 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Relations and Deep Learning
Sep 14, 2020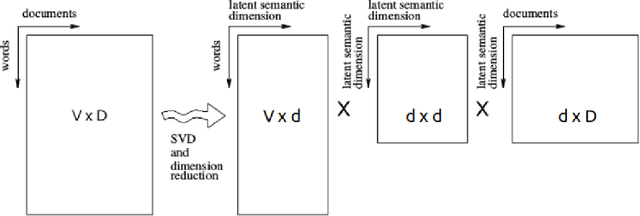
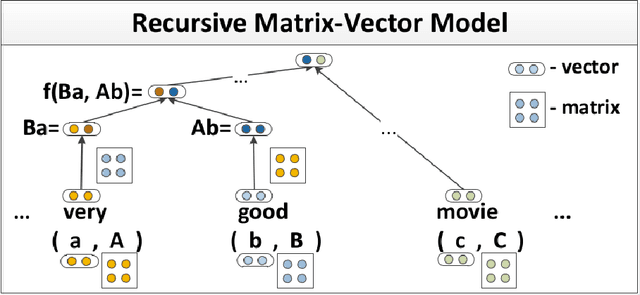
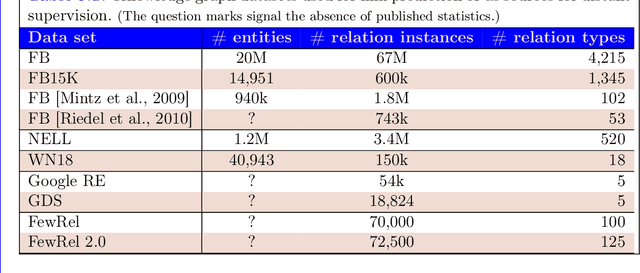
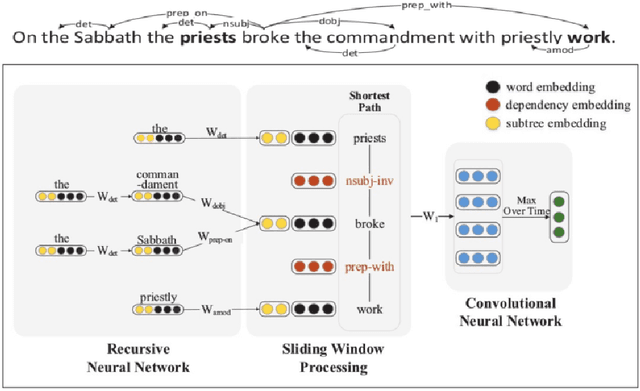
The second edition of "Semantic Relations Between Nominals" (by Vivi Nastase, Stan Szpakowicz, Preslav Nakov and Diarmuid \'O S\'eaghdha) will be published by Morgan & Claypool. A new Chapter 5 of the book discusses relation classification/extraction in the deep-learning paradigm which arose after the first edition appeared. This is a preview of Chapter 5, made public by the kind permission of Morgan & Claypool.
SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals
Nov 23, 2019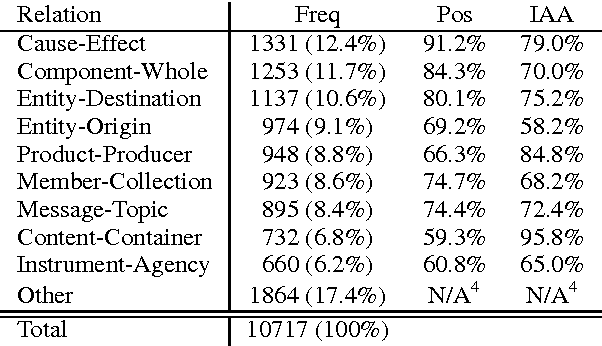
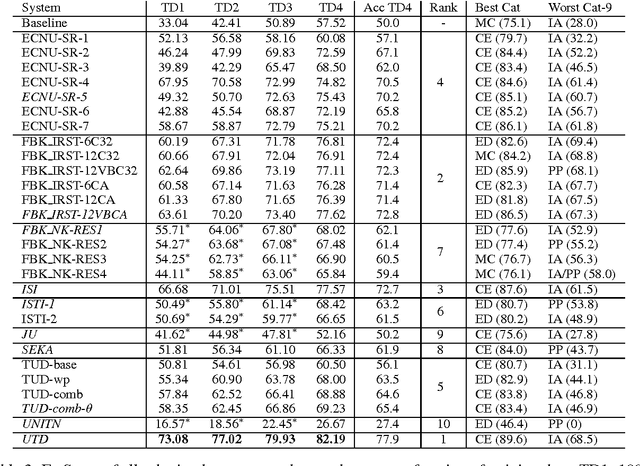
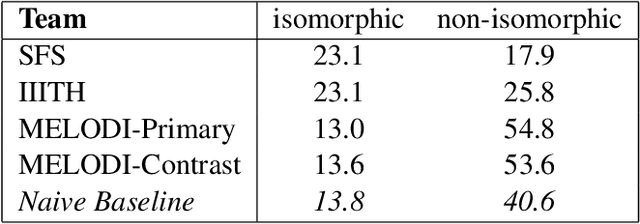
In response to the continuing research interest in computational semantic analysis, we have proposed a new task for SemEval-2010: multi-way classification of mutually exclusive semantic relations between pairs of nominals. The task is designed to compare different approaches to the problem and to provide a standard testbed for future research. In this paper, we define the task, describe the creation of the datasets, and discuss the results of the participating 28 systems submitted by 10 teams.
* semantic relations, nominals
SemEval-2013 Task 4: Free Paraphrases of Noun Compounds
Nov 23, 2019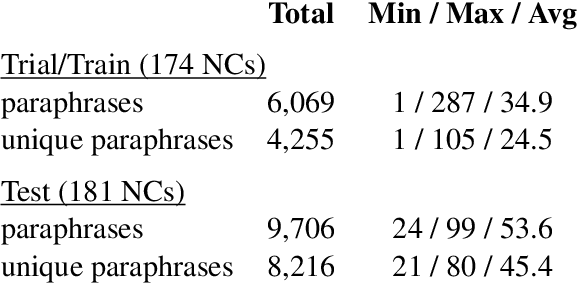
In this paper, we describe SemEval-2013 Task 4: the definition, the data, the evaluation and the results. The task is to capture some of the meaning of English noun compounds via paraphrasing. Given a two-word noun compound, the participating system is asked to produce an explicitly ranked list of its free-form paraphrases. The list is automatically compared and evaluated against a similarly ranked list of paraphrases proposed by human annotators, recruited and managed through Amazon's Mechanical Turk. The comparison of raw paraphrases is sensitive to syntactic and morphological variation. The "gold" ranking is based on the relative popularity of paraphrases among annotators. To make the ranking more reliable, highly similar paraphrases are grouped, so as to downplay superficial differences in syntax and morphology. Three systems participated in the task. They all beat a simple baseline on one of the two evaluation measures, but not on both measures. This shows that the task is difficult.
* noun compounds, paraphrasing verbs, semantic interpretation, multi-word expressions, MWEs
Roget's Thesaurus: a Lexical Resource to Treasure
Apr 01, 2012This paper presents the steps involved in creating an electronic lexical knowledge base from the 1987 Penguin edition of Roget's Thesaurus. Semantic relations are labelled with the help of WordNet. The two resources are compared in a qualitative and quantitative manner. Differences in the organization of the lexical material are discussed, as well as the possibility of merging both resources.
* 6 pages
Not As Easy As It Seems: Automating the Construction of Lexical Chains Using Roget's Thesaurus
Apr 01, 2012Morris and Hirst present a method of linking significant words that are about the same topic. The resulting lexical chains are a means of identifying cohesive regions in a text, with applications in many natural language processing tasks, including text summarization. The first lexical chains were constructed manually using Roget's International Thesaurus. Morris and Hirst wrote that automation would be straightforward given an electronic thesaurus. All applications so far have used WordNet to produce lexical chains, perhaps because adequate electronic versions of Roget's were not available until recently. We discuss the building of lexical chains using an electronic version of Roget's Thesaurus. We implement a variant of the original algorithm, and explain the necessary design decisions. We include a comparison with other implementations.
* 5 pages
Roget's Thesaurus and Semantic Similarity
Apr 01, 2012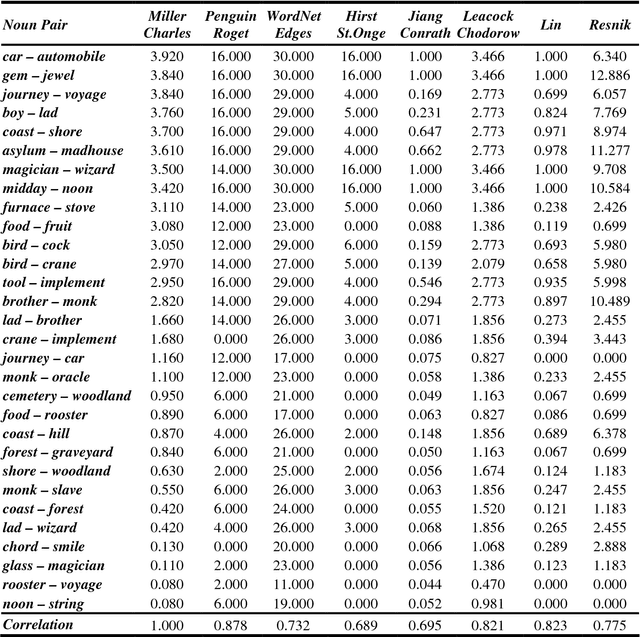



We have implemented a system that measures semantic similarity using a computerized 1987 Roget's Thesaurus, and evaluated it by performing a few typical tests. We compare the results of these tests with those produced by WordNet-based similarity measures. One of the benchmarks is Miller and Charles' list of 30 noun pairs to which human judges had assigned similarity measures. We correlate these measures with those computed by several NLP systems. The 30 pairs can be traced back to Rubenstein and Goodenough's 65 pairs, which we have also studied. Our Roget's-based system gets correlations of .878 for the smaller and .818 for the larger list of noun pairs; this is quite close to the .885 that Resnik obtained when he employed humans to replicate the Miller and Charles experiment. We further evaluate our measure by using Roget's and WordNet to answer 80 TOEFL, 50 ESL and 300 Reader's Digest questions: the correct synonym must be selected amongst a group of four words. Our system gets 78.75%, 82.00% and 74.33% of the questions respectively.
* 8 pages