 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo not forget: Full memory in memory-based learning of word pronunciation
Paper and Code
Jan 26, 1998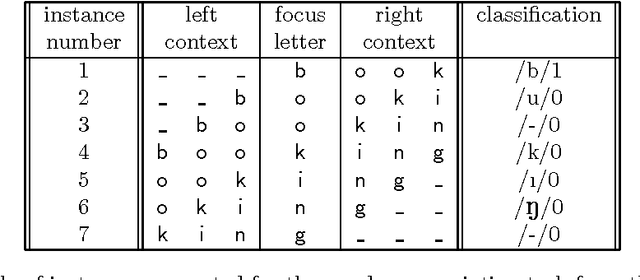
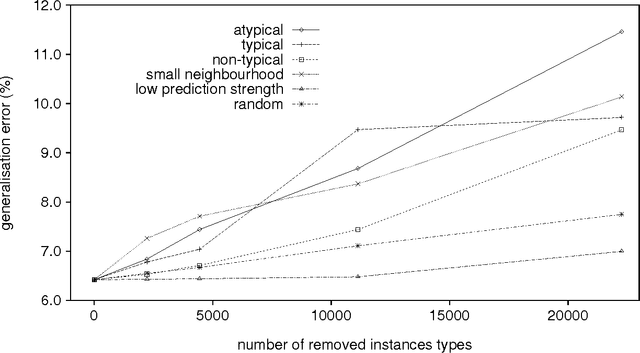


Memory-based learning, keeping full memory of learning material, appears a viable approach to learning NLP tasks, and is often superior in generalisation accuracy to eager learning approaches that abstract from learning material. Here we investigate three partial memory-based learning approaches which remove from memory specific task instance types estimated to be exceptional. The three approaches each implement one heuristic function for estimating exceptionality of instance types: (i) typicality, (ii) class prediction strength, and (iii) friendly-neighbourhood size. Experiments are performed with the memory-based learning algorithm IB1-IG trained on English word pronunciation. We find that removing instance types with low prediction strength (ii) is the only tested method which does not seriously harm generalisation accuracy. We conclude that keeping full memory of types rather than tokens, and excluding minority ambiguities appear to be the only performance-preserving optimisations of memory-based learning.