 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multitask Learning Approach for BERT
Oct 17, 2020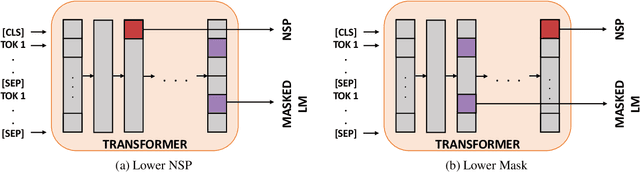
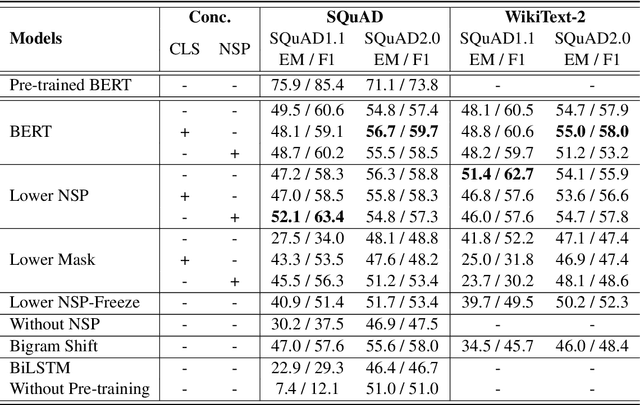
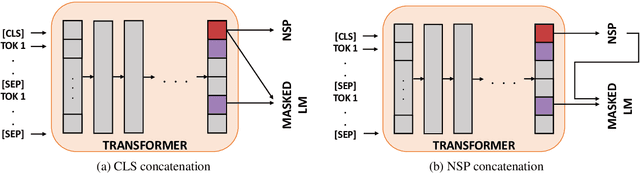
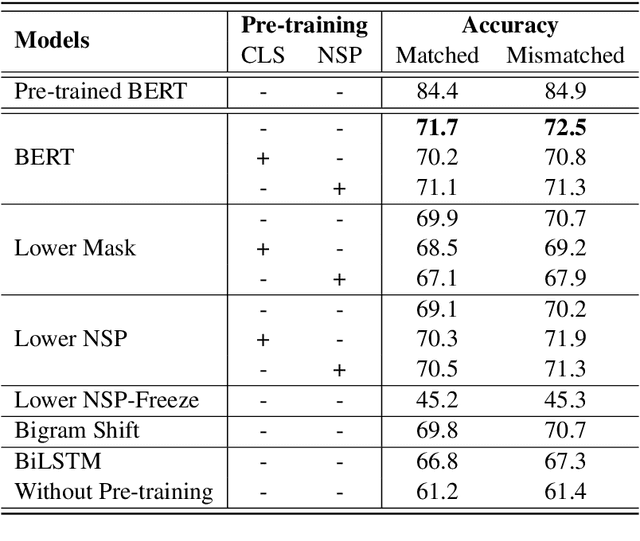
Recent works show that learning contextualized embeddings for words is beneficial for downstream tasks. BERT is one successful example of this approach. It learns embeddings by solving two tasks, which are masked language model (masked LM) and the next sentence prediction (NSP). The pre-training of BERT can also be framed as a multitask learning problem. In this work, we adopt hierarchical multitask learning approaches for BERT pre-training. Pre-training tasks are solved at different layers instead of the last layer, and information from the NSP task is transferred to the masked LM task. Also, we propose a new pre-training task bigram shift to encode word order information. We choose two downstream tasks, one of which requires sentence-level embeddings (textual entailment), and the other requires contextualized embeddings of words (question answering). Due to computational restrictions, we use the downstream task data instead of a large dataset for the pre-training to see the performance of proposed models when given a restricted dataset. We test their performance on several probing tasks to analyze learned embeddings. Our results show that imposing a task hierarchy in pre-training improves the performance of embeddings.
Hierarchical Mixtures of Generators for Adversarial Learning
Nov 05, 2019



Generative adversarial networks (GANs) are deep neural networks that allow us to sample from an arbitrary probability distribution without explicitly estimating the distribution. There is a generator that takes a latent vector as input and transforms it into a valid sample from the distribution. There is also a discriminator that is trained to discriminate such fake samples from true samples of the distribution; at the same time, the generator is trained to generate fakes that the discriminator cannot tell apart from the true samples. Instead of learning a global generator, a recent approach involves training multiple generators each responsible from one part of the distribution. In this work, we review such approaches and propose the hierarchical mixture of generators, inspired from the hierarchical mixture of experts model, that learns a tree structure implementing a hierarchical clustering with soft splits in the decision nodes and local generators in the leaves. Since the generators are combined softly, the whole model is continuous and can be trained using gradient-based optimization, just like the original GAN model. Our experiments on five image data sets, namely, MNIST, FashionMNIST, UTZap50K, Oxford Flowers, and CelebA, show that our proposed model generates samples of high quality and diversity in terms of popular GAN evaluation metrics. The learned hierarchical structure also leads to knowledge extraction.