 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring to Screen Texts with Voice Assistants
Jun 10, 2023

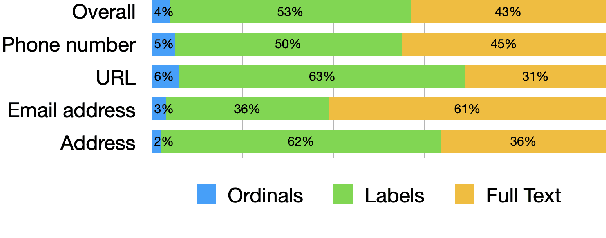

Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users' context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight general-purpose model for this novel experience. Due to the high cost of consuming pixels directly, our system is designed to rely on the extracted text from the UI. Our model is modular, thus offering flexibility, improved interpretability, and efficient runtime memory utilization.
Campfire: Compressible, Regularization-Free, Structured Sparse Training for Hardware Accelerators
Jan 13, 2020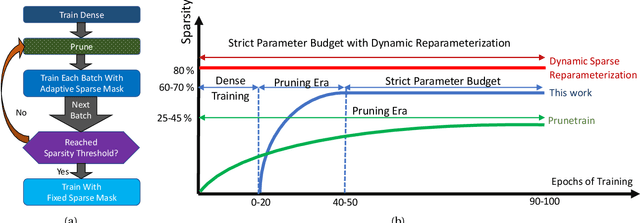
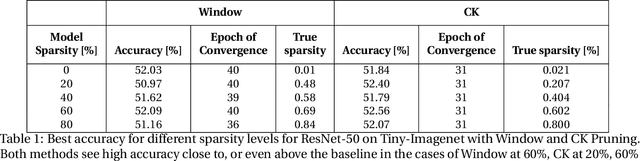
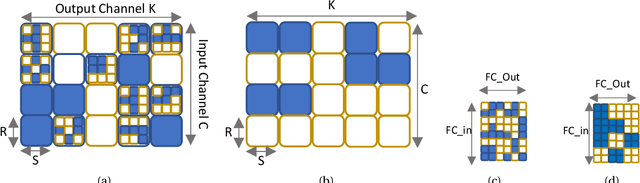
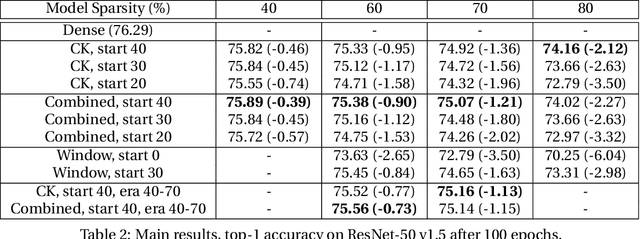
This paper studies structured sparse training of CNNs with a gradual pruning technique that leads to fixed, sparse weight matrices after a set number of epochs. We simplify the structure of the enforced sparsity so that it reduces overhead caused by regularization. The proposed training methodology Campfire explores pruning at granularities within a convolutional kernel and filter. We study various tradeoffs with respect to pruning duration, level of sparsity, and learning rate configuration. We show that our method creates a sparse version of ResNet-50 and ResNet-50 v1.5 on full ImageNet while remaining within a negligible <1% margin of accuracy loss. To ensure that this type of sparse training does not harm the robustness of the network, we also demonstrate how the network behaves in the presence of adversarial attacks. Our results show that with 70% target sparsity, over 75% top-1 accuracy is achievable.