 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoget's Thesaurus and Semantic Similarity
Paper and Code
Apr 01, 2012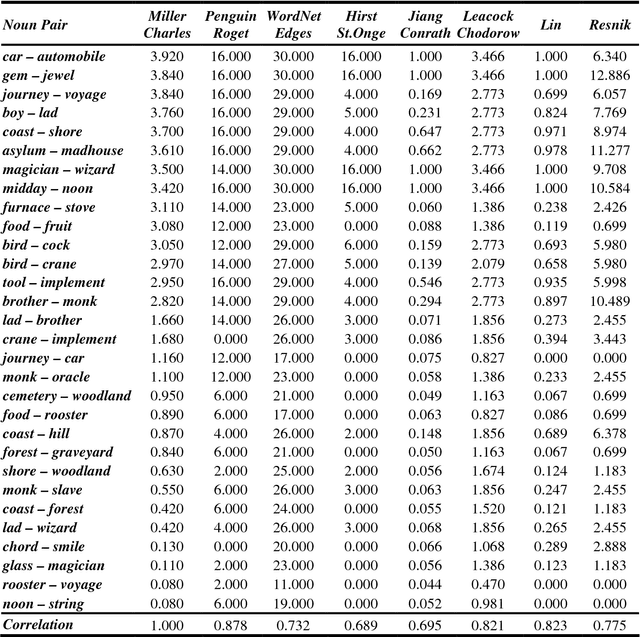



We have implemented a system that measures semantic similarity using a computerized 1987 Roget's Thesaurus, and evaluated it by performing a few typical tests. We compare the results of these tests with those produced by WordNet-based similarity measures. One of the benchmarks is Miller and Charles' list of 30 noun pairs to which human judges had assigned similarity measures. We correlate these measures with those computed by several NLP systems. The 30 pairs can be traced back to Rubenstein and Goodenough's 65 pairs, which we have also studied. Our Roget's-based system gets correlations of .878 for the smaller and .818 for the larger list of noun pairs; this is quite close to the .885 that Resnik obtained when he employed humans to replicate the Miller and Charles experiment. We further evaluate our measure by using Roget's and WordNet to answer 80 TOEFL, 50 ESL and 300 Reader's Digest questions: the correct synonym must be selected amongst a group of four words. Our system gets 78.75%, 82.00% and 74.33% of the questions respectively.