 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook the Other Way: Designing 'Positive' Molecules with Negative Data via Task Arithmetic
Jul 23, 2025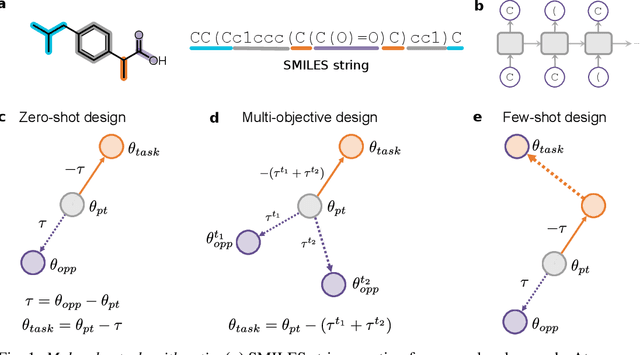
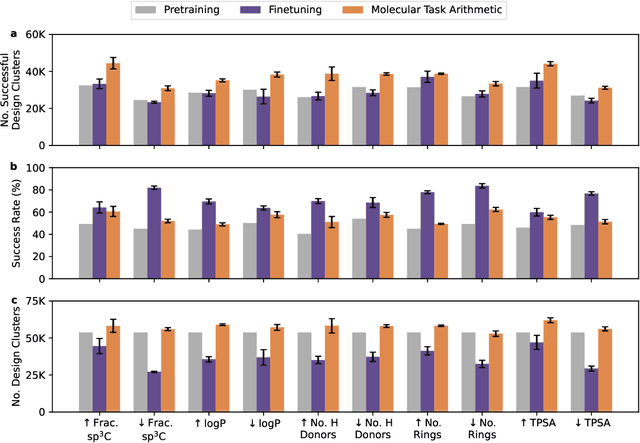
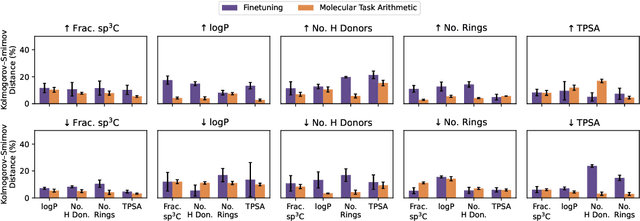
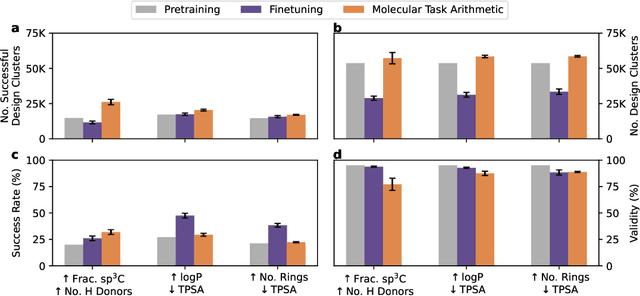
The scarcity of molecules with desirable properties (i.e., 'positive' molecules) is an inherent bottleneck for generative molecule design. To sidestep such obstacle, here we propose molecular task arithmetic: training a model on diverse and abundant negative examples to learn 'property directions' $--$ without accessing any positively labeled data $--$ and moving models in the opposite property directions to generate positive molecules. When analyzed on 20 zero-shot design experiments, molecular task arithmetic generated more diverse and successful designs than models trained on positive molecules. Moreover, we employed molecular task arithmetic in dual-objective and few-shot design tasks. We find that molecular task arithmetic can consistently increase the diversity of designs while maintaining desirable design properties. With its simplicity, data efficiency, and performance, molecular task arithmetic bears the potential to become the $\textit{de-facto}$ transfer learning strategy for de novo molecule design.
A Hitchhiker's Guide to Deep Chemical Language Processing for Bioactivity Prediction
Jul 16, 2024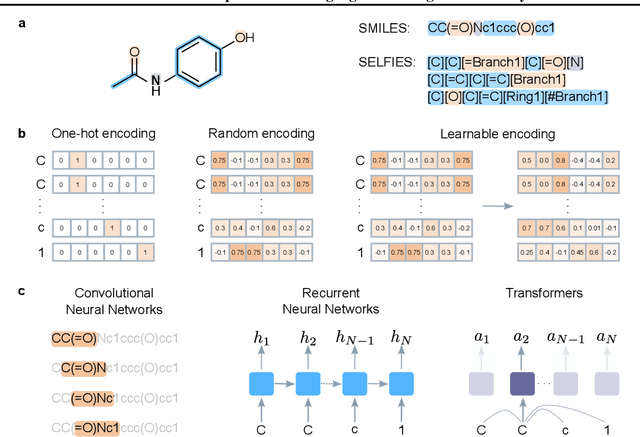
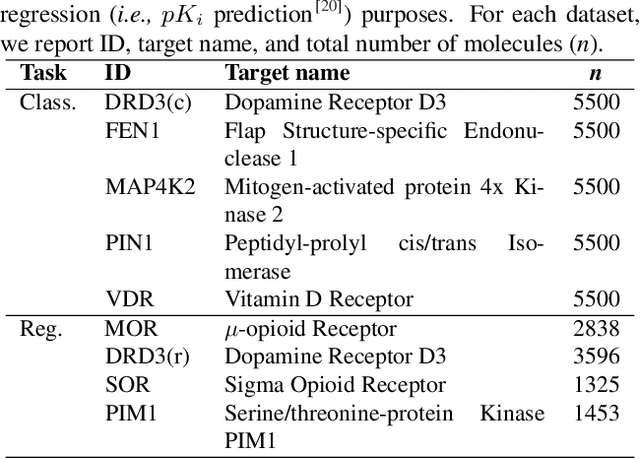

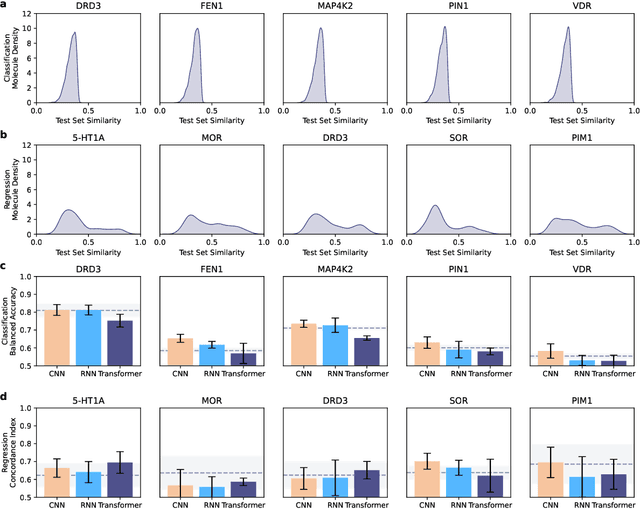
Deep learning has significantly accelerated drug discovery, with 'chemical language' processing (CLP) emerging as a prominent approach. CLP learns from molecular string representations (e.g., Simplified Molecular Input Line Entry Systems [SMILES] and Self-Referencing Embedded Strings [SELFIES]) with methods akin to natural language processing. Despite their growing importance, training predictive CLP models is far from trivial, as it involves many 'bells and whistles'. Here, we analyze the key elements of CLP training, to provide guidelines for newcomers and experts alike. Our study spans three neural network architectures, two string representations, three embedding strategies, across ten bioactivity datasets, for both classification and regression purposes. This 'hitchhiker's guide' not only underscores the importance of certain methodological choices, but it also equips researchers with practical recommendations on ideal choices, e.g., in terms of neural network architectures, molecular representations, and hyperparameter optimization.
Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Jan 07, 2024

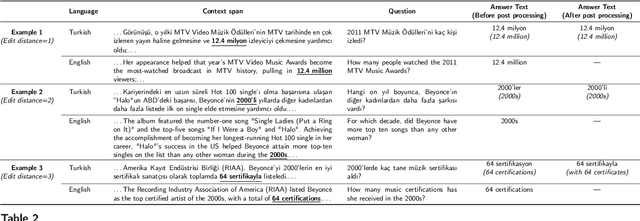

Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource languages. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA for Turkish. We obtain a performance improvement of 9-34% in the EM score and 13-33% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models by using two versions of Wikipedia dumps spanning two years. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available.
Structure-based drug discovery with deep learning
Dec 26, 2022Artificial intelligence (AI) in the form of deep learning bears promise for drug discovery and chemical biology, $\textit{e.g.}$, to predict protein structure and molecular bioactivity, plan organic synthesis, and design molecules $\textit{de novo}$. While most of the deep learning efforts in drug discovery have focused on ligand-based approaches, structure-based drug discovery has the potential to tackle unsolved challenges, such as affinity prediction for unexplored protein targets, binding-mechanism elucidation, and the rationalization of related chemical kinetic properties. Advances in deep learning methodologies and the availability of accurate predictions for protein tertiary structure advocate for a $\textit{renaissance}$ in structure-based approaches for drug discovery guided by AI. This review summarizes the most prominent algorithmic concepts in structure-based deep learning for drug discovery, and forecasts opportunities, applications, and challenges ahead.
DebiasedDTA: Model Debiasing to Boost Drug-Target Affinity Prediction
Jul 17, 2021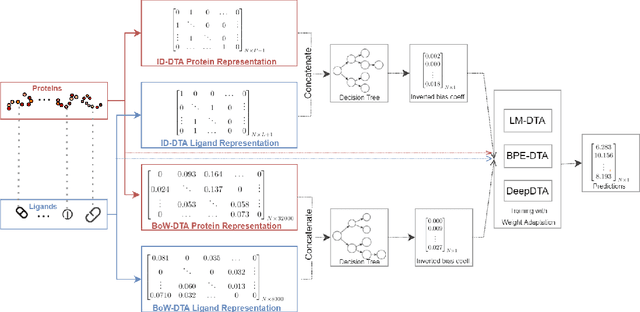



Motivation: Computational models that accurately identify high-affinity protein-compound pairs can accelerate drug discovery pipelines. These models aim to learn binding mechanics through drug-target interaction datasets and use the learned knowledge for predicting the affinity of an input protein-compound pair. However, the datasets they rely on bear misleading patterns that bias models towards memorizing dataset-specific biomolecule properties, instead of learning binding mechanics. This results in models that struggle while predicting drug-target affinities (DTA), especially between de novo biomolecules. Here we present DebiasedDTA, the first DTA model debiasing approach that avoids dataset biases in order to boost affinity prediction for novel biomolecules. DebiasedDTA uses ensemble learning and sample weight adaptation for bias identification and avoidance and is applicable to almost all existing DTA prediction models. Results: The results show that DebiasedDTA can boost models while predicting the interactions between novel biomolecules. Known biomolecules also benefit from the performance improvement, especially when the test biomolecules are dissimilar to the training set. The experiments also show that DebiasedDTA can augment DTA prediction models of different input and model structures and is able to avoid biases of different sources. Availability and Implementation: The source code, the models, and the datasets are freely available for download at https://github.com/boun-tabi/debiaseddta-reproduce, implementation in Python3, and supported for Linux, MacOS and MS Windows. Contact: arzucan.ozgur@boun.edu.tr, elif.ozkirimli@roche.com
Vapur: A Search Engine to Find Related Protein -- Compound Pairs in COVID-19 Literature
Sep 05, 2020Coronavirus Disease of 2019 (COVID-19) created dire consequences globally and triggered an enormous scientific effort from different domains. Resulting publications formed a gigantic domain-specific collection of text in which finding studies on a biomolecule of interest is quite challenging for general purpose search engines due to terminology-rich characteristics of the publications. Here, we present Vapur, an online COVID-19 search engine specifically designed for finding related protein - chemical pairs. Vapur is empowered with a biochemically related entities-oriented inverted index in order to group studies relevant to a biomolecule with respect to its related entities. The inverted index of Vapur is automatically created with a BioNLP pipeline and integrated with an online user interface. The online interface is designed for the smooth traversal of the current literature and is publicly available at https://tabilab.cmpe.boun.edu.tr/vapur/.
Use of Machine Translation to Obtain Labeled Datasets for Resource-Constrained Languages
May 01, 2020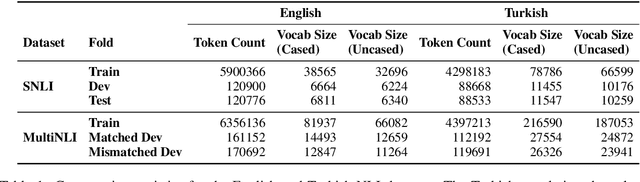
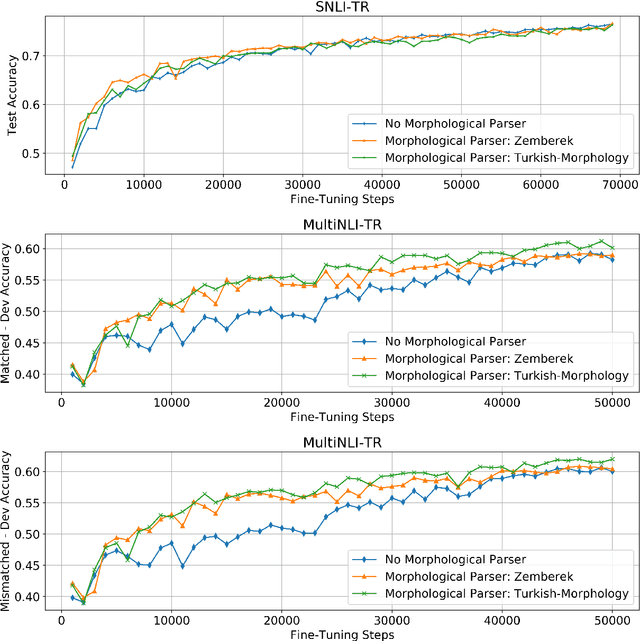
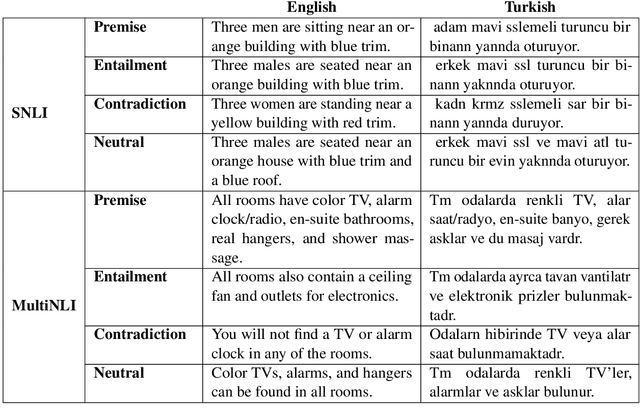
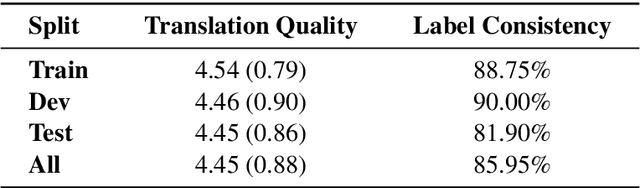
The large annotated datasets in NLP are overwhelmingly in English. This is an obstacle to progress for other languages. Unfortunately, obtaining new annotated resources for each task in each language would be prohibitively expensive. At the same time, commercial machine translation systems are now robust. Can we leverage these systems to translate English-language datasets automatically? In this paper, we offer a positive response to this for natural language inference (NLI) in Turkish. We translated two large English NLI datasets into Turkish and had a team of experts validate their quality. As examples of the new issues that these datasets help us address, we assess the value of Turkish-specific embeddings and the importance of morphological parsing for developing robust Turkish NLI models.