 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Approach to Topic Modelling
Jul 25, 2024

Topic modelling has become increasingly popular for summarizing text data, such as social media posts and articles. However, topic modelling is usually completed in one shot. Assessing the quality of resulting topics is challenging. No effective methods or measures have been developed for assessing the results or for making further enhancements to the topics. In this research, we propose we propose to use an iterative process to perform topic modelling that gives rise to a sense of completeness of the resulting topics when the process is complete. Using the BERTopic package, a popular method in topic modelling, we demonstrate how the modelling process can be applied iteratively to arrive at a set of topics that could not be further improved upon using one of the three selected measures for clustering comparison as the decision criteria. This demonstration is conducted using a subset of the COVIDSenti-A dataset. The early success leads us to believe that further research using in using this approach in conjunction with other topic modelling algorithms could be viable.
Translating Natural Language Queries to SQL Using the T5 Model
Dec 12, 2023This paper presents the development process of a natural language to SQL model using the T5 model as the basis. The models, developed in August 2022 for an online transaction processing system and a data warehouse, have a 73\% and 84\% exact match accuracy respectively. These models, in conjunction with other work completed in the research project, were implemented for several companies and used successfully on a daily basis. The approach used in the model development could be implemented in a similar fashion for other database environments and with a more powerful pre-trained language model.
Monitoring stance towards vaccination in Twitter messages
Sep 01, 2019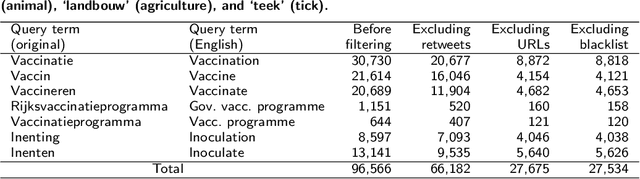
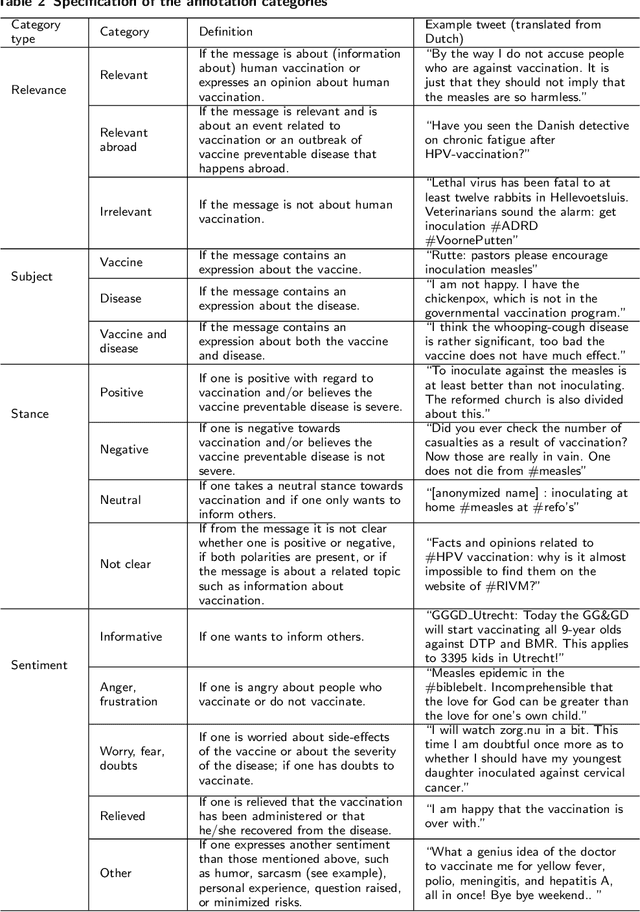

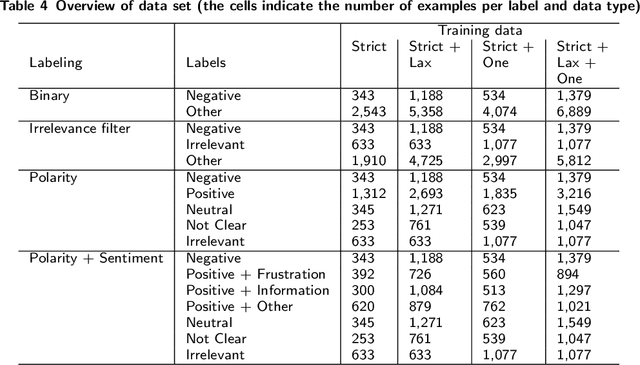
We developed a system to automatically classify stance towards vaccination in Twitter messages, with a focus on messages with a negative stance. Such a system makes it possible to monitor the ongoing stream of messages on social media, offering actionable insights into public hesitance with respect to vaccination. For Dutch Twitter messages that mention vaccination-related key terms, we annotated their stance and feeling in relation to vaccination (provided that they referred to this topic). Subsequently, we used these coded data to train and test different machine learning set-ups. With the aim to best identify messages with a negative stance towards vaccination, we compared set-ups at an increasing dataset size and decreasing reliability, at an increasing number of categories to distinguish, and with different classification algorithms. We found that Support Vector Machines trained on a combination of strictly and laxly labeled data with a more fine-grained labeling yielded the best result, at an F1-score of 0.36 and an Area under the ROC curve of 0.66, outperforming a rule-based sentiment analysis baseline that yielded an F1-score of 0.25 and an Area under the ROC curve of 0.57. The outcomes of our study indicate that stance prediction by a computerized system only is a challenging task. Our analysis of the data and behavior of our system suggests that an approach is needed in which the use of a larger training dataset is combined with a setting in which a human-in-the-loop provides the system with feedback on its predictions.