 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Aspect Extraction Framework using Different Embedding Types, Learning Models, and Dependency Structure
Mar 05, 2025Aspect-based sentiment analysis has gained significant attention in recent years due to its ability to provide fine-grained insights for sentiment expressions related to specific features of entities. An important component of aspect-based sentiment analysis is aspect extraction, which involves identifying and extracting aspect terms from text. Effective aspect extraction serves as the foundation for accurate sentiment analysis at the aspect level. In this paper, we propose aspect extraction models that use different types of embeddings for words and part-of-speech tags and that combine several learning models. We also propose tree positional encoding that is based on dependency parsing output to capture better the aspect positions in sentences. In addition, a new aspect extraction dataset is built for Turkish by machine translating an English dataset in a controlled setting. The experiments conducted on two Turkish datasets showed that the proposed models mostly outperform the studies that use the same datasets, and incorporating tree positional encoding increases the performance of the models.
A Comprehensive Analysis of Static Word Embeddings for Turkish
May 13, 2024



Word embeddings are fixed-length, dense and distributed word representations that are used in natural language processing (NLP) applications. There are basically two types of word embedding models which are non-contextual (static) models and contextual models. The former method generates a single embedding for a word regardless of its context, while the latter method produces distinct embeddings for a word based on the specific contexts in which it appears. There are plenty of works that compare contextual and non-contextual embedding models within their respective groups in different languages. However, the number of studies that compare the models in these two groups with each other is very few and there is no such study in Turkish. This process necessitates converting contextual embeddings into static embeddings. In this paper, we compare and evaluate the performance of several contextual and non-contextual models in both intrinsic and extrinsic evaluation settings for Turkish. We make a fine-grained comparison by analyzing the syntactic and semantic capabilities of the models separately. The results of the analyses provide insights about the suitability of different embedding models in different types of NLP tasks. We also build a Turkish word embedding repository comprising the embedding models used in this work, which may serve as a valuable resource for researchers and practitioners in the field of Turkish NLP. We make the word embeddings, scripts, and evaluation datasets publicly available.
Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Jan 07, 2024

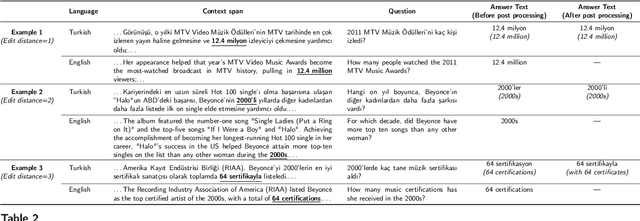

Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource languages. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA for Turkish. We obtain a performance improvement of 9-34% in the EM score and 13-33% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models by using two versions of Wikipedia dumps spanning two years. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available.
Incorporating Human Translator Style into English-Turkish Literary Machine Translation
Jul 21, 2023



Although machine translation systems are mostly designed to serve in the general domain, there is a growing tendency to adapt these systems to other domains like literary translation. In this paper, we focus on English-Turkish literary translation and develop machine translation models that take into account the stylistic features of translators. We fine-tune a pre-trained machine translation model by the manually-aligned works of a particular translator. We make a detailed analysis of the effects of manual and automatic alignments, data augmentation methods, and corpus size on the translations. We propose an approach based on stylistic features to evaluate the style of a translator in the output translations. We show that the human translator style can be highly recreated in the target machine translations by adapting the models to the style of the translator.
Enhancements to the BOUN Treebank Reflecting the Agglutinative Nature of Turkish
Jul 24, 2022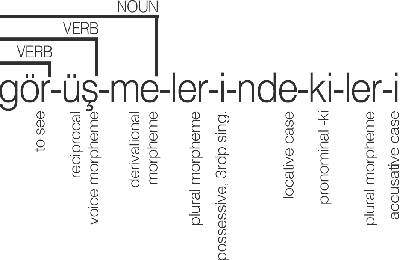
In this study, we aim to offer linguistically motivated solutions to resolve the issues of the lack of representation of null morphemes, highly productive derivational processes, and syncretic morphemes of Turkish in the BOUN Treebank without diverging from the Universal Dependencies framework. In order to tackle these issues, new annotation conventions were introduced by splitting certain lemmas and employing the MISC (miscellaneous) tab in the UD framework to denote derivation. Representational capabilities of the re-annotated treebank were tested on a LSTM-based dependency parser and an updated version of the BoAT Tool is introduced.
Hierarchical Multitask Learning Approach for BERT
Oct 17, 2020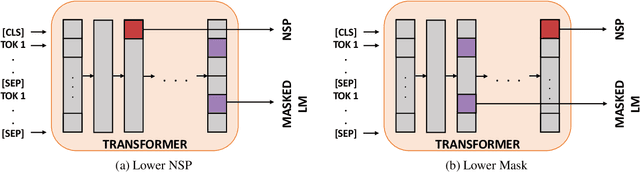
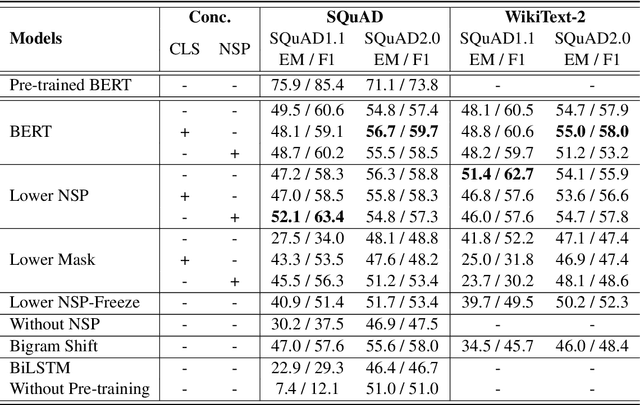
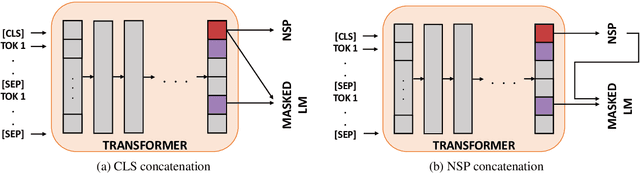
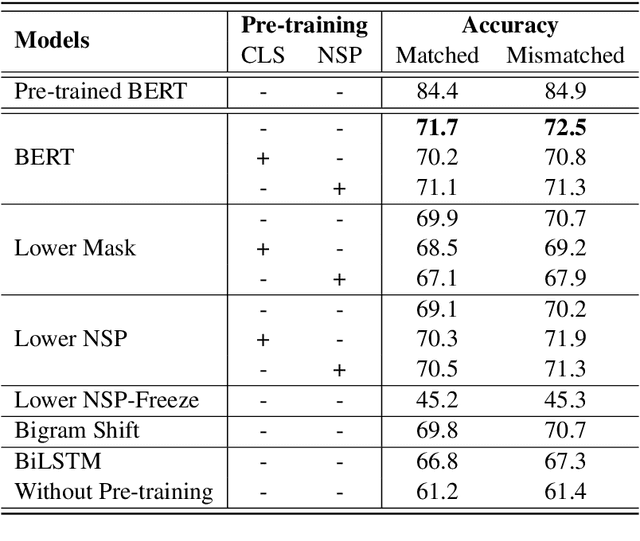
Recent works show that learning contextualized embeddings for words is beneficial for downstream tasks. BERT is one successful example of this approach. It learns embeddings by solving two tasks, which are masked language model (masked LM) and the next sentence prediction (NSP). The pre-training of BERT can also be framed as a multitask learning problem. In this work, we adopt hierarchical multitask learning approaches for BERT pre-training. Pre-training tasks are solved at different layers instead of the last layer, and information from the NSP task is transferred to the masked LM task. Also, we propose a new pre-training task bigram shift to encode word order information. We choose two downstream tasks, one of which requires sentence-level embeddings (textual entailment), and the other requires contextualized embeddings of words (question answering). Due to computational restrictions, we use the downstream task data instead of a large dataset for the pre-training to see the performance of proposed models when given a restricted dataset. We test their performance on several probing tasks to analyze learned embeddings. Our results show that imposing a task hierarchy in pre-training improves the performance of embeddings.
Use of Machine Translation to Obtain Labeled Datasets for Resource-Constrained Languages
May 01, 2020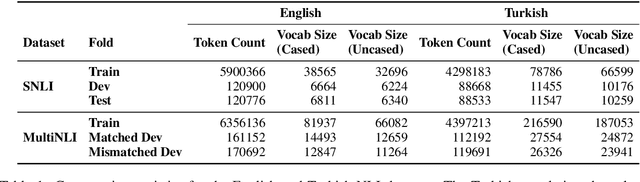
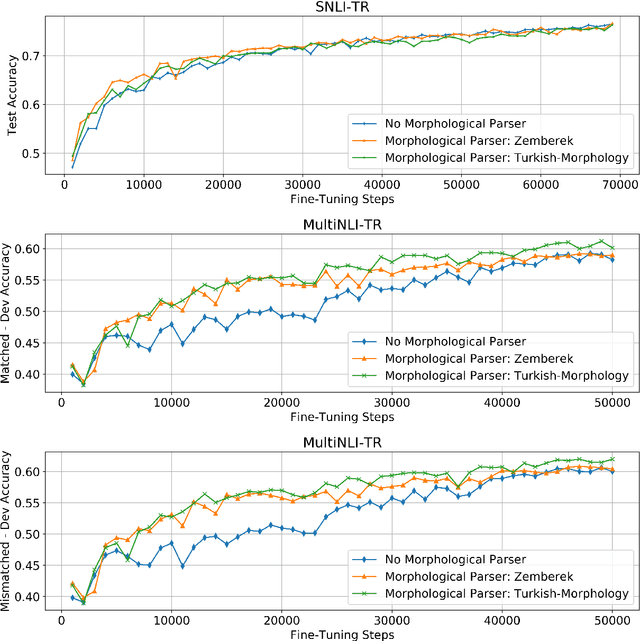
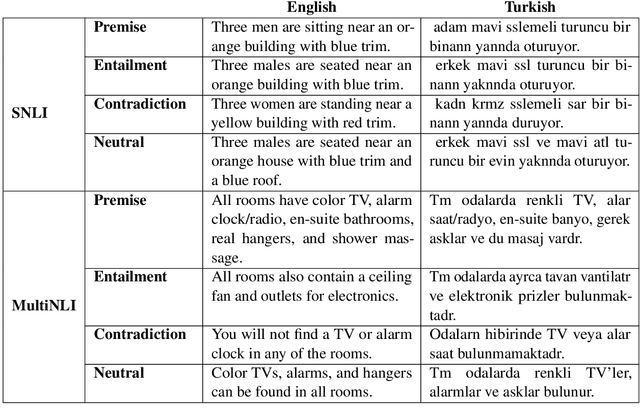
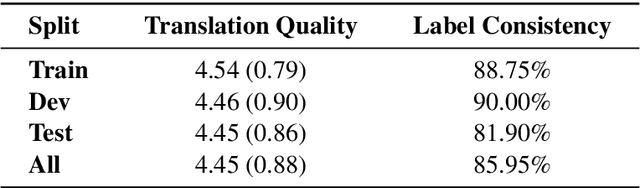
The large annotated datasets in NLP are overwhelmingly in English. This is an obstacle to progress for other languages. Unfortunately, obtaining new annotated resources for each task in each language would be prohibitively expensive. At the same time, commercial machine translation systems are now robust. Can we leverage these systems to translate English-language datasets automatically? In this paper, we offer a positive response to this for natural language inference (NLI) in Turkish. We translated two large English NLI datasets into Turkish and had a team of experts validate their quality. As examples of the new issues that these datasets help us address, we assess the value of Turkish-specific embeddings and the importance of morphological parsing for developing robust Turkish NLI models.
Hierarchical Multi Task Learning with Subword Contextual Embeddings for Languages with Rich Morphology
Apr 25, 2020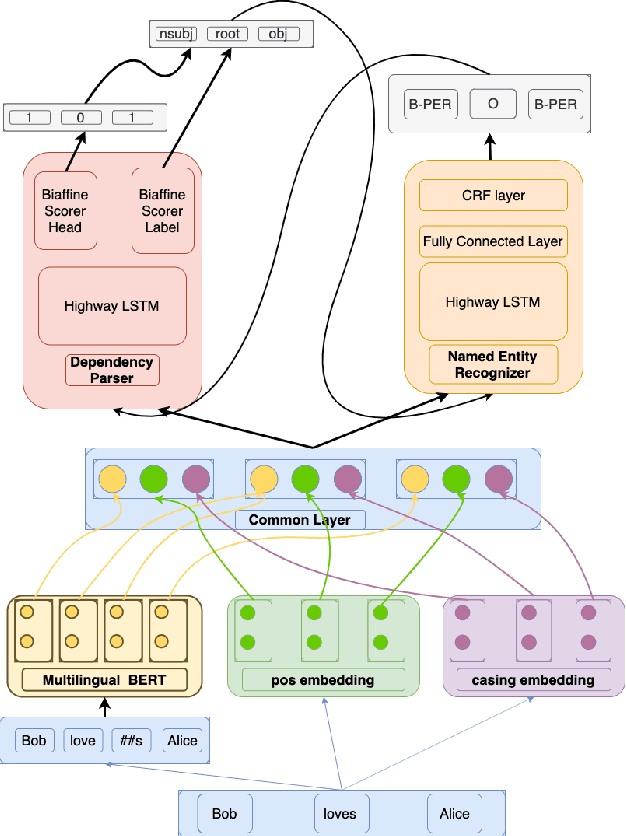

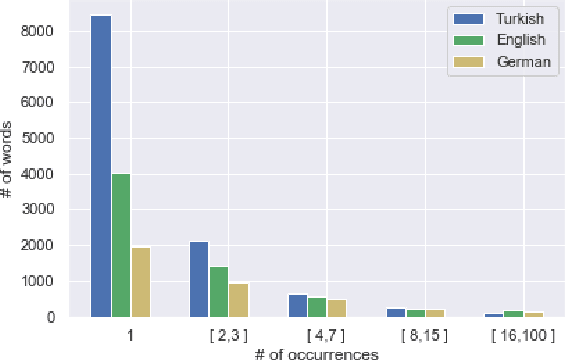
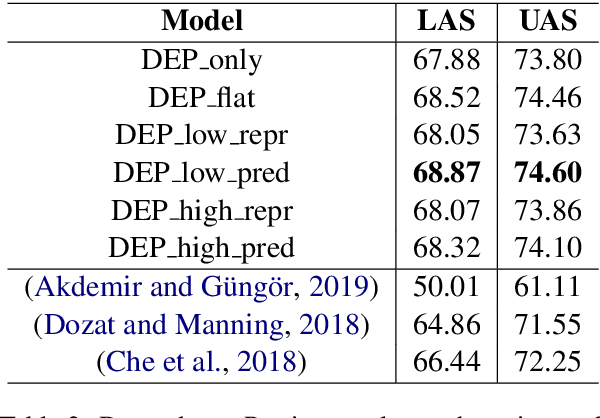
Morphological information is important for many sequence labeling tasks in Natural Language Processing (NLP). Yet, existing approaches rely heavily on manual annotations or external software to capture this information. In this study, we propose using subword contextual embeddings to capture the morphological information for languages with rich morphology. In addition, we incorporate these embeddings in a hierarchical multi-task setting which is not employed before, to the best of our knowledge. Evaluated on Dependency Parsing (DEP) and Named Entity Recognition (NER) tasks, which are shown to benefit greatly from morphological information, our final model outperforms previous state-of-the-art models on both tasks for the Turkish language. Besides, we show a net improvement of 18.86% and 4.61% F-1 over the previously proposed multi-task learner in the same setting for the DEP and the NER tasks, respectively. Empirical results for five different MTL settings show that incorporating subword contextual embeddings brings significant improvements for both tasks. In addition, we observed that multi-task learning consistently improves the performance of the DEP component.
Resources for Turkish Dependency Parsing: Introducing the BOUN Treebank and the BoAT Annotation Tool
Feb 24, 2020


In this paper, we describe our contributions and efforts to develop Turkish resources, which include a new treebank (BOUN Treebank) with novel sentences, along with the guidelines we adopted and a new annotation tool we developed (BoAT). The manual annotation process we employed was shaped and implemented by a team of four linguists and five NLP specialists. Decisions regarding the annotation of the BOUN Treebank were made in line with the Universal Dependencies framework, which originated from the works of De Marneffe et al. (2014) and Nivre et al. (2016). We took into account the recent unifying efforts based on the re-annotation of other Turkish treebanks in the UD framework (T\"urk et al., 2019). Through the BOUN Treebank, we introduced a total of 9,757 sentences from various topics including biographical texts, national newspapers, instructional texts, popular culture articles, and essays. In addition, we report the parsing results of a graph-based dependency parser obtained over each text type, the total of the BOUN Treebank, and all Turkish treebanks that we either re-annotated or introduced. We show that a state-of-the-art dependency parser has improved scores for identifying the proper head and the syntactic relationships between the heads and the dependents. In light of these results, we have observed that the unification of the Turkish annotation scheme and introducing a more comprehensive treebank improves performance with regards to dependency parsing
A Hybrid Approach to Dependency Parsing: Combining Rules and Morphology with Deep Learning
Feb 24, 2020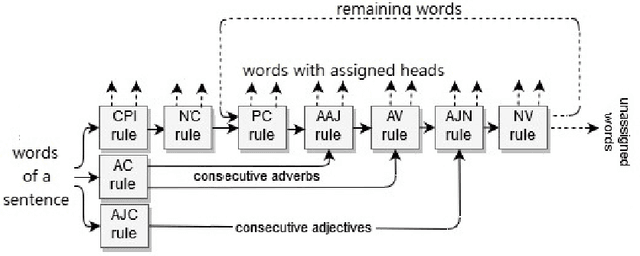



Fully data-driven, deep learning-based models are usually designed as language-independent and have been shown to be successful for many natural language processing tasks. However, when the studied language is low-resourced and the amount of training data is insufficient, these models can benefit from the integration of natural language grammar-based information. We propose two approaches to dependency parsing especially for languages with restricted amount of training data. Our first approach combines a state-of-the-art deep learning-based parser with a rule-based approach and the second one incorporates morphological information into the parser. In the rule-based approach, the parsing decisions made by the rules are encoded and concatenated with the vector representations of the input words as additional information to the deep network. The morphology-based approach proposes different methods to include the morphological structure of words into the parser network. Experiments are conducted on the IMST-UD Treebank and the results suggest that integration of explicit knowledge about the target language to a neural parser through a rule-based parsing system and morphological analysis leads to more accurate annotations and hence, increases the parsing performance in terms of attachment scores. The proposed methods are developed for Turkish, but can be adapted to other languages as well.