 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-based Language Models: An Efficient, Explainable, and Eco-friendly Approach to Large Language Modeling
Oct 25, 2025We present memory-based language modeling as an efficient, eco-friendly alternative to deep neural network-based language modeling. It offers log-linearly scalable next-token prediction performance and strong memorization capabilities. Implementing fast approximations of k-nearest neighbor classification, memory-based language modeling leaves a relatively small ecological footprint both in training and in inference mode, as it relies fully on CPUs and attains low token latencies. Its internal workings are simple and fully transparent. We compare our implementation of memory-based language modeling, OLIFANT, with GPT-2 and GPT-Neo on next-token prediction accuracy, estimated emissions and speeds, and offer some deeper analyses of the model.
Improving the Inclusivity of Dutch Speech Recognition by Fine-tuning Whisper on the JASMIN-CGN Corpus
Feb 24, 2025

We test and study the variation in speech recognition of fine-tuned versions of the Whisper model on child, elderly and non-native Dutch speech from the JASMIN-CGN corpus. Our primary goal is to evaluate how speakers' age and linguistic background influence Whisper's performance. Whisper achieves varying Word Error Rates (WER) when fine-tuned on subpopulations of specific ages and linguistic backgrounds. Fine-tuned performance is remarkably better than zero-shot performance, achieving a relative reduction in WER of 81% for native children, 72% for non-native children, 67% for non-native adults, and 65% for native elderly people. Our findings underscore the importance of training speech recognition models like Whisper on underrepresented subpopulations such as children, the elderly, and non-native speakers.
The Impact of Featuring Comments in Online Discussions
Dec 03, 2024A widespread moderation strategy by online news platforms is to feature what the platform deems high quality comments, usually called editor picks or featured comments. In this paper, we compare online discussions of news articles in which certain comments are featured, versus discussions in which no comments are featured. We measure the impact of featuring comments on the discussion, by estimating and comparing the quality of discussions from the perspective of the user base and the platform itself. Our analysis shows that the impact on discussion quality is limited. However, we do observe an increase in discussion activity after the first comments are featured by moderators, suggesting that the moderation strategy might be used to increase user engagement and to postpone the natural decline in user activity over time.
Hybrid moderation in the newsroom: Recommending featured posts to content moderators
Jul 14, 2023Online news outlets are grappling with the moderation of user-generated content within their comment section. We present a recommender system based on ranking class probabilities to support and empower the moderator in choosing featured posts, a time-consuming task. By combining user and textual content features we obtain an optimal classification F1-score of 0.44 on the test set. Furthermore, we observe an optimum mean NDCG@5 of 0.87 on a large set of validation articles. As an expert evaluation, content moderators assessed the output of a random selection of articles by choosing comments to feature based on the recommendations, which resulted in a NDCG score of 0.83. We conclude that first, adding text features yields the best score and second, while choosing featured content remains somewhat subjective, content moderators found suitable comments in all but one evaluated recommendations. We end the paper by analyzing our best-performing model, a step towards transparency and explainability in hybrid content moderation.
Monitoring stance towards vaccination in Twitter messages
Sep 01, 2019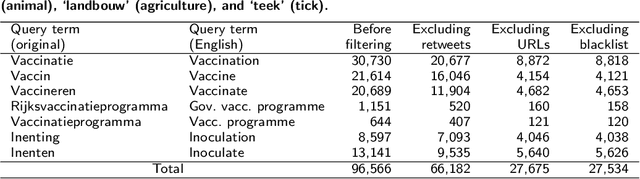
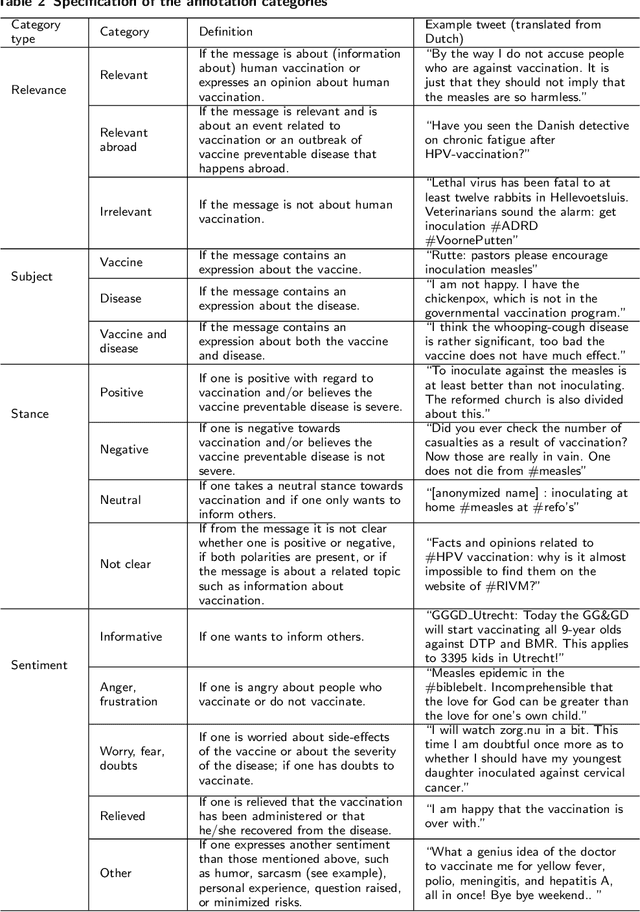

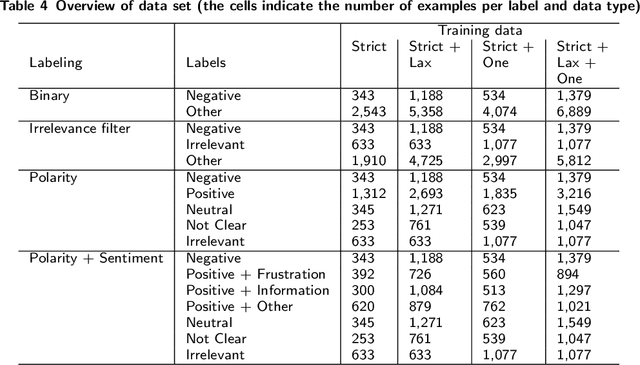
We developed a system to automatically classify stance towards vaccination in Twitter messages, with a focus on messages with a negative stance. Such a system makes it possible to monitor the ongoing stream of messages on social media, offering actionable insights into public hesitance with respect to vaccination. For Dutch Twitter messages that mention vaccination-related key terms, we annotated their stance and feeling in relation to vaccination (provided that they referred to this topic). Subsequently, we used these coded data to train and test different machine learning set-ups. With the aim to best identify messages with a negative stance towards vaccination, we compared set-ups at an increasing dataset size and decreasing reliability, at an increasing number of categories to distinguish, and with different classification algorithms. We found that Support Vector Machines trained on a combination of strictly and laxly labeled data with a more fine-grained labeling yielded the best result, at an F1-score of 0.36 and an Area under the ROC curve of 0.66, outperforming a rule-based sentiment analysis baseline that yielded an F1-score of 0.25 and an Area under the ROC curve of 0.57. The outcomes of our study indicate that stance prediction by a computerized system only is a challenging task. Our analysis of the data and behavior of our system suggests that an approach is needed in which the use of a larger training dataset is combined with a setting in which a human-in-the-loop provides the system with feedback on its predictions.
Unraveling reported dreams with text analytics
Dec 12, 2016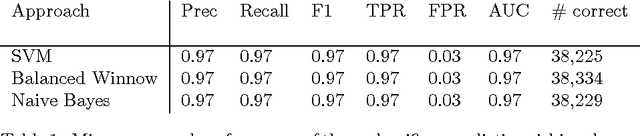
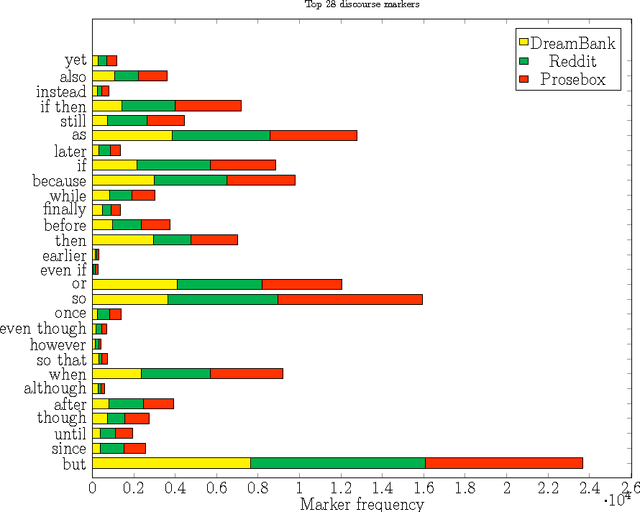

We investigate what distinguishes reported dreams from other personal narratives. The continuity hypothesis, stemming from psychological dream analysis work, states that most dreams refer to a person's daily life and personal concerns, similar to other personal narratives such as diary entries. Differences between the two texts may reveal the linguistic markers of dream text, which could be the basis for new dream analysis work and for the automatic detection of dream descriptions. We used three text analytics methods: text classification, topic modeling, and text coherence analysis, and applied these methods to a balanced set of texts representing dreams, diary entries, and other personal stories. We observed that dream texts could be distinguished from other personal narratives nearly perfectly, mostly based on the presence of uncertainty markers and descriptions of scenes. Important markers for non-dream narratives are specific time expressions and conversational expressions. Dream texts also exhibit a lower discourse coherence than other personal narratives.
Forgetting Exceptions is Harmful in Language Learning
Dec 22, 1998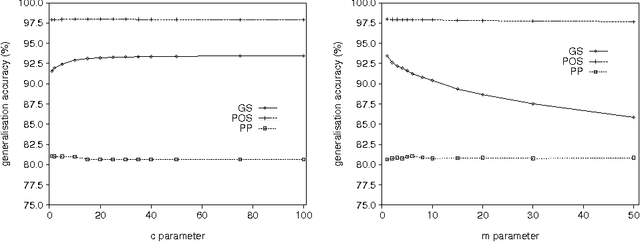
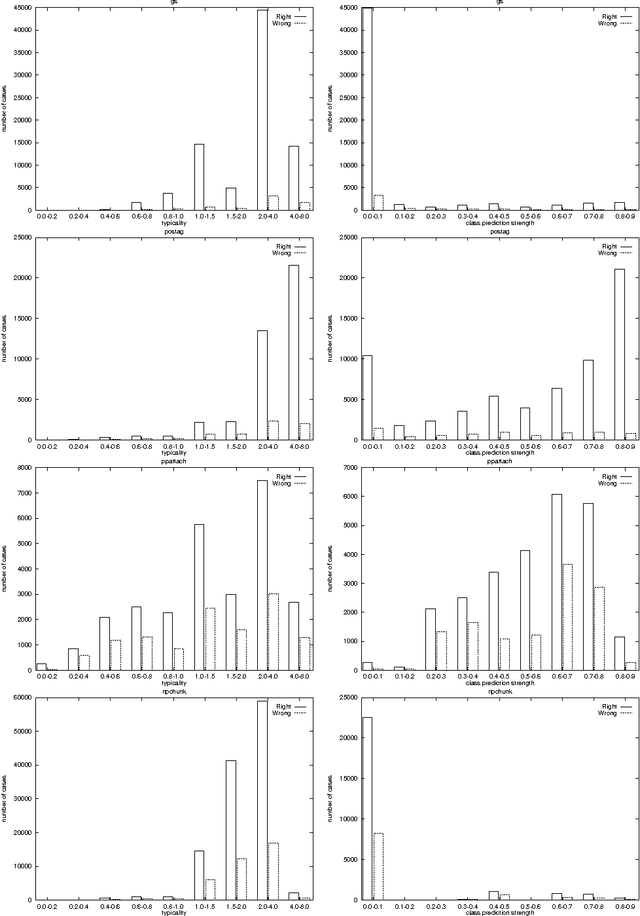
We show that in language learning, contrary to received wisdom, keeping exceptional training instances in memory can be beneficial for generalization accuracy. We investigate this phenomenon empirically on a selection of benchmark natural language processing tasks: grapheme-to-phoneme conversion, part-of-speech tagging, prepositional-phrase attachment, and base noun phrase chunking. In a first series of experiments we combine memory-based learning with training set editing techniques, in which instances are edited based on their typicality and class prediction strength. Results show that editing exceptional instances (with low typicality or low class prediction strength) tends to harm generalization accuracy. In a second series of experiments we compare memory-based learning and decision-tree learning methods on the same selection of tasks, and find that decision-tree learning often performs worse than memory-based learning. Moreover, the decrease in performance can be linked to the degree of abstraction from exceptions (i.e., pruning or eagerness). We provide explanations for both results in terms of the properties of the natural language processing tasks and the learning algorithms.
Modularity in inductively-learned word pronunciation systems
Jan 26, 1998In leading morpho-phonological theories and state-of-the-art text-to-speech systems it is assumed that word pronunciation cannot be learned or performed without in-between analyses at several abstraction levels (e.g., morphological, graphemic, phonemic, syllabic, and stress levels). We challenge this assumption for the case of English word pronunciation. Using IGTree, an inductive-learning decision-tree algorithms, we train and test three word-pronunciation systems in which the number of abstraction levels (implemented as sequenced modules) is reduced from five, via three, to one. The latter system, classifying letter strings directly as mapping to phonemes with stress markers, yields significantly better generalisation accuracies than the two multi-module systems. Analyses of empirical results indicate that positive utility effects of sequencing modules are outweighed by cascading errors passed on between modules.
* 10 pages, uses nemlap3.sty and epsf and ipamacs (WSU IPA) macros
Do not forget: Full memory in memory-based learning of word pronunciation
Jan 26, 1998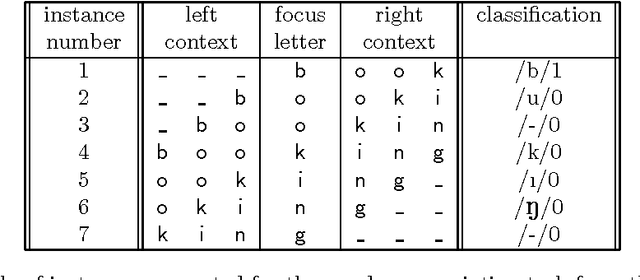
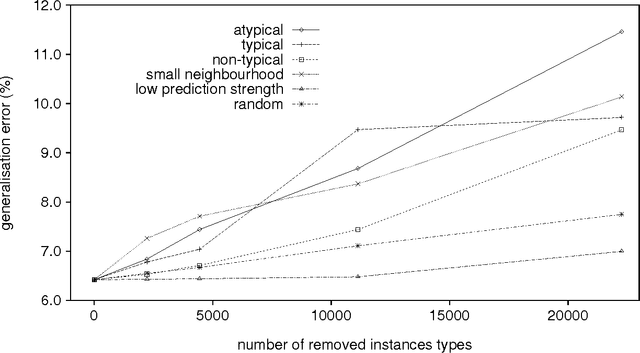


Memory-based learning, keeping full memory of learning material, appears a viable approach to learning NLP tasks, and is often superior in generalisation accuracy to eager learning approaches that abstract from learning material. Here we investigate three partial memory-based learning approaches which remove from memory specific task instance types estimated to be exceptional. The three approaches each implement one heuristic function for estimating exceptionality of instance types: (i) typicality, (ii) class prediction strength, and (iii) friendly-neighbourhood size. Experiments are performed with the memory-based learning algorithm IB1-IG trained on English word pronunciation. We find that removing instance types with low prediction strength (ii) is the only tested method which does not seriously harm generalisation accuracy. We conclude that keeping full memory of types rather than tokens, and excluding minority ambiguities appear to be the only performance-preserving optimisations of memory-based learning.
* uses conll98, epsf, and ipamacs (WSU IPA)
Morphological Analysis as Classification: an Inductive-Learning Approach
Jul 16, 1996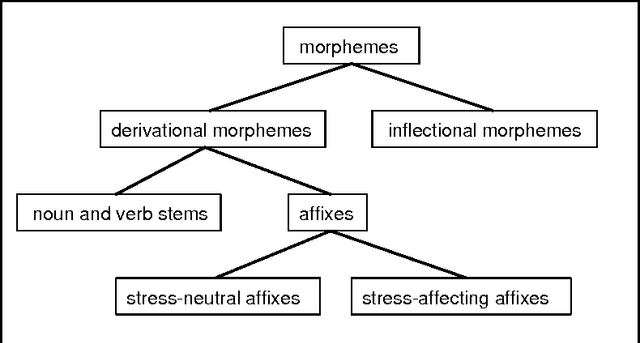
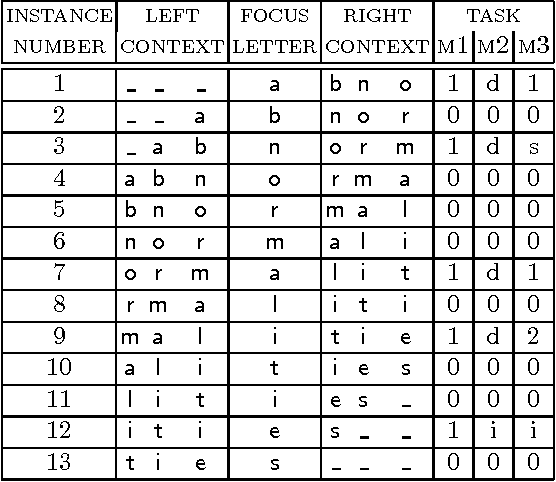
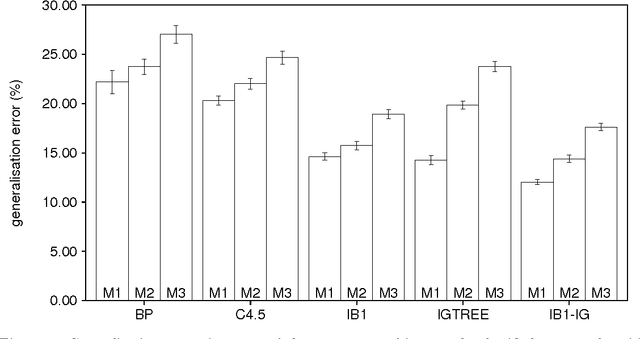
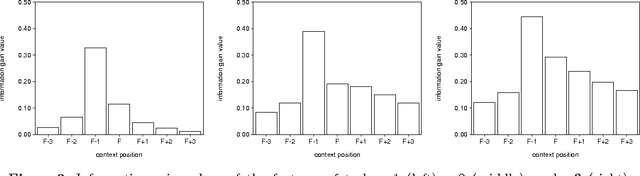
Morphological analysis is an important subtask in text-to-speech conversion, hyphenation, and other language engineering tasks. The traditional approach to performing morphological analysis is to combine a morpheme lexicon, sets of (linguistic) rules, and heuristics to find a most probable analysis. In contrast we present an inductive learning approach in which morphological analysis is reformulated as a segmentation task. We report on a number of experiments in which five inductive learning algorithms are applied to three variations of the task of morphological analysis. Results show (i) that the generalisation performance of the algorithms is good, and (ii) that the lazy learning algorithm IB1-IG performs best on all three tasks. We conclude that lazy learning of morphological analysis as a classification task is indeed a viable approach; moreover, it has the strong advantages over the traditional approach of avoiding the knowledge-acquisition bottleneck, being fast and deterministic in learning and processing, and being language-independent.
* 11 pages, 5 encapsulated postscript figures, uses non-standard NeMLaP proceedings style nemlap.sty; inputs ipamacs (international phonetic alphabet) and epsf macros