 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring to Screen Texts with Voice Assistants
Jun 10, 2023

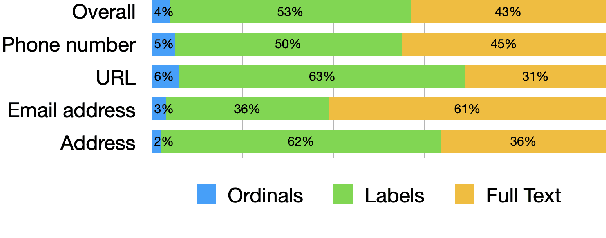

Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users' context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight general-purpose model for this novel experience. Due to the high cost of consuming pixels directly, our system is designed to rely on the extracted text from the UI. Our model is modular, thus offering flexibility, improved interpretability, and efficient runtime memory utilization.
Mirroring to Build Trust in Digital Assistants
Apr 02, 2019

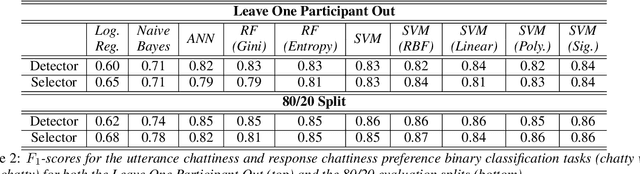
We describe experiments towards building a conversational digital assistant that considers the preferred conversational style of the user. In particular, these experiments are designed to measure whether users prefer and trust an assistant whose conversational style matches their own. To this end we conducted a user study where subjects interacted with a digital assistant that responded in a way that either matched their conversational style, or did not. Using self-reported personality attributes and subjects' feedback on the interactions, we built models that can reliably predict a user's preferred conversational style.