 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Efficient and Effective OpenQA Systems for Low-Resource Languages
Jan 07, 2024

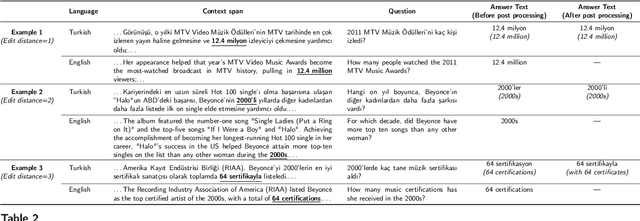

Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource languages. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA for Turkish. We obtain a performance improvement of 9-34% in the EM score and 13-33% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models by using two versions of Wikipedia dumps spanning two years. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available.
Use of Machine Translation to Obtain Labeled Datasets for Resource-Constrained Languages
May 01, 2020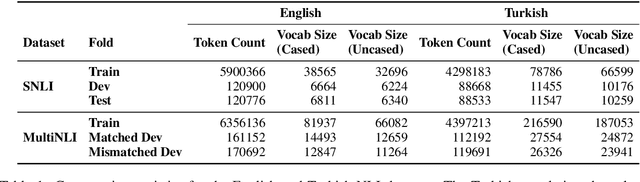
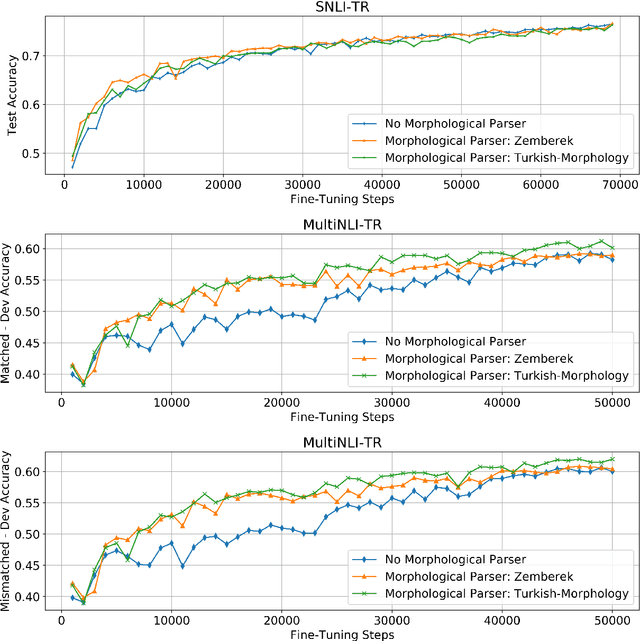
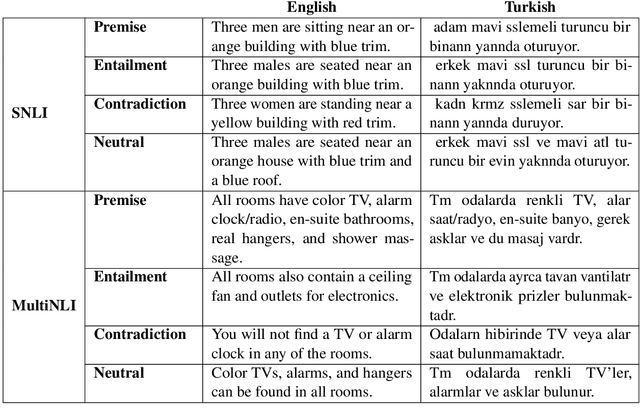
The large annotated datasets in NLP are overwhelmingly in English. This is an obstacle to progress for other languages. Unfortunately, obtaining new annotated resources for each task in each language would be prohibitively expensive. At the same time, commercial machine translation systems are now robust. Can we leverage these systems to translate English-language datasets automatically? In this paper, we offer a positive response to this for natural language inference (NLI) in Turkish. We translated two large English NLI datasets into Turkish and had a team of experts validate their quality. As examples of the new issues that these datasets help us address, we assess the value of Turkish-specific embeddings and the importance of morphological parsing for developing robust Turkish NLI models.
LIDE: Language Identification from Text Documents
Jan 13, 2017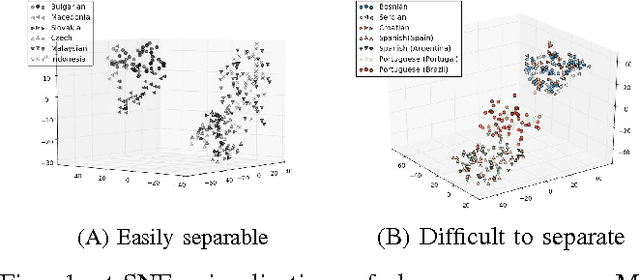
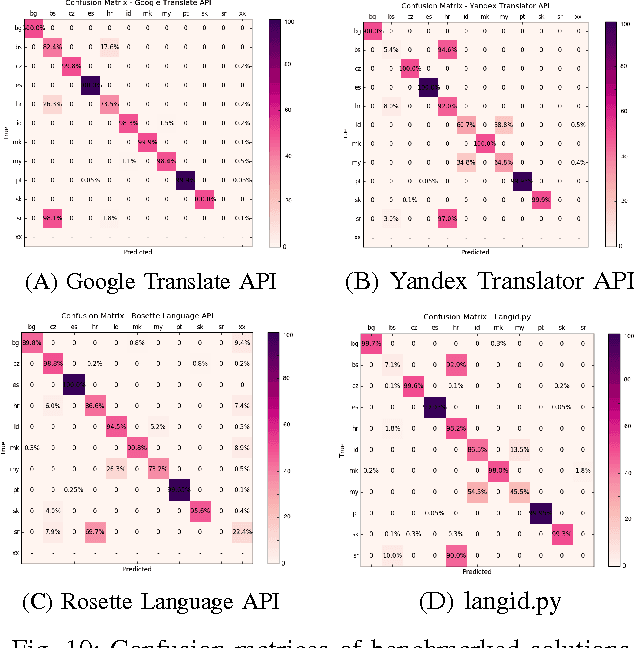

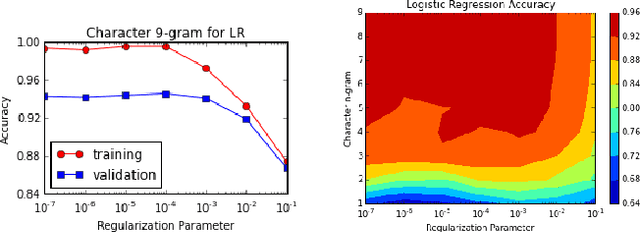
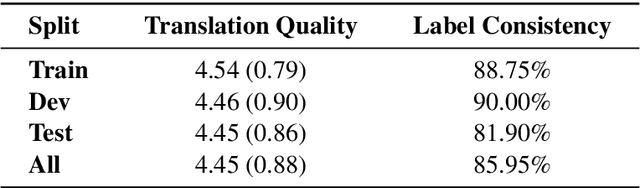
The increase in the use of microblogging came along with the rapid growth on short linguistic data. On the other hand deep learning is considered to be the new frontier to extract meaningful information out of large amount of raw data in an automated manner. In this study, we engaged these two emerging fields to come up with a robust language identifier on demand, namely Language Identification Engine (LIDE). As a result, we achieved 95.12% accuracy in Discriminating between Similar Languages (DSL) Shared Task 2015 dataset, which is comparable to the maximum reported accuracy of 95.54% achieved so far.
Scalable, Trie-based Approximate Entity Extraction for Real-Time Financial Transaction Screening
Jan 12, 2017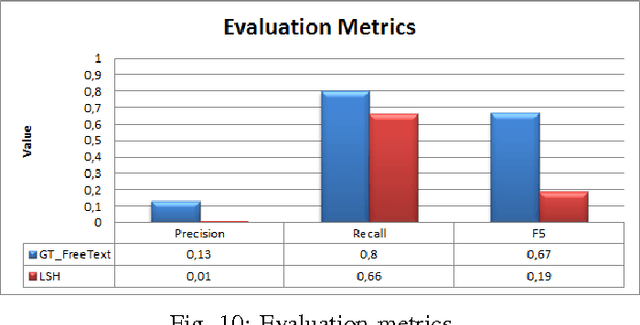
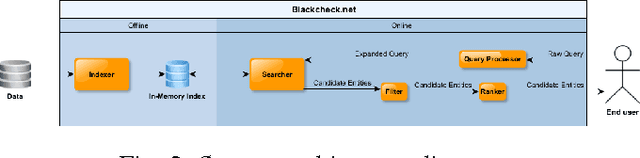
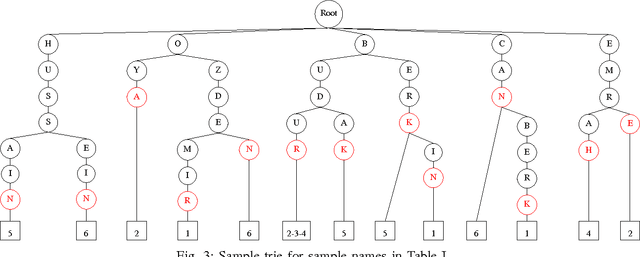
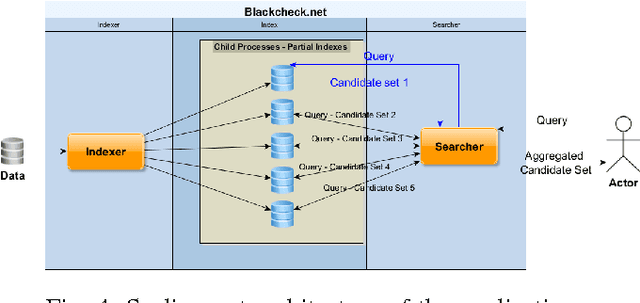
Financial institutions have to screen their transactions to ensure that they are not affiliated with terrorism entities. Developing appropriate solutions to detect such affiliations precisely while avoiding any kind of interruption to large amount of legitimate transactions is essential. In this paper, we present building blocks of a scalable solution that may help financial institutions to build their own software to extract terrorism entities out of both structured and unstructured financial messages in real time and with approximate similarity matching approach.