 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRK-BERT: The Supreme Language Model
Dec 01, 2021
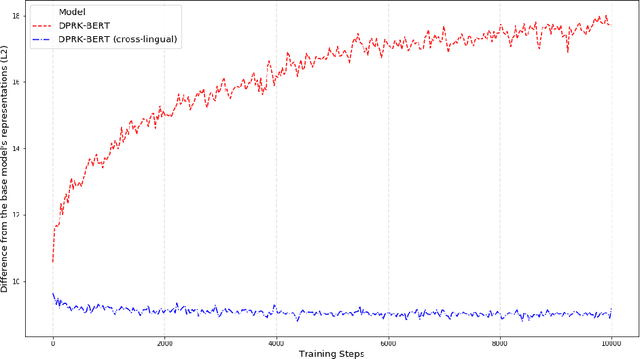
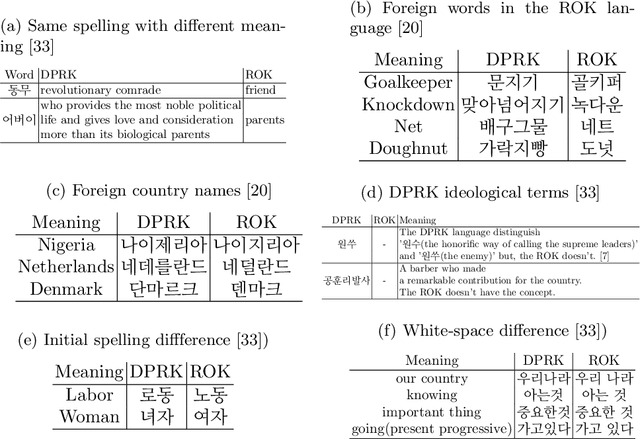
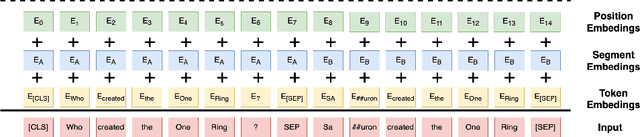
Deep language models have achieved remarkable success in the NLP domain. The standard way to train a deep language model is to employ unsupervised learning from scratch on a large unlabeled corpus. However, such large corpora are only available for widely-adopted and high-resource languages and domains. This study presents the first deep language model, DPRK-BERT, for the DPRK language. We achieve this by compiling the first unlabeled corpus for the DPRK language and fine-tuning a preexisting the ROK language model. We compare the proposed model with existing approaches and show significant improvements on two DPRK datasets. We also present a cross-lingual version of this model which yields better generalization across the two Korean languages. Finally, we provide various NLP tools related to the DPRK language that would foster future research.