 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRK-BERT: The Supreme Language Model
Dec 01, 2021
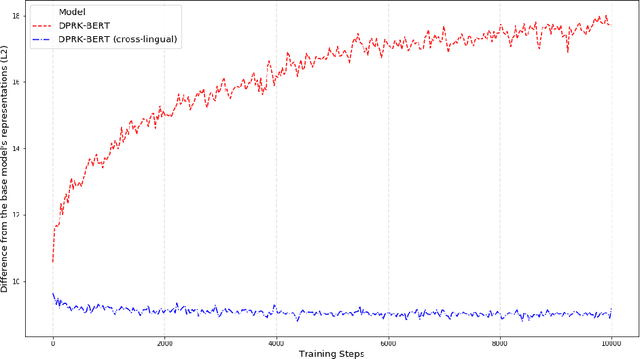
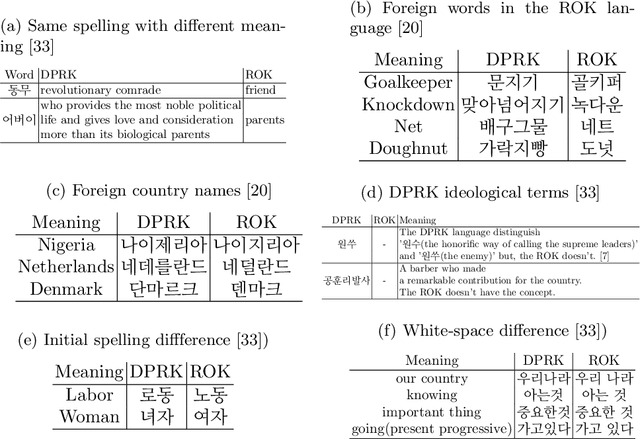
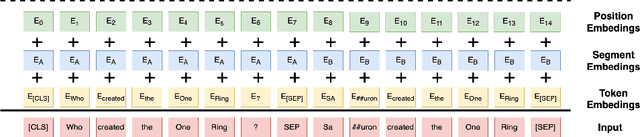
Deep language models have achieved remarkable success in the NLP domain. The standard way to train a deep language model is to employ unsupervised learning from scratch on a large unlabeled corpus. However, such large corpora are only available for widely-adopted and high-resource languages and domains. This study presents the first deep language model, DPRK-BERT, for the DPRK language. We achieve this by compiling the first unlabeled corpus for the DPRK language and fine-tuning a preexisting the ROK language model. We compare the proposed model with existing approaches and show significant improvements on two DPRK datasets. We also present a cross-lingual version of this model which yields better generalization across the two Korean languages. Finally, we provide various NLP tools related to the DPRK language that would foster future research.
Analyzing the Effect of Multi-task Learning for Biomedical Named Entity Recognition
Nov 01, 2020



Developing high-performing systems for detecting biomedical named entities has major implications. State-of-the-art deep-learning based solutions for entity recognition often require large annotated datasets, which is not available in the biomedical domain. Transfer learning and multi-task learning have been shown to improve performance for low-resource domains. However, the applications of these methods are relatively scarce in the biomedical domain, and a theoretical understanding of why these methods improve the performance is lacking. In this study, we performed an extensive analysis to understand the transferability between different biomedical entity datasets. We found useful measures to predict transferability between these datasets. Besides, we propose combining transfer learning and multi-task learning to improve the performance of biomedical named entity recognition systems, which is not applied before to the best of our knowledge.
Overview of CLEF 2019 Lab ProtestNews: Extracting Protests from News in a Cross-context Setting
Aug 01, 2020


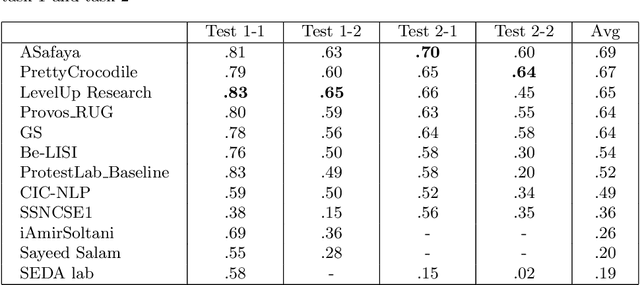
We present an overview of the CLEF-2019 Lab ProtestNews on Extracting Protests from News in the context of generalizable natural language processing. The lab consists of document, sentence, and token level information classification and extraction tasks that were referred as task 1, task 2, and task 3 respectively in the scope of this lab. The tasks required the participants to identify protest relevant information from English local news at one or more aforementioned levels in a cross-context setting, which is cross-country in the scope of this lab. The training and development data were collected from India and test data was collected from India and China. The lab attracted 58 teams to participate in the lab. 12 and 9 of these teams submitted results and working notes respectively. We have observed neural networks yield the best results and the performance drops significantly for majority of the submissions in the cross-country setting, which is China.
Hierarchical Multi Task Learning with Subword Contextual Embeddings for Languages with Rich Morphology
Apr 25, 2020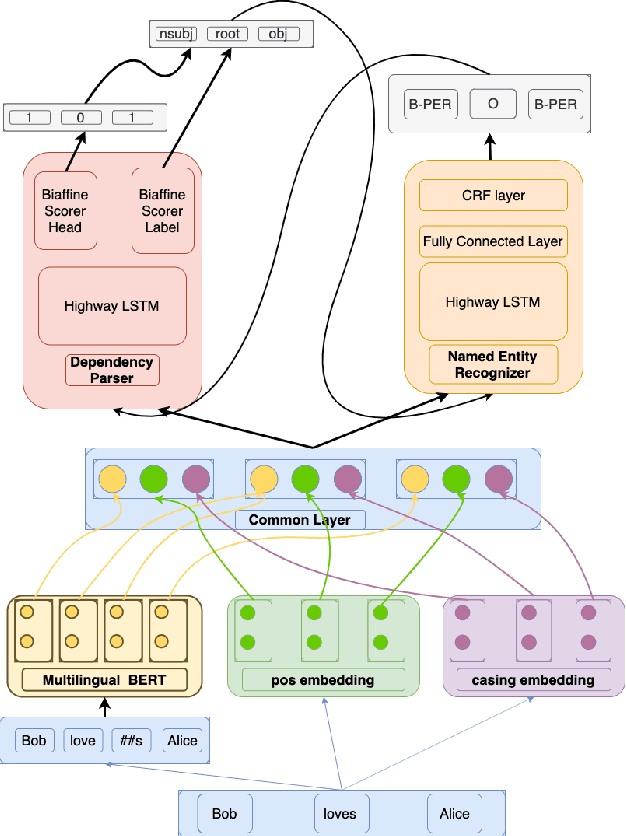

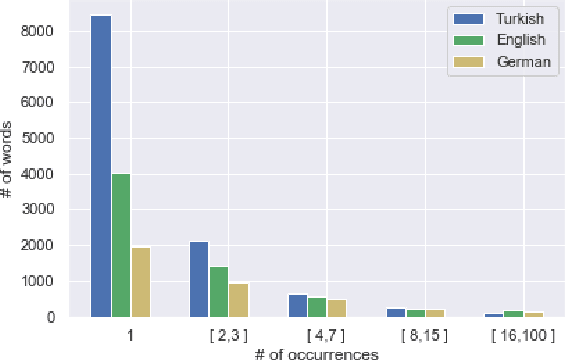
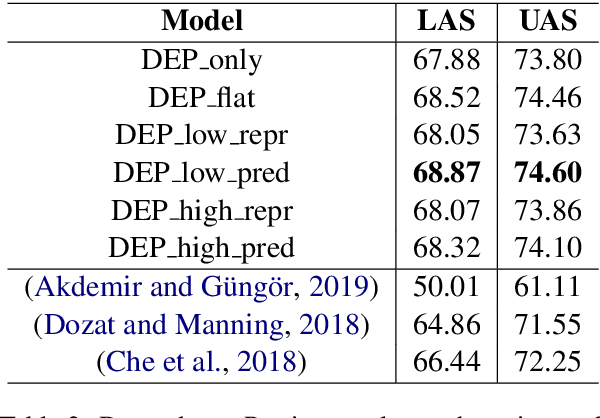
Morphological information is important for many sequence labeling tasks in Natural Language Processing (NLP). Yet, existing approaches rely heavily on manual annotations or external software to capture this information. In this study, we propose using subword contextual embeddings to capture the morphological information for languages with rich morphology. In addition, we incorporate these embeddings in a hierarchical multi-task setting which is not employed before, to the best of our knowledge. Evaluated on Dependency Parsing (DEP) and Named Entity Recognition (NER) tasks, which are shown to benefit greatly from morphological information, our final model outperforms previous state-of-the-art models on both tasks for the Turkish language. Besides, we show a net improvement of 18.86% and 4.61% F-1 over the previously proposed multi-task learner in the same setting for the DEP and the NER tasks, respectively. Empirical results for five different MTL settings show that incorporating subword contextual embeddings brings significant improvements for both tasks. In addition, we observed that multi-task learning consistently improves the performance of the DEP component.