forms of the same word close together and pushing derivational antonyms far apart. In intrinsic evaluation over four languages, we show that our approach: 1) improves low-frequency word estimates; and 2) boosts the semantic quality of the entire word vector collection. Finally, we show that morph-fitted vectors yield large gains in the downstream task of dialogue state tracking, highlighting the importance of morphology for tackling long-tail phenomena in language understanding tasks.
Semantic Specialisation of Distributional Word Vector Spaces using Monolingual and Cross-Lingual Constraints
Jun 01, 2017



We present Attract-Repel, an algorithm for improving the semantic quality of word vectors by injecting constraints extracted from lexical resources. Attract-Repel facilitates the use of constraints from mono- and cross-lingual resources, yielding semantically specialised cross-lingual vector spaces. Our evaluation shows that the method can make use of existing cross-lingual lexicons to construct high-quality vector spaces for a plethora of different languages, facilitating semantic transfer from high- to lower-resource ones. The effectiveness of our approach is demonstrated with state-of-the-art results on semantic similarity datasets in six languages. We next show that Attract-Repel-specialised vectors boost performance in the downstream task of dialogue state tracking (DST) across multiple languages. Finally, we show that cross-lingual vector spaces produced by our algorithm facilitate the training of multilingual DST models, which brings further performance improvements.
Neural Belief Tracker: Data-Driven Dialogue State Tracking
Apr 21, 2017
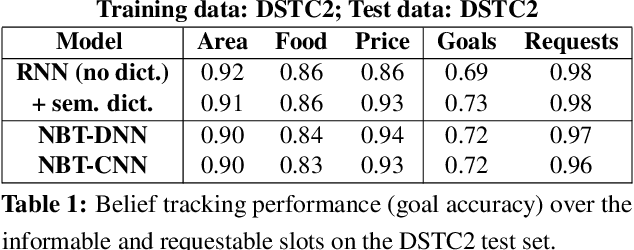
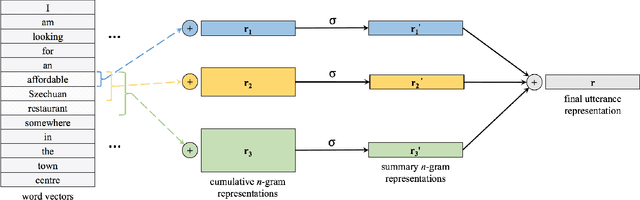

One of the core components of modern spoken dialogue systems is the belief tracker, which estimates the user's goal at every step of the dialogue. However, most current approaches have difficulty scaling to larger, more complex dialogue domains. This is due to their dependency on either: a) Spoken Language Understanding models that require large amounts of annotated training data; or b) hand-crafted lexicons for capturing some of the linguistic variation in users' language. We propose a novel Neural Belief Tracking (NBT) framework which overcomes these problems by building on recent advances in representation learning. NBT models reason over pre-trained word vectors, learning to compose them into distributed representations of user utterances and dialogue context. Our evaluation on two datasets shows that this approach surpasses past limitations, matching the performance of state-of-the-art models which rely on hand-crafted semantic lexicons and outperforming them when such lexicons are not provided.
Counter-fitting Word Vectors to Linguistic Constraints
Mar 02, 2016



In this work, we present a novel counter-fitting method which injects antonymy and synonymy constraints into vector space representations in order to improve the vectors' capability for judging semantic similarity. Applying this method to publicly available pre-trained word vectors leads to a new state of the art performance on the SimLex-999 dataset. We also show how the method can be used to tailor the word vector space for the downstream task of dialogue state tracking, resulting in robust improvements across different dialogue domains.
Multi-domain Dialog State Tracking using Recurrent Neural Networks
Jun 23, 2015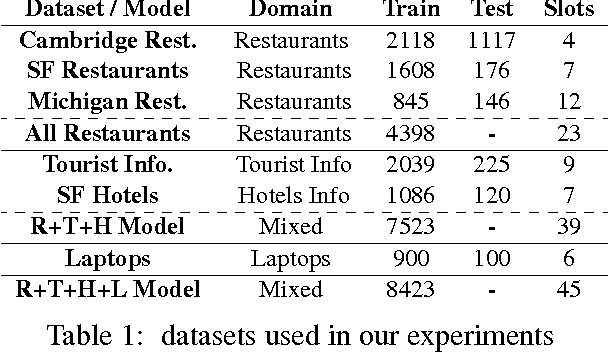

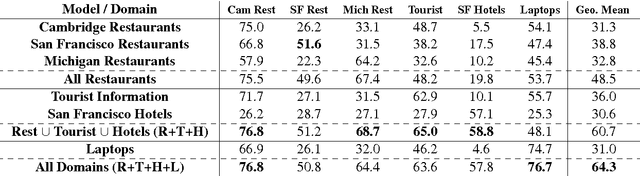

Dialog state tracking is a key component of many modern dialog systems, most of which are designed with a single, well-defined domain in mind. This paper shows that dialog data drawn from different dialog domains can be used to train a general belief tracking model which can operate across all of these domains, exhibiting superior performance to each of the domain-specific models. We propose a training procedure which uses out-of-domain data to initialise belief tracking models for entirely new domains. This procedure leads to improvements in belief tracking performance regardless of the amount of in-domain data available for training the model.