 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
May 04, 2026Human-level agentic intelligence extends beyond low-level geometric perception, evolving from recognizing where things are to understanding what they are for. While existing benchmarks effectively evaluate the geometric perception capabilities of multimodal large language models (MLLMs), they fall short of probing the higher-order cognitive abilities required for grounded intelligence. To address this gap, we introduce the Spatial-Functional Intelligence Benchmark (SFI-Bench), a video-based benchmark with over 1,500 expert-annotated questions derived from diverse egocentric indoor video scans. SFI-Bench systematically evaluates two complementary dimensions of advanced reasoning: (1) Structured Spatial Reasoning, which requires understanding complex layouts and forming coherent spatial representations, and (2) Functional Reasoning, which involves inferring object affordances and their context-dependent utility. The benchmark includes tasks such as conditional counting, multi-hop relational reasoning, functional pairing, and knowledge-grounded troubleshooting, directly challenging models to integrate perception, memory, and inference. Our experiments reveal that current MLLMs consistently struggle to combine spatial memory with functional reasoning and external knowledge, highlighting a critical bottleneck in achieving grounded intelligence. SFI-Bench therefore provides a diagnostic tool for measuring progress toward more cognitively capable and truly grounded multimodal agents.
SynthDST: Synthetic Data is All You Need for Few-Shot Dialog State Tracking
Feb 03, 2024



In-context learning with Large Language Models (LLMs) has emerged as a promising avenue of research in Dialog State Tracking (DST). However, the best-performing in-context learning methods involve retrieving and adding similar examples to the prompt, requiring access to labeled training data. Procuring such training data for a wide range of domains and applications is time-consuming, expensive, and, at times, infeasible. While zero-shot learning requires no training data, it significantly lags behind the few-shot setup. Thus, `\textit{Can we efficiently generate synthetic data for any dialogue schema to enable few-shot prompting?}' Addressing this question, we propose \method, a data generation framework tailored for DST, utilizing LLMs. Our approach only requires the dialogue schema and a few hand-crafted dialogue templates to synthesize natural, coherent, and free-flowing dialogues with DST annotations. Few-shot learning using data from {\method} results in $4-5%$ improvement in Joint Goal Accuracy over the zero-shot baseline on MultiWOZ 2.1 and 2.4. Remarkably, our few-shot learning approach recovers nearly $98%$ of the performance compared to the few-shot setup using human-annotated training data. Our synthetic data and code can be accessed at https://github.com/apple/ml-synthdst
Can Large Language Models Understand Context?
Feb 01, 2024


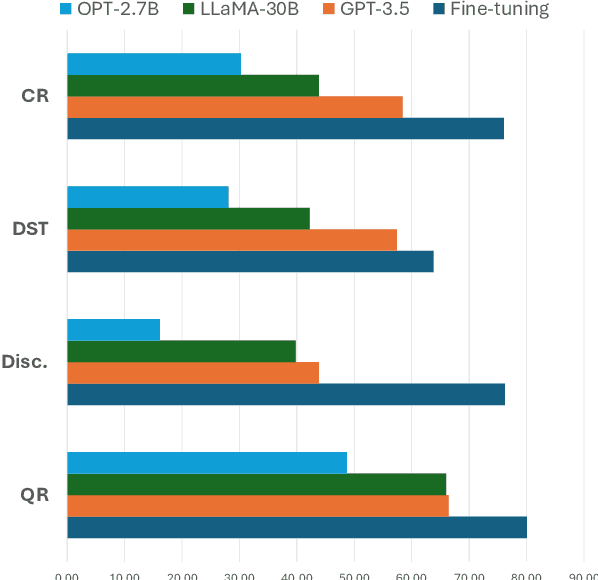
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
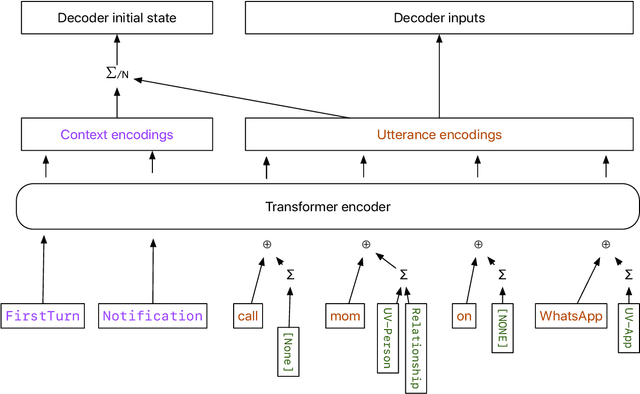
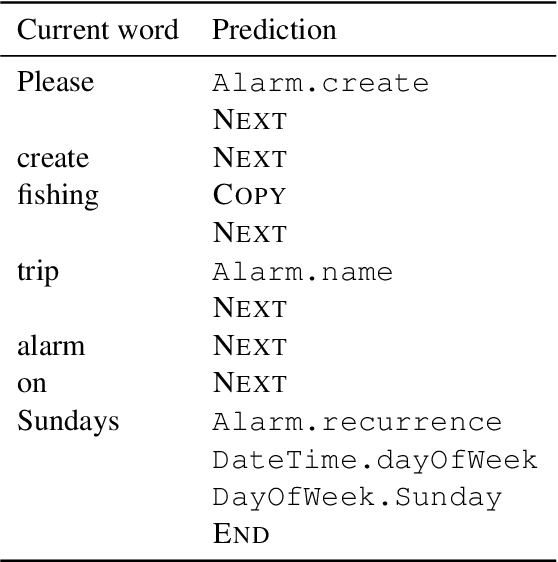

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
Referring to Screen Texts with Voice Assistants
Jun 10, 2023

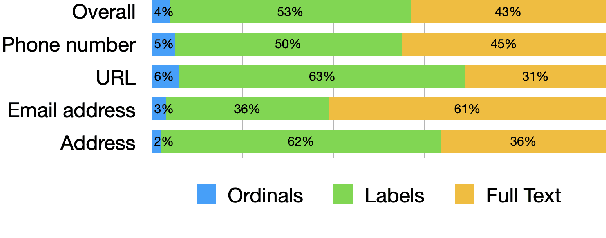

Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users' context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight general-purpose model for this novel experience. Due to the high cost of consuming pixels directly, our system is designed to rely on the extracted text from the UI. Our model is modular, thus offering flexibility, improved interpretability, and efficient runtime memory utilization.
Fairness in AI Systems: Mitigating gender bias from language-vision models
May 03, 2023

Our society is plagued by several biases, including racial biases, caste biases, and gender bias. As a matter of fact, several years ago, most of these notions were unheard of. These biases passed through generations along with amplification have lead to scenarios where these have taken the role of expected norms by certain groups in the society. One notable example is of gender bias. Whether we talk about the political world, lifestyle or corporate world, some generic differences are observed regarding the involvement of both the groups. This differential distribution, being a part of the society at large, exhibits its presence in the recorded data as well. Machine learning is almost entirely dependent on the availability of data; and the idea of learning from data and making predictions assumes that data defines the expected behavior at large. Hence, with biased data the resulting models are corrupted with those inherent biases too; and with the current popularity of ML in products, this can result in a huge obstacle in the path of equality and justice. This work studies and attempts to alleviate gender bias issues from language vision models particularly the task of image captioning. We study the extent of the impact of gender bias in existing datasets and propose a methodology to mitigate its impact in caption based language vision models.
CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues
May 20, 2021
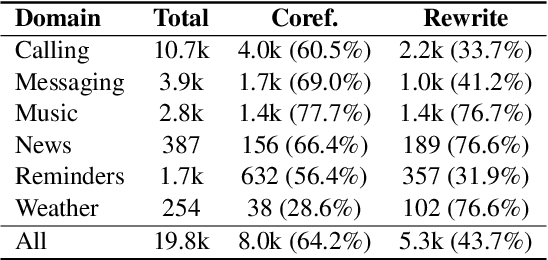

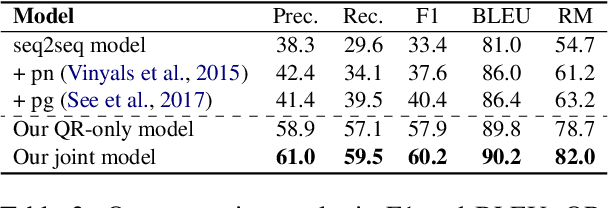
Anaphora and ellipses are two common phenomena in dialogues. Without resolving referring expressions and information omission, dialogue systems may fail to generate consistent and coherent responses. Traditionally, anaphora is resolved by coreference resolution and ellipses by query rewrite. In this work, we propose a novel joint learning framework of modeling coreference resolution and query rewriting for complex, multi-turn dialogue understanding. Given an ongoing dialogue between a user and a dialogue assistant, for the user query, our joint learning model first predicts coreference links between the query and the dialogue context, and then generates a self-contained rewritten user query. To evaluate our model, we annotate a dialogue based coreference resolution dataset, MuDoCo, with rewritten queries. Results show that the performance of query rewrite can be substantially boosted (+2.3% F1) with the aid of coreference modeling. Furthermore, our joint model outperforms the state-of-the-art coreference resolution model (+2% F1) on this dataset.
Conversational Semantic Parsing for Dialog State Tracking
Oct 24, 2020
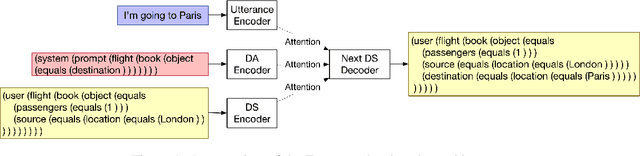

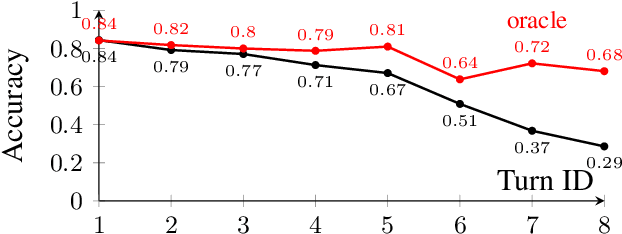
We consider a new perspective on dialog state tracking (DST), the task of estimating a user's goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical representations, we can incorporate semantic compositionality, cross-domain knowledge sharing and co-reference. We present TreeDST, a dataset of 27k conversations annotated with tree-structured dialog states and system acts. We describe an encoder-decoder framework for DST with hierarchical representations, which leads to 20% improvement over state-of-the-art DST approaches that operate on a flat meaning space of slot-value pairs.
Exposing and Correcting the Gender Bias in Image Captioning Datasets and Models
Dec 02, 2019


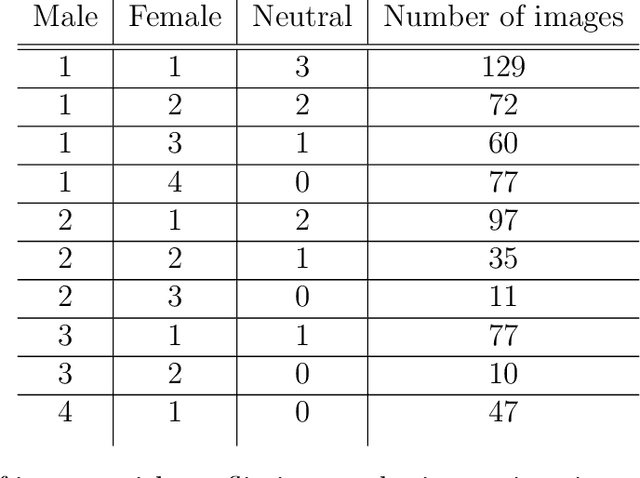
The task of image captioning implicitly involves gender identification. However, due to the gender bias in data, gender identification by an image captioning model suffers. Also, the gender-activity bias, owing to the word-by-word prediction, influences other words in the caption prediction, resulting in the well-known problem of label bias. In this work, we investigate gender bias in the COCO captioning dataset and show that it engenders not only from the statistical distribution of genders with contexts but also from the flawed annotation by the human annotators. We look at the issues created by this bias in the trained models. We propose a technique to get rid of the bias by splitting the task into 2 subtasks: gender-neutral image captioning and gender classification. By this decoupling, the gender-context influence can be eradicated. We train the gender-neutral image captioning model, which gives comparable results to a gendered model even when evaluating against a dataset that possesses a similar bias as the training data. Interestingly, the predictions by this model on images with no humans, are also visibly different from the one trained on gendered captions. We train gender classifiers using the available bounding box and mask-based annotations for the person in the image. This allows us to get rid of the context and focus on the person to predict the gender. By substituting the genders into the gender-neutral captions, we get the final gendered predictions. Our predictions achieve similar performance to a model trained with gender, and at the same time are devoid of gender bias. Finally, our main result is that on an anti-stereotypical dataset, our model outperforms a popular image captioning model which is trained with gender.