 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multitask Learning Approach for BERT
Paper and Code
Oct 17, 2020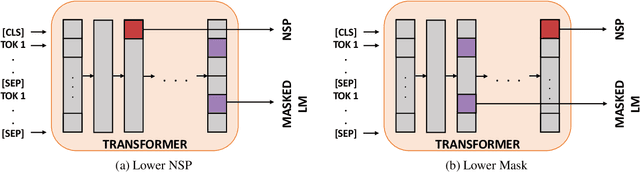
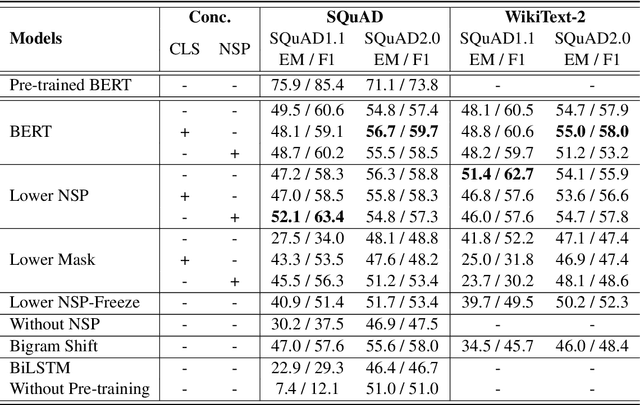
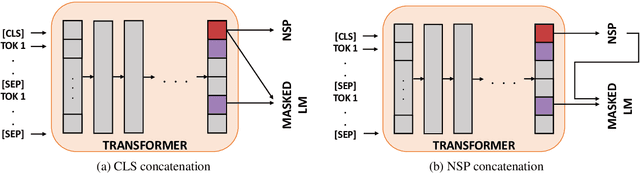
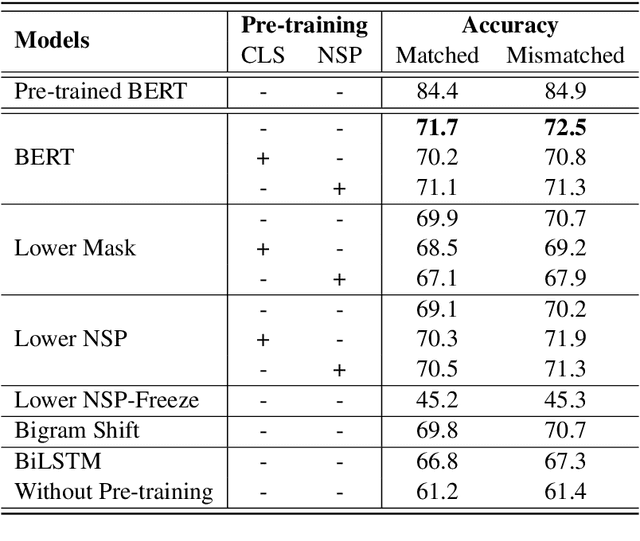
Recent works show that learning contextualized embeddings for words is beneficial for downstream tasks. BERT is one successful example of this approach. It learns embeddings by solving two tasks, which are masked language model (masked LM) and the next sentence prediction (NSP). The pre-training of BERT can also be framed as a multitask learning problem. In this work, we adopt hierarchical multitask learning approaches for BERT pre-training. Pre-training tasks are solved at different layers instead of the last layer, and information from the NSP task is transferred to the masked LM task. Also, we propose a new pre-training task bigram shift to encode word order information. We choose two downstream tasks, one of which requires sentence-level embeddings (textual entailment), and the other requires contextualized embeddings of words (question answering). Due to computational restrictions, we use the downstream task data instead of a large dataset for the pre-training to see the performance of proposed models when given a restricted dataset. We test their performance on several probing tasks to analyze learned embeddings. Our results show that imposing a task hierarchy in pre-training improves the performance of embeddings.